

{kind=link}

At a look
- LLM-based fashions can predict the human mind’s responses to language with excessive accuracy. However what drives that efficiency is actually unreadable: an unlimited assortment of realized parameters, not scientific theories anybody can learn.
- Generative causal testing (GCT), developed in a collaboration between Microsoft Analysis, the College of California, Berkeley, the College of California, San Francisco, and Columbia College, distills these brain-prediction fashions into brief verbal explanations of what every patch of cortex responds to: phrases like “meals preparation” or “location names.”
- GCT then closes the loop: an LLM writes new tales designed to activate a focused mind space, topics hear them within the scanner, and the area lights up provided that the reason is correct.
- In experiments, GCT confirmed identified selectivity, teased aside neighboring place-processing areas lengthy thought interchangeable, and revealed tiny prefrontal “micro-regions” tuned to particular ideas like dialogue, clock occasions, and measurements.
The explainability drawback in language neuroscience
Over the previous decade, LLMs have develop into essentially the most correct instruments now we have for predicting how the human mind responds to language. Feed an LLM the identical story an individual hears in an fMRI scanner, and the mannequin’s inner representations can predict the exercise of particular person patches of cortex with exceptional constancy. However this success comes with a catch: no person can learn these fashions. They’re thousands and thousands of inscrutable parameters that may’t be instantly translated into interpretations. A mannequin that predicts mind exercise tells us {that a} area responds to language, however not what it’s really choosing up on, whether or not it’s meals, locations, numbers, or one thing else fully. As black-box fashions unfold, the hole between prediction and understanding has develop into one of many central issues in computational neuroscience.
Turning black bins into testable theories
In a new paper accepted in Nature Neuroscience, Microsoft Analysis scientists, in collaboration with scientists on the College of California, Berkeley, College of California, San Francisco, and Columbia College, introduce a framework to beat this explainability disaster: generative causal testing (GCT). GCT distills brain-prediction fashions into brief, readable accounts of what every patch of cortex responds to, then checks these claims. An LLM writes new tales engineered to activate a particular mind space, topics hear them within the scanner, and if the reason is right, the focused area lights up. The end result is a technique that interprets uninterpretable predictive fashions again into the foreign money of science: concise hypotheses that may be confirmed or refuted in a follow-up experiment. An LLM writes new tales engineered to activate a particular mind space, topics hear them within the scanner, and if the reason is right, the focused area lights up. The end result is a technique that interprets uninterpretable predictive fashions again into the foreign money of science: concise hypotheses that may be confirmed or refuted in a follow-up experiment.
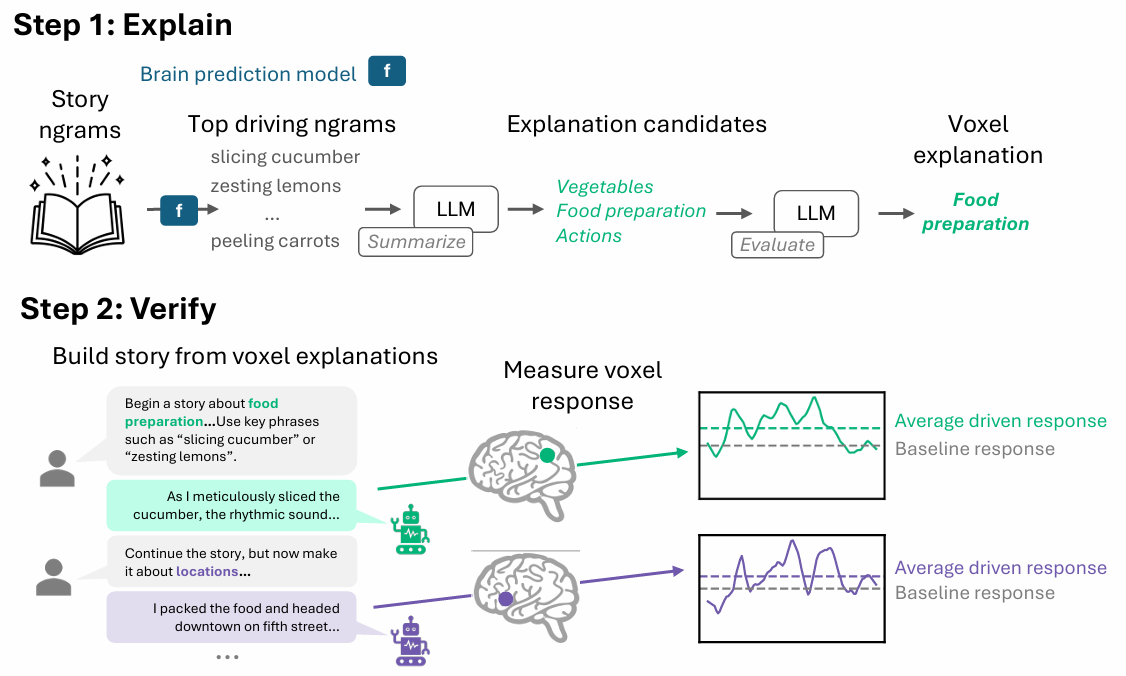
How GCT works
GCT has two steps: rationalization, then verification. To generate an evidence, the strategy begins from a predictive mannequin for a single voxel or area and identifies the brief phrases that almost all strongly drive its predicted response. An LLM then summarizes these phrases right into a concise verbal rationalization, usually a single phrase akin to “meals preparation” or “location names.”
The essential second stage closes the loop. To construct belief within the rationalization, GCT makes use of an LLM to write down new tales wherein every paragraph is fastidiously constructed to drive a mind area in accordance with its rationalization. Three topics returned to the scanner to learn these artificial tales. If a area’s exercise to its “driving” paragraphs was considerably higher than to baseline textual content, the reason handed a real causal check, not only a correlational one.
Throughout all three topics, the core strategy held up: the artificial tales reliably drove their goal areas above baseline, confirming that GCT’s brief explanations seize one thing the cortex genuinely responds to. The reasons had been additionally most reliable the place the underlying brain-prediction fashions had been strongest (the extra secure the mannequin, the extra reliably its rationalization might be confirmed within the scanner). With the strategy validated on areas whose selectivity was already identified, the researchers turned GCT on tougher questions.

GCT additionally proved sharp sufficient to settle long-standing ambiguities. Three neighboring areas concerned in processing locations have usually been handled as functionally related: the retrosplenial cortex (RSC), the parahippocampal place space (PPA), and the occipital place space (OPA). At first, tales written for one area additionally activated the others. However by producing differential stimuli (tales designed to modify one area on whereas holding its neighbors quiet), GCT teased the three aside. For instance, RSC responds extra strongly to correct noun location names, like Tokyo or Connecticut, reasonably than normal location. That is the sort of nuanced, region-specific principle {that a} uncooked predictive mannequin can not present by itself.
Past identified areas, the authors found new prefrontal “micro-regions.” By scanning a grid of candidate places and holding solely essentially the most secure ones, GCT surfaced these beforehand unmapped areas tuned to remarkably particular ideas: one selective for dialogue between folks (phrases like “mentioned” or “instructed”), one for mentions of clock occasions (“one o’clock”), and one for numeric measurements (“50 ft”). These are distinctions nobody had gone in search of; they emerged as a result of the strategy may suggest a speculation and instantly check it.
Highlight: Occasion Sequence
Microsoft Analysis Discussion board
Be a part of us for a steady trade of concepts about analysis within the period of normal AI. Watch the most recent episodes on demand.
Implications and searching ahead
The importance of GCT reaches properly past neuroscience. Researchers more and more face the identical dilemma: a mannequin that predicts fantastically however explains nothing. GCT reveals {that a} data-driven mannequin needn’t be the tip of inquiry; it may be distilled right into a readable, experimentally testable principle, and that principle may be checked towards actuality by producing new experiments on demand.
For neuroscience particularly, GCT factors towards a quicker, extra hypothesis-rich means of mapping the cortex—one the place an AI system proposes what a mind area would possibly encode and a closed-loop experiment confirms or rejects it inside a single research. The identical generate-and-verify philosophy may lengthen to different domains the place highly effective predictive fashions have outrun our means to grasp them. The broader lesson is hopeful: the rise of black-box fashions in science doesn’t essentially imply the retreat of human-readable principle. With the appropriate framework, the 2 can advance collectively.
Acknowledgements
This work was a collaboration throughout Microsoft Analysis, UC Berkeley (Alex Huth, Bin Yu, Sihang Guo, and Aliyah Hsu), Columbia College (RJ Antonello, co-lead), and UCSF (Shailee Jain). We additionally thank the research contributors and the broader language-neuroscience group whose instruments and datasets made this analysis potential.
Learn the paper (opens in new tab): “Generative causal testing to bridge data-driven fashions and scientific theories in language neuroscience,” accepted in Nature Neuroscience and the code on Github (opens in new tab).