

{kind=link}
Not too long ago introduced Genie Code is Databricks’ autonomous AI companion function constructed for knowledge work. It changed Databricks Assistant, whereas it subsumed a number of brokers and supplied new integration factors and capabilities. Genie Code has deep integration with Unity Catalog, which means it understands your tables, columns, lineage, metrics views, and enterprise definitions (semantics). This contextual consciousness makes Genie Code way more helpful for knowledge practitioners than the generic chatbots.
When Genie Code generates a pocket book for conventional ML duties, comparable to “construct a churn prediction mannequin”, we count on it to yield a production-ready workflow that features set up of the suitable Python libraries, exploration and preprocessing of the info, coaching, tuning, registration and deployment of the mannequin, and analysis of how properly it performs. We additionally count on that every step is actually knowledgeable by the info: for instance, Genie Code shall perceive that imbalanced lessons in a binary classification downside end in dramatically totally different workflows and success metrics.
To make sure Genie Code persistently follows Databricks-native finest practices and avoids, for instance, skipping of cross-validation, failing to note knowledge leakage or improper knowledge imputation, we wanted a rigorous method to reply one query: How do we all know if the generated code is definitely any good? The generated pocket book will tremendously depend upon the issue the shopper is making an attempt to resolve, and this will differ vastly amongst totally different prospects, so it is a very non-trivial query.
On this publish, we’ll stroll by means of how we constructed an analysis pipeline for Genie Code’s conventional ML capabilities and the way we used MemAlign (a brand new open-source alignment framework in MLflow) to shut the huge hole we discovered between LLM judges and human specialists. The improved judges helped us establish and repair gaps in Genie Code’s ML steerage that we’d have in any other case missed.
Constructing the Analysis Framework
A sturdy analysis framework is required for:
- Hillclimbing: quantify how prompts, instruments, abilities and structure adjustments have an effect on output.
- Guarding in opposition to regressions: Make sure that enhancing “Mannequin Coaching” does not unintentionally degrade “Information Exploration.”
- Benchmarking: Measure how totally different basis fashions (LLM backends) influence pocket book high quality.
- CI: Monitor how adjustments within the underlying agentic loop ripple by means of to the ultimate ML duties.
Evaluating conventional ML notebooks is among the most complicated analysis duties because it spans analysis of code high quality, finest ML practices, and data-informed diversifications/tailoring. To deal with a job as broad and messy as evaluating ML notebooks, we use an LLM-as-a-judge – an LLM “skilled” taught by people what precisely a superb pocket book seems to be like. We created 9 judges that are prompted to judge the ML notebooks alongside 9 dimensions that seem in most ML workflows:
| Dimensions | What we grade |
|---|---|
| Library Set up | Correct dependencies |
| Exploratory Information Evaluation | Thorough EDA and |
| Information Imputation | Imply Time to Include |
| Dealing with lacking values with out leakage. | Characteristic Engineering |
| Characteristic choice/transformation. | Mannequin Coaching |
| Mannequin choice, Cross Validation, Hyperparameter tuning | Reusing the skilled mannequin to do inference. |
| Metrics Analysis | Inference logic and task-appropriate metrics (e.g., MAPE for forecasting, MAE for regression, Accuracy for classification). |
| MLflow Logging | Experiment monitoring setup. |
| Cell Group | Splitting the code into cells, code cleanliness, readability, markdown headers, applicable logging. |
For every dimension, we wrote scoring rubrics (reused between human raters and LLM judges) that assign a rating from 1 to three, and 0 for “not relevant”:
- 3 (Good): The pocket book meets a excessive bar for a dimension. It demonstrates finest practices, covers the anticipated scope, and handles edge instances appropriately.
- 2 (Common): Acceptable however with gaps. The fundamentals are current, however the pocket book misses refinements that an skilled practitioner would count on.
- 1 (Dangerous): Elementary issues. Key steps are lacking, incorrect, or utilized in a manner that might result in flawed conclusions.
- N/A (Not Relevant): This dimension isn’t relevant for this immediate (e.g. the dimension knowledge imputation can’t be utilized if the info set isn’t lacking any values).
To offer an thought of the granularity, right here is the precise rubric we use for the ”knowledge imputation” dimension:
Together with the judges, we keep a set of analysis take a look at instances that span a spread of ML duties (classification, regression, forecasting), throughout totally different dataset sizes, domains, and complexity ranges. Every take a look at case features a person immediate which tells Genie Code the ML job it’s supposed to resolve on the desired dataset (“I’ve passenger knowledge within the tables titanic_train_table and titanic_test_table. Can you determine who survived?”). The analysis loop consists of utilizing Genie Code to generate a pocket book (or a number of ones) for every take a look at case, after which scoring each pocket book alongside all relevant dimensions.
Evaluating the analysis system
Through the use of LLM judges, as an alternative of people, to judge Genie Code artifacts, we primarily swapped one troublesome downside for an additional: the out-of-box decide is unskilled on the duty at hand and misaligned with human rankings. Our downside assertion is to make the LLM judges rating align with these of human evaluators.
The analysis set for LLM-judge appraisal accommodates 50 Genie Code generated notebooks (“take a look at instances”) the place human specialists graded each relevant dimension, offering each a rating and a brief justification to function our floor fact. Within the gray areas between two scores, raters have been allowed to precise their very own judgement, however the schemas have been written in such a manner that that is hardly ever the case.
The measure of human-machine alignment is the imply absolute error (MAE) between scores in every dimension. The outcomes have been blended, some dimensions confirmed robust alignment (4 dimensions had a MAE of <= 0.10), whereas others revealed vital disagreement:
- Mannequin coaching: MAE of 0.680
- Mannequin use: MAE of 0.562
- Information imputation: MAE of 0.474
- Information exploration: MAE of 0.407
This hole exists as a result of people and LLMs don’t interpret the identical rubric the identical manner. Whereas a human rater can spot a subtly flawed imputation technique or a coaching loop that ‘works’ however is logically unsound, an LLM decide typically misses that technical nuance. We additionally discovered the decide suffered from a basic positivity bias – it was just too ‘well mannered’ and this received in the way in which of getting goal outcomes.
It turned abundantly clear that given the identical rubric, LLM judges and people wouldn’t produce the identical outcomes – a misalignment. That is precisely the state of affairs MemAlign was designed to repair.
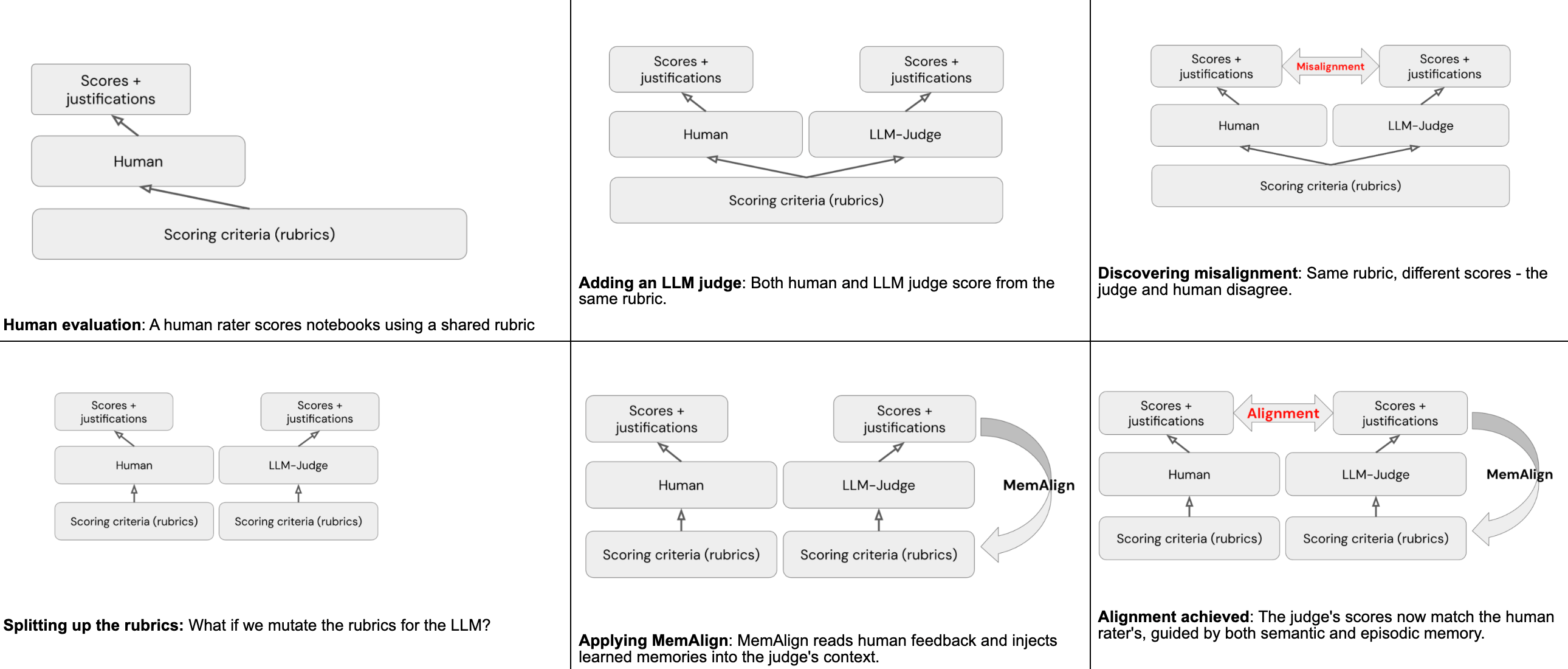
Utilizing MemAlign for alignment
MemAlign is a framework inside MLflow that may, given a really small quantity of human pure language suggestions, carry out alignment between the human raters and LLM judges. That is achieved by means of two varieties of “reminiscences” fashioned from studying the human suggestions:
- Semantic reminiscence shops generalized pointers – guidelines distilled from suggestions that apply broadly
- Episodic reminiscence shops particular examples – instances the place the decide received it flawed, preserved as anchors for future selections
At inference time, MemAlign constructs a working context by pulling all semantic pointers and retrieving essentially the most related episodic examples for the present enter. The decide masses all of those into its context, together with the unique rubric, and makes use of the gathered data to offer a extra correct rating to all future notebooks.
The important thing property that made MemAlign stand out is excessive efficiency utilizing solely a small variety of examples. It is because MemAlign successfully distills studying from wealthy studying indicators in pure language suggestions, and incorporates them into the dual-memory system.
Right here’s an instance of among the snippets of semantic reminiscence generated for the “knowledge imputation” dimension, filling within the gaps within the rubric we beforehand outlined by typically offering anchor factors, examples and counter-examples:
Furthermore, as talked about earlier, the semantic reminiscence mirrored within the immediate is complemented with related examples from the decide’s episodic reminiscence at scoring time, thus giving the decide much more context to be able to interpret the optimized directions.
Experiment Design
Okay-Fold Cross-Validation
Following the ML training-testing paradigm, we utilized Okay-fold cross-validation (Okay=4) on 50 take a look at instances (notebooks) due to this fact avoiding knowledge leakage and the necessity to label a separate take a look at set. For every fold we did the next:
- Coaching section: MemAlign aligned the decide utilizing traces from the opposite folds to get the decide.
- Analysis section: Evaluated the notebooks in fold i with decide.
Bootstrapping Confidence Intervals
To calculate the boldness intervals with out extra labeled knowledge, we generated 100 bootstrapped samples with substitute out of the unique 50. By repeating this 10,000 occasions and monitoring MAE between human and machine scores, we calculated the boldness intervals for human-machine alignment with a 95% CI defining a statistically vital change.
Implementation
The analysis pipeline is carried out as a single MLflow snippet that orchestrates the complete course of:
The MemAlign optimizer is ready to align LLM judges primarily based on the take a look at instances’ traces in simply a few traces of code. We used this new “aligned” decide to calculate the brand new MAE. Aligning a decide on a single dimension takes roughly 25 seconds per fold, so the alignment itself shouldn’t be a bottleneck.
Outcomes

Three out of 9 dimensions confirmed statistically vital enchancment:
- Mannequin coaching improved by 0.500 MAE (0.680 → 0.180), a 74% discount
- Mannequin use improved by 0.438 MAE (0.562 → 0.125), a 78% discount
- Information imputation improved by 0.421 MAE (0.474 → 0.053), an 89% discount
These 3 dimensions are amongst preliminary 4 dimensions that have been closely misaligned. A weak preliminary alignment is indicative of the LLMs and people having a basically totally different understanding of the shared rubrics, and the reminiscence injected from MemAlign appears to supply sufficient context to get them “on the identical web page”.
- Metrics analysis and MLflow logging have been already well-aligned (MAE < 0.10 initially), and their degradation shouldn’t be statistically vital (experiment noise)
- Information exploration confirmed a slight regression (-0.130), however not statistically vital given its confidence interval [-0.33, +0.09]. This dimension exhibited the best inter-grader variance, and this noise prevented MemAlign from enhancing (and may need even hampered it).
Semantic Reminiscence Solely Experiment
The twin-memory construction of MemAlign led us to query whether or not each of them are literally contributing to the decide alignment. Specifically, the episodic reminiscence is meant to assist the decide by giving a set of essentially the most related annotated notebooks as a reference level (using the closest neighbor search). However what if the retrieved notebooks (nearest neighbors) aren’t truly just like the present one – simply the least dissimilar? Loading these into the decide’s context would possibly muddy issues fairly than assist. The issue house we’re grading (ML notebooks) may be very broad, and we initially hypothesized {that a} set of fifty notebooks would merely not be sufficient to get a sufficiently dense set of reminiscences for the decide to recall.
With out episodic reminiscence, the image degrades considerably:
- Mannequin coaching nonetheless improves (+0.420), however the achieve is smaller than the +0.500 with full MemAlign, and the aligned MAE is 0.260 vs. 0.180.
- Mannequin use loses statistical significance fully – the development drops from +0.438 to +0.294, with the boldness interval now crossing zero.
- Information imputation goes from an 89% error discount to zero enchancment – the aligned MAE equals the unique MAE (0.455).
- MLflow logging and metrics analysis truly regress considerably. With out episodic examples to anchor the decide, the distilled pointers alone introduce noise into dimensions that have been already well-calibrated, pushing MLflow logging from 0.062 to 0.396 MAE.
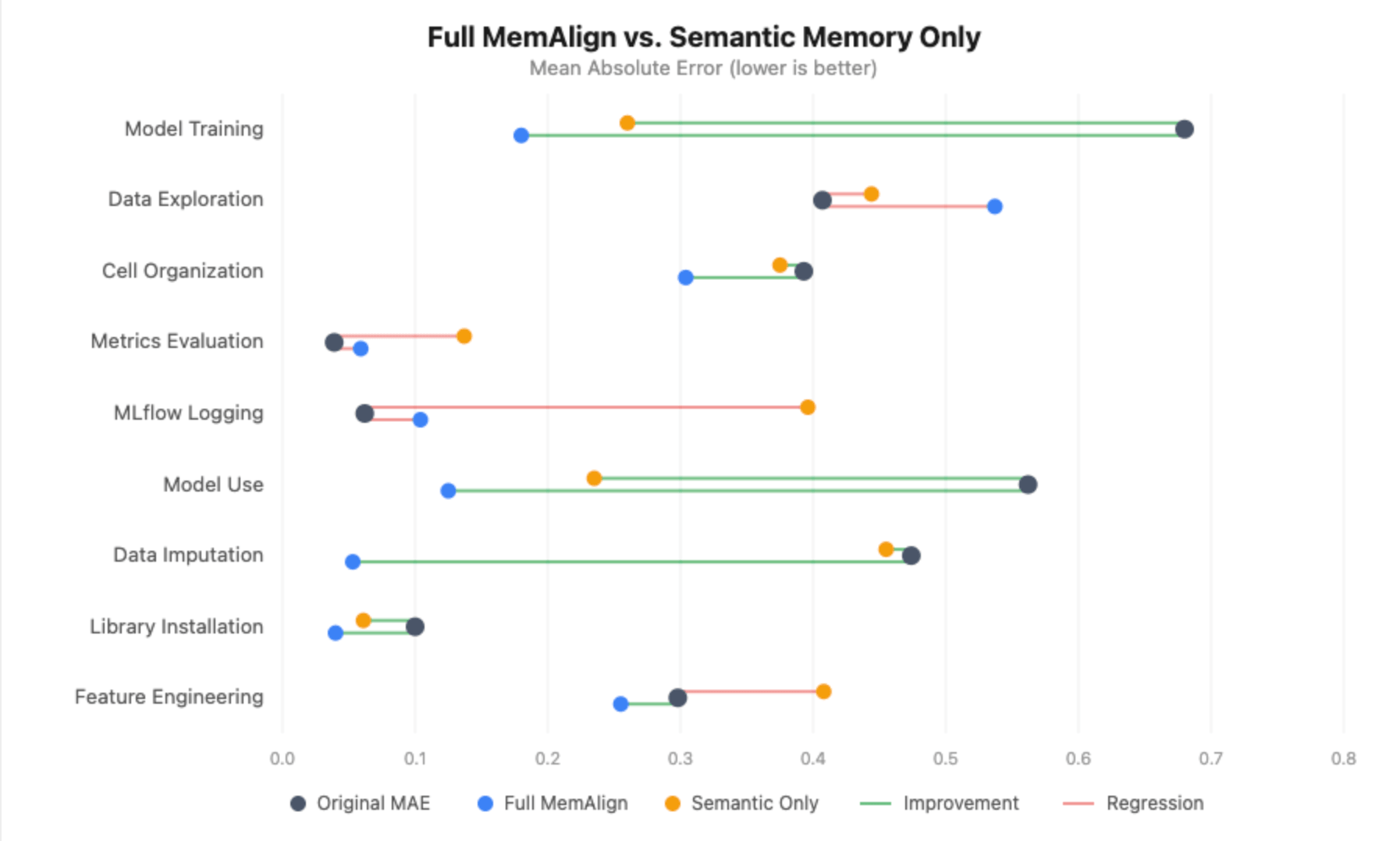
This was the alternative of what we anticipated. We initially hypothesized that our sparse annotated set would find yourself complicated the decide, however virtually each dimension received worse with out episodic reminiscence. The one exception was Information Exploration, the place dropping the episodic examples might have truly helped – with out the precise notebooks our annotators disagreed on, the decide solely had the distilled pointers, and fewer noisy sign to work with.
The takeaway: even when your inputs are giant and messy, episodic reminiscence nonetheless improves the decide’s efficiency drastically. Each semantic and episodic reminiscences are integral to the functioning of MemAlign.
Conclusion: Closing the Professional Hole
Judging whether or not a coding agent is doing its job is difficult sufficient, whereas evaluating an autonomous AI companion on constructing and executing conventional ML workflows is at one other stage of complexity. As a result of quick iteration on AI merchandise, there’s simply not sufficient time to have specialists monitor the agent’s “steady integration”. The one viable scalable resolution are LLM judges – however we nonetheless want a jury of people to maintain the LLM decide in test.
By making use of MemAlign, we reduce the decide error by 74–89% on the scale the place it mattered essentially the most. However, as with every ML/LLM work, the result’s solely nearly as good as the data you place in, so ensure that the labeling is competent.
Takeaways:
- Measure your measurement system: A loud system shouldn’t be good for analysis, and till we invested the time and sources to truly validate and enhance the judges, we couldn’t belief our analysis system.
- Rubrics aren’t sufficient on their very own: There are delicate variations between how a human perceives directions and the way an LLM perceives directions. These variations ought to be accounted for, and alignment tooling like MemAlign is an efficient method to bridge the hole.
- Labeling high quality > amount: When human annotators disagree with one another (as we noticed in our Information Exploration regression), alignment has no coherent sign to study from.
MemAlign ships with MLflow and it labored for us with simply ~50 labeled examples. In case your LLM judges aren’t matching your specialists, it is price a day.