

{kind=link}
Introduction
Throughout Sudan, communities rely upon groundwater for ingesting, irrigation and survival, however drilling a productive effectively is way from assured. The geology is complicated, aquifers fluctuate extensively and a failed borehole can price hundreds of {dollars}. A long time of geological surveys and subject studies include the info wanted to enhance outcomes, however this info has been scattered throughout archives and by no means systematically organized, making it invisible to the individuals who want it most.
MapAid is a nonprofit based at Stanford College whose mission is to empower humanitarian and improvement actors, primarily in Africa, to make data-driven choices via AI-enhanced mapping. Their flagship device, the WellMapr app (free to make use of), makes use of AI and geospatial information to determine shallow groundwater zones, guiding low-cost drilling for smallholder farmers’ ingesting water and irrigation. A crucial enter to those fashions is historic information on wells, boreholes, and aquifer geology.
The Sudan Affiliation for Archiving Information (SUDAAK) maintains one of many richest collections of this information: practically 700 scanned PDFs, TIFFs, and JPGs totaling over 5,000 pages of geological surveys, well-drilling studies, and subject research, publicly out there at wossac.com. Nonetheless, availability shouldn’t be the identical as accessibility. A researcher searching for borehole information in a selected a part of Sudan would wish to manually sift via a whole lot of paperwork. The information was digitized, however with no retrieval system, it remained untapped.
Classifying Scanned Paperwork with Multimodal AI
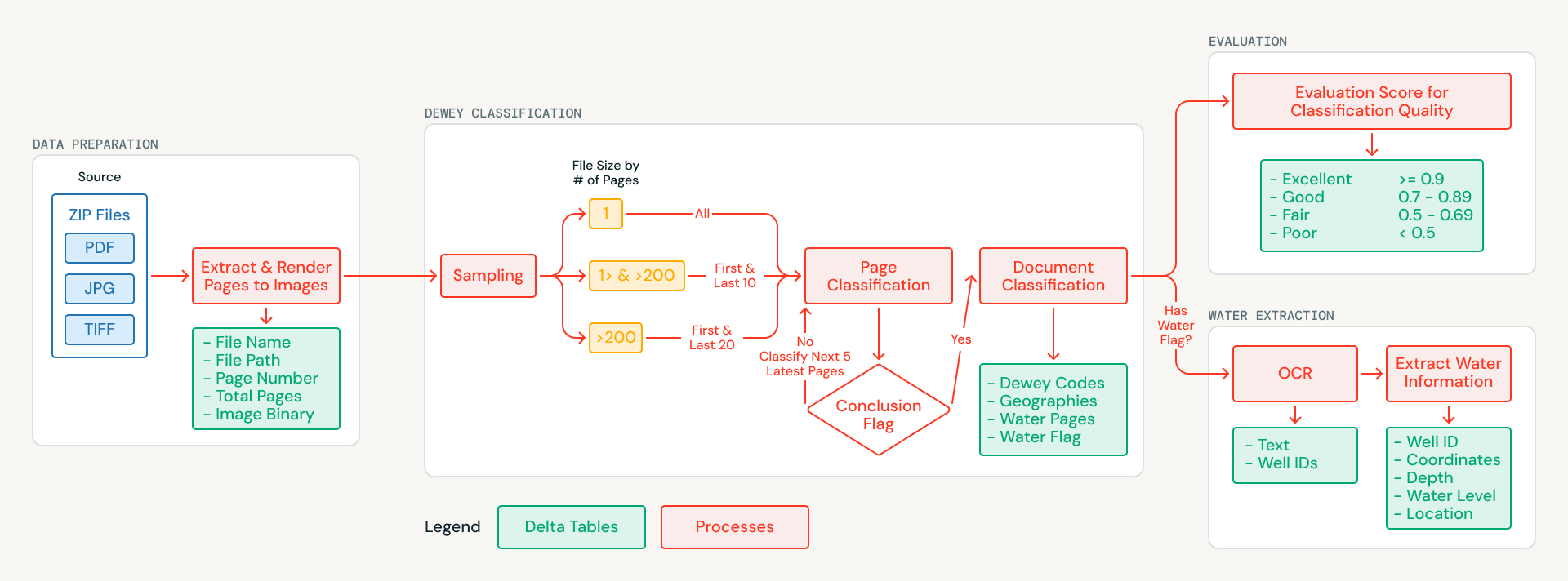
Databricks partnered with MapAid to construct an AI-powered pipeline that classifies each doc within the archive, tags it with geographic and topic metadata, and extracts structured effectively and borehole data from water-related paperwork. The system runs completely on Databricks and is packaged for single-command deployment. This text walks via the technical strategy and the way it generalizes to any group seeking to extract structured data from massive collections of unstructured scanned paperwork.
The archive introduced challenges that dominated out conventional textual content extraction. The paperwork are scans of bodily studies, many a long time outdated, with no embedded textual content layer. Some pages are skewed, others mix English and Arabic, and lots of embrace handwritten subject notes. Quite than trying OCR as a primary step, the staff reframed the issue as one among visible understanding: sending scanned web page pictures on to multimodal AI fashions that might interpret the content material visually.
Every doc’s pages are rendered as pictures and saved in Unity Catalog Volumes, making a clear, versioned foundational dataset. From there, an clever sampling technique reduces processing prices: shorter paperwork are analyzed in full, whereas longer paperwork are sampled from their most informative sections (title pages, introductions, and conclusions). This diminished AI processing quantity by greater than 70% whereas preserving classification high quality.
Every sampled web page is analyzed utilizing Databricks AI Capabilities (ai_query), which natively assist multimodal inputs and structured JSON output. The mannequin examines every web page picture and returns:
- Dewey Decimal classification codes, the common library classification system
- Sudanese geographies referenced within the content material
- A water-relevance flag indicating whether or not the web page incorporates effectively, borehole, or aquifer information
As a result of AI Capabilities run immediately inside SQL, the staff might iterate on prompts and output schemas with out constructing separate model-serving infrastructure. Web page-level outcomes are aggregated into document-level classifications, producing a structured, searchable catalog the place each doc is tagged with what it covers and the place it applies.
Extracting Structured Effectively and Borehole Data
Most of the water-flagged paperwork include precisely the kind of structured info that MapAid’s WellMapr fashions rely upon: effectively areas, drilling depths, water desk measurements, and yield charges. This info is commonly distributed all through a doc, with coordinates showing in a single part, depth measurements in one other, and yield information in a abstract desk a number of pages later. Extracting and linking this information was a central aim of the partnership.
For every water-relevant doc, the pipeline processes each web page relatively than simply the sampled subset used for classification. OCR is carried out web page by web page utilizing a multimodal mannequin served via the Basis Mannequin API, which handles English, Arabic, and complicated layouts together with handwritten subject notes, tabular information, and mixed-format pages. Throughout OCR, the system additionally applies an entity recognition strategy, figuring out effectively and borehole identifiers as anchor entities in order that data spanning a number of pages could be linked again to a single web site.
The extracted textual content from all pages is merged right into a unified doc illustration, which is then processed in a second go to extract structured data in JSON format capturing web site names, GPS coordinates, drilling depths, static water ranges, and pump check yields. Databricks AI Capabilities implement schema-constrained responses, making certain these attributes are captured constantly even after they seem in numerous codecs or sections throughout the doc. The result’s a set of structured effectively and borehole data prepared for direct integration into MapAid’s WellMapr prediction fashions.
Automated High quality Analysis at Scale
Manually validating a whole lot of specialised hydrogeological classifications would require vital sources and deep area experience. Quite than treating analysis as a separate step to be finished after the actual fact, the staff constructed automated high quality analysis immediately into the pipeline as a first-class stage. A separate AI mannequin, additionally known as by way of AI Capabilities, acts as a decide: scoring each classification on a structured rubric overlaying accuracy, completeness, and consistency. For every doc, the evaluator compares the assigned Dewey Decimal codes and geographic tags in opposition to the sampled web page content material, checking whether or not the classifications are supported by what the mannequin truly noticed.
Every analysis produces each a categorical score (wonderful, good, truthful, or poor) and a written justification explaining the rating, creating an auditable path for each resolution the pipeline makes. Paperwork scoring beneath a confidence threshold are flagged for handbook evaluation, directing restricted human effort to the instances the place it issues most. Within the first full run, solely a small fraction of classifications required human consideration.
Deploying a Self-Contained Answer on Databricks
A challenge like this touches each layer of the info and AI stack: file storage, information engineering, AI inference, structured output parsing, high quality analysis, and governance. Databricks offered all of those inside a single workspace. Uncooked archive information are saved in Unity Catalog Volumes, and all pipeline outputs are written to Delta Lake tables with ACID reliability, schema evolution, and full information lineage. The pipeline is orchestrated as a Lakeflow Job on serverless compute, so MapAid pays just for what every run consumes.
The whole system is packaged as a Databricks Asset Bundle, that means it may be deployed, up to date, and run with a single command. MapAid acquired a self-contained answer that may be maintained with out experience throughout a number of cloud companies. As a result of the pipeline logic is decoupled from the particular archive it processes, the identical system could possibly be tailored to different water archives, different areas, or different domains the place massive collections of scanned paperwork have to be categorised and made searchable.
What This Means on the Floor
In its first full run, the pipeline delivered:
- 654 paperwork and 5,570 pages categorised
- Accomplished in underneath three hours
- 95% of classifications rated “wonderful” or “good” by the automated evaluator
- ~50% of the archive recognized as containing water-related information
- 299 structured effectively and borehole data extracted with location names, depths, and yield measurements
The pipeline diminished what would have taken area consultants weeks or months right into a course of that completes in hours. The archive can now be searched by classification, geography, or the presence of water information. Each extracted document with coordinates and depth information feeds immediately into MapAid’s groundwater predictions, supporting increased drilling success charges and sooner supply of water to communities in want.
As SUDAAK continues to digitize new paperwork, the pipeline can course of every new batch with a single command, making certain the catalog stays present because the archive grows. MapAid’s work spans East Africa, together with Ethiopia and Malawi, and related unclassified archives exist throughout the continent. The methodology and infrastructure are able to scale.
Rupert Douglas-Bate, Chief Govt Officer (CEO) of MapAid, shared the next perspective on the partnership: “Our evolving AI system, WellMapr, is meant to revolutionise the low-cost search and site of sustainable groundwater sources, nevertheless it wants effectively water information. Our mission to realize that aim was enormously accelerated by our collaboration with Databricks for Good, who linked with us via Rotary Worldwide. The Databricks for Good challenge was elementary in growing our On-line Water Library (OWL) with the assist of the Sudan Affiliation for Archiving Information (SUDAAK). The Databricks staff helped remodel a big disorganised archive of historic Sudanese water and soil information right into a structured system utilizing the Dewey Decimal classification. This enables us to quickly determine sustainable groundwater effectively information at a low price, which may now be used to assist develop our WellMapr algorithm. MapAid is delighted to make use of OWL as a significant improvement device to mitigate drought, proving that when the proper companions align, we will obtain the ‘unimaginable’ for many who want it most.”
Please learn extra about a few of our different professional bono initiatives beneath: