

{kind=link}
On this article, you’ll discover ways to construct an area, privacy-first tool-calling agent utilizing the Gemma 4 mannequin household and Ollama.
Matters we are going to cowl embrace:
- An outline of the Gemma 4 mannequin household and its capabilities.
- How device calling allows language fashions to work together with exterior capabilities.
- The right way to implement an area device calling system utilizing Python and Ollama.

The right way to Implement Device Calling with Gemma 4 and Python
Picture by Editor
Introducing the Gemma 4 Household
The open-weights mannequin ecosystem shifted lately with the discharge of the Gemma 4 mannequin household. Constructed by Google, the Gemma 4 variants had been created with the intention of offering frontier-level capabilities underneath a permissive Apache 2.0 license, enabling machine studying practitioners full management over their infrastructure and knowledge privateness.
The Gemma 4 launch options fashions starting from the parameter-dense 31B and structurally complicated 26B Combination of Consultants (MoE) to light-weight, edge-focused variants. Extra importantly for AI engineers, the mannequin household options native assist for agentic workflows. They’ve been fine-tuned to reliably generate structured JSON outputs and natively invoke perform calls based mostly on system directions. This transforms them from “fingers crossed” reasoning engines into sensible techniques able to executing workflows and conversing with exterior APIs regionally.
Device Calling in Language Fashions
Language fashions started life as closed-loop conversationalists. For those who requested a language mannequin for real-world sensor studying or dwell market charges, it may at finest apologize, and at worst, hallucinate a solution. Device calling, aka perform calling, is the foundational structure shift required to repair this hole.
Device calling serves because the bridge that may assist rework static fashions into dynamic autonomous brokers. When device calling is enabled, the mannequin evaluates a person immediate towards a supplied registry of obtainable programmatic instruments (equipped through JSON schema). Relatively than making an attempt to guess the reply utilizing solely inner weights, the mannequin pauses inference, codecs a structured request particularly designed to set off an exterior perform, and awaits the end result. As soon as the result’s processed by the host utility and handed again to the mannequin, the mannequin synthesizes the injected dwell context to formulate a grounded remaining response.
The Setup: Ollama and Gemma 4:E2B
To construct a genuinely native, private-first device calling system, we are going to use Ollama as our native inference runner, paired with the gemma4:e2b (Edge 2 billion parameter) mannequin.
The gemma4:e2b mannequin is constructed particularly for cellular units and IoT functions. It represents a paradigm shift in what is feasible on shopper {hardware}, activating an efficient 2 billion parameter footprint throughout inference. This optimization preserves system reminiscence whereas attaining near-zero latency execution. By executing totally offline, it removes price limits and API prices whereas preserving strict knowledge privateness.
Regardless of this extremely small measurement, Google has engineered gemma4:e2b to inherit the multimodal properties and native function-calling capabilities of the bigger 31B mannequin, making it a perfect basis for a quick, responsive desktop agent. It additionally permits us to check for the capabilities of the brand new mannequin household with out requiring a GPU.
The Code: Setting Up the Agent
To orchestrate the language mannequin and the device interfaces, we are going to depend on a zero-dependency philosophy for our implementation, leveraging solely normal Python libraries like urllib and json, guaranteeing most portability and transparency whereas additionally avoiding bloat.
The entire code for this tutorial could be discovered at this GitHub repository.
The architectural circulation of our utility operates within the following approach:
- Outline native Python capabilities that act as our instruments
- Outline a strict JSON schema that explains to the language mannequin precisely what these instruments do and what parameters they anticipate
- Go the person’s question and the device registry to the native Ollama API
- Catch the mannequin’s response, determine if it requested a device name, execute the corresponding native code, and feed the reply again
Constructing the Instruments: get_current_weather
Let’s dive into the code, retaining in thoughts that our agent’s functionality rests on the standard of its underlying capabilities. Our first perform is get_current_weather, which reaches out to the open-source Open-Meteo API to resolve real-time climate knowledge for a particular location.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
def get_current_weather(metropolis: str, unit: str = “celsius”) -> str: “”“Will get the present temperature for a given metropolis utilizing open-meteo API.”“” attempt: # Geocode the town to get latitude and longitude geo_url = f“https://geocoding-api.open-meteo.com/v1/search?title={urllib.parse.quote(metropolis)}&depend=1” geo_req = urllib.request.Request(geo_url, headers={‘Consumer-Agent’: ‘Gemma4ToolCalling/1.0’}) with urllib.request.urlopen(geo_req) as response: geo_data = json.masses(response.learn().decode(‘utf-8’))
if “outcomes” not in geo_data or not geo_data[“results”]: return f“Couldn’t discover coordinates for metropolis: {metropolis}.”
location = geo_data[“results”][0] lat = location[“latitude”] lon = location[“longitude”] nation = location.get(“nation”, “”)
# Fetch the climate temp_unit = “fahrenheit” if unit.decrease() == “fahrenheit” else “celsius” weather_url = f“https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}&present=temperature_2m,wind_speed_10m&temperature_unit={temp_unit}” weather_req = urllib.request.Request(weather_url, headers={‘Consumer-Agent’: ‘Gemma4ToolCalling/1.0’}) with urllib.request.urlopen(weather_req) as response: weather_data = json.masses(response.learn().decode(‘utf-8’))
if “present” in weather_data: present = weather_data[“current”] temp = present[“temperature_2m”] wind = present[“wind_speed_10m”] temp_unit_str = weather_data[“current_units”][“temperature_2m”] wind_unit_str = weather_data[“current_units”][“wind_speed_10m”]
return f“The present climate in {metropolis.title()} ({nation}) is {temp}{temp_unit_str} with wind speeds of {wind}{wind_unit_str}.” else: return f“Climate knowledge for {metropolis} is unavailable from the API.”
besides Exception as e: return f“Error fetching climate for {metropolis}: {e}” |
This Python perform implements a two-stage API decision sample. As a result of normal climate APIs sometimes require strict geographical coordinates, our perform transparently intercepts the town string supplied by the mannequin and geocodes it into latitude and longitude coordinates. With the coordinates formatted, it invokes the climate forecast endpoint and constructs a concise pure language string representing the telemetry level.
Nonetheless, writing the perform in Python is simply half the execution. The mannequin must be knowledgeable visually about this device. We do that by mapping the Python perform into an Ollama-compliant JSON schema dictionary:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ “kind”: “perform”, “perform”: { “title”: “get_current_weather”, “description”: “Will get the present temperature for a given metropolis.”, “parameters”: { “kind”: “object”, “properties”: { “metropolis”: { “kind”: “string”, “description”: “The town title, e.g. Tokyo” }, “unit”: { “kind”: “string”, “enum”: [“celsius”, “fahrenheit”] } }, “required”: [“city”] } } } |
This inflexible structural blueprint is crucial, because it explicitly particulars variable expectations, strict string enums, and required parameters, all of which information the gemma4:e2b weights into reliably producing syntax-perfect calls.
Device Calling Below the Hood
The core of the autonomous workflow occurs primarily inside the principle loop orchestrator. As soon as a person points a immediate, we set up the preliminary JSON payload for the Ollama API, explicitly linking gemma4:e2b and appending the worldwide array containing our parsed toolkit.
|
# Preliminary payload to the mannequin messages = [{“role”: “user”, “content”: user_query}] payload = { “mannequin”: “gemma4:e2b”, “messages”: messages, “instruments”: available_tools, “stream”: False }
attempt: response_data = call_ollama(payload) besides Exception as e: print(f“Error calling Ollama API: {e}”) return
message = response_data.get(“message”, {}) |
As soon as the preliminary net request resolves, it’s crucial that we consider the structure of the returned message block. We’re not blindly assuming textual content exists right here. The mannequin, conscious of the energetic instruments, will sign its desired consequence by attaching a tool_calls dictionary.
If tool_calls exist, we pause the usual synthesis workflow, parse the requested perform title out of the dictionary block, execute the Python device with the parsed kwargs dynamically, and inject the returned dwell knowledge again into the conversational array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# Examine if the mannequin determined to name instruments if “tool_calls” in message and message[“tool_calls”]:
# Add the mannequin’s device calls to the chat historical past messages.append(message)
# Execute every device name num_tools = len(message[“tool_calls”]) for i, tool_call in enumerate(message[“tool_calls”]): function_name = tool_call[“function”][“name”] arguments = tool_call[“function”][“arguments”]
if function_name in TOOL_FUNCTIONS: func = TOOL_FUNCTIONS[function_name] attempt: # Execute the underlying Python perform end result = func(**arguments)
# Add the device response to messages historical past messages.append({ “position”: “device”, “content material”: str(end result), “title”: perform_title }) besides TypeError as e: print(f“Error calling perform: {e}”) else: print(f“Unknown perform: {function_name}”)
# Ship the device outcomes again to the mannequin to get the ultimate reply payload[“messages”] = messages
attempt: final_response_data = call_ollama(payload) print(“[RESPONSE]”) print(final_response_data.get(“message”, {}).get(“content material”, “”)+“n”) besides Exception as e: print(f“Error calling Ollama API for remaining response: {e}”) |
Discover the necessary secondary interplay: as soon as the dynamic result’s appended as a “device” position, we bundle the messages historical past up a second time and set off the API once more. This second go is what permits the gemma4:e2b reasoning engine to learn the telemetry strings it beforehand hallucinated round, bridging the ultimate hole to output the info logically in human phrases.
Extra Instruments: Increasing the Device Calling Capabilities
With the architectural basis full, enriching our capabilities requires nothing greater than including modular Python capabilities. Utilizing the similar methodology described above, we incorporate three further dwell instruments:
get_current_news: Using NewsAPI endpoints, this perform parses arrays of worldwide headlines based mostly on queried key phrase matters that the mannequin identifies as contextually relatedget_current_time: By referencing TimeAPI.io, this deterministic perform bridges complicated real-world timezone logic and offsets again into native, readable datetime stringsconvert_currency: Counting on the dwell ExchangeRate-API, this perform allows mathematical monitoring and fractional conversion computations between fiat currencies
Every functionality is processed by the JSON schema registry, increasing the baseline mannequin’s utility with out requiring exterior orchestration or heavy dependencies.
Testing the Instruments
And now we check our device calling.
Let’s begin with the primary perform we created, get_current_weather, with the next question:
What’s the climate in Ottawa?
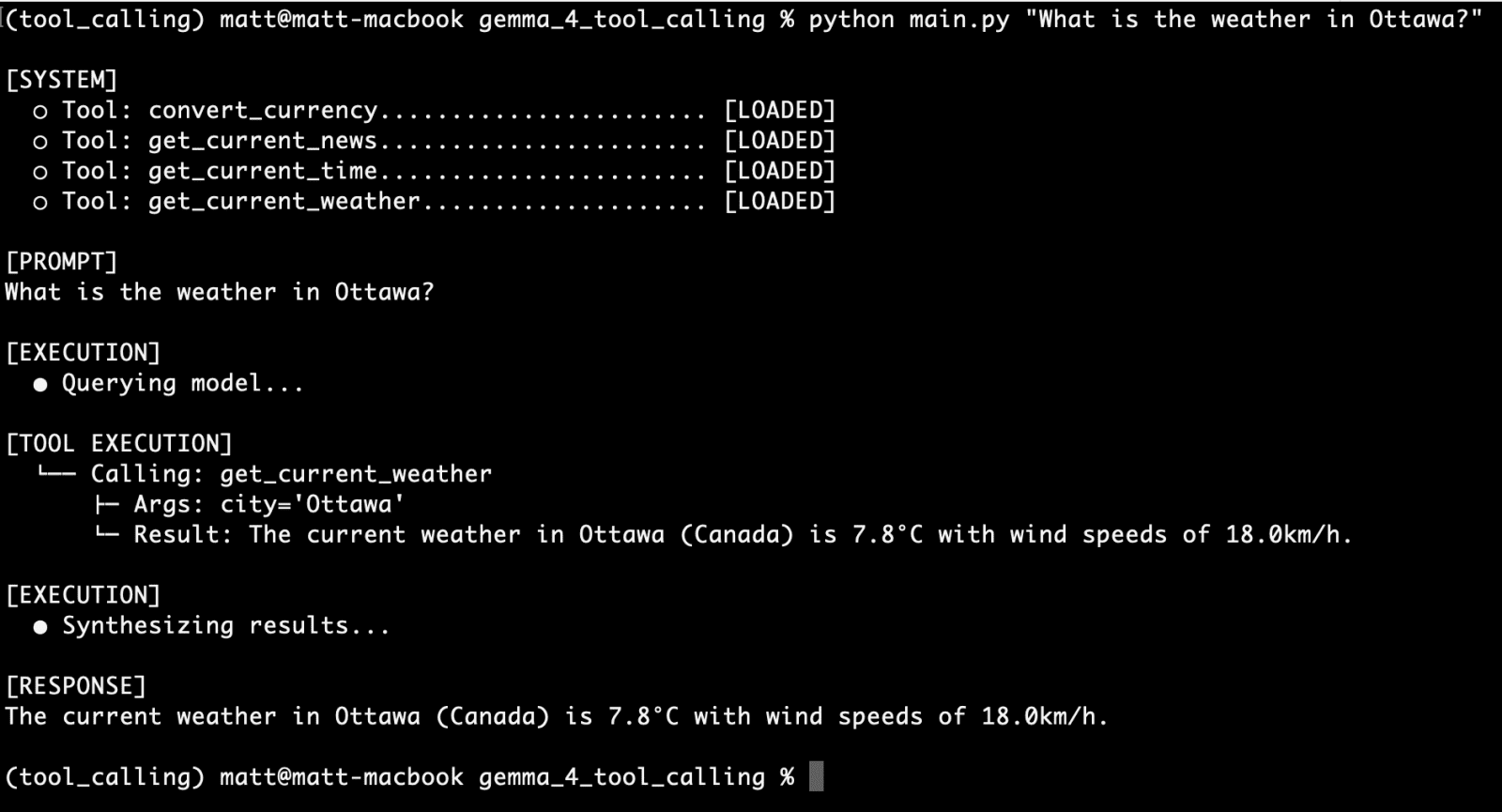
What’s the climate in Ottawa?
You may see our CLI UI supplies us with:
- affirmation of the accessible instruments
- the person immediate
- particulars on device execution, together with the perform used, the arguments despatched, and the response
- the the language mannequin’s response
It seems as if we now have a profitable first run.
Subsequent, let’s check out one other of our instruments independently, specifically convert_currency:
Given the present forex change price, how a lot is 1200 Canadian {dollars} in euros?
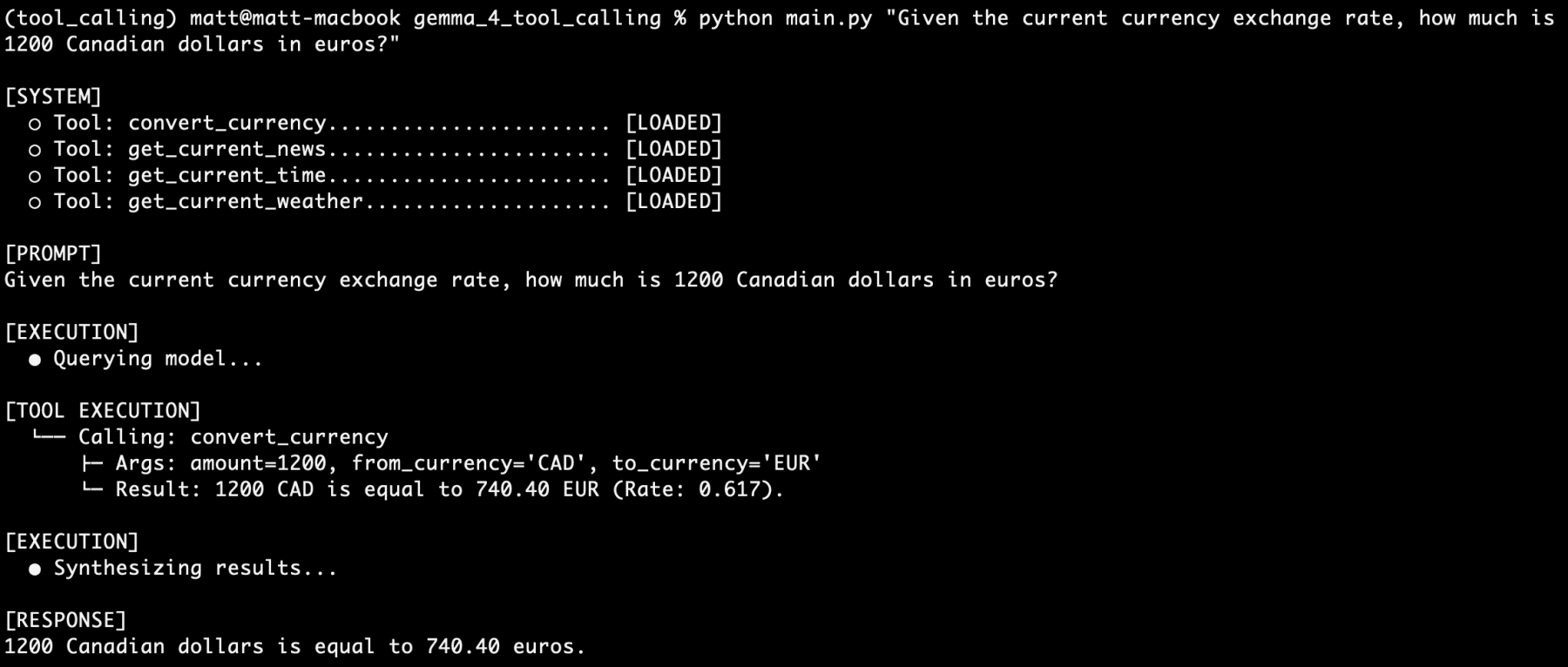
Given the present forex change price, how a lot is 1200 Canadian {dollars} in euros?
Extra profitable.
Now, let’s stack device calling requests. Let’s additionally remember the fact that we’re utilizing a 4 billion parameter mannequin that has half of its parameters energetic at anyone time throughout inference:
I’m going to France subsequent week. What’s the present time in Paris? What number of euros would 1500 Canadian {dollars} be? what’s the present climate there? what’s the newest information about Paris?
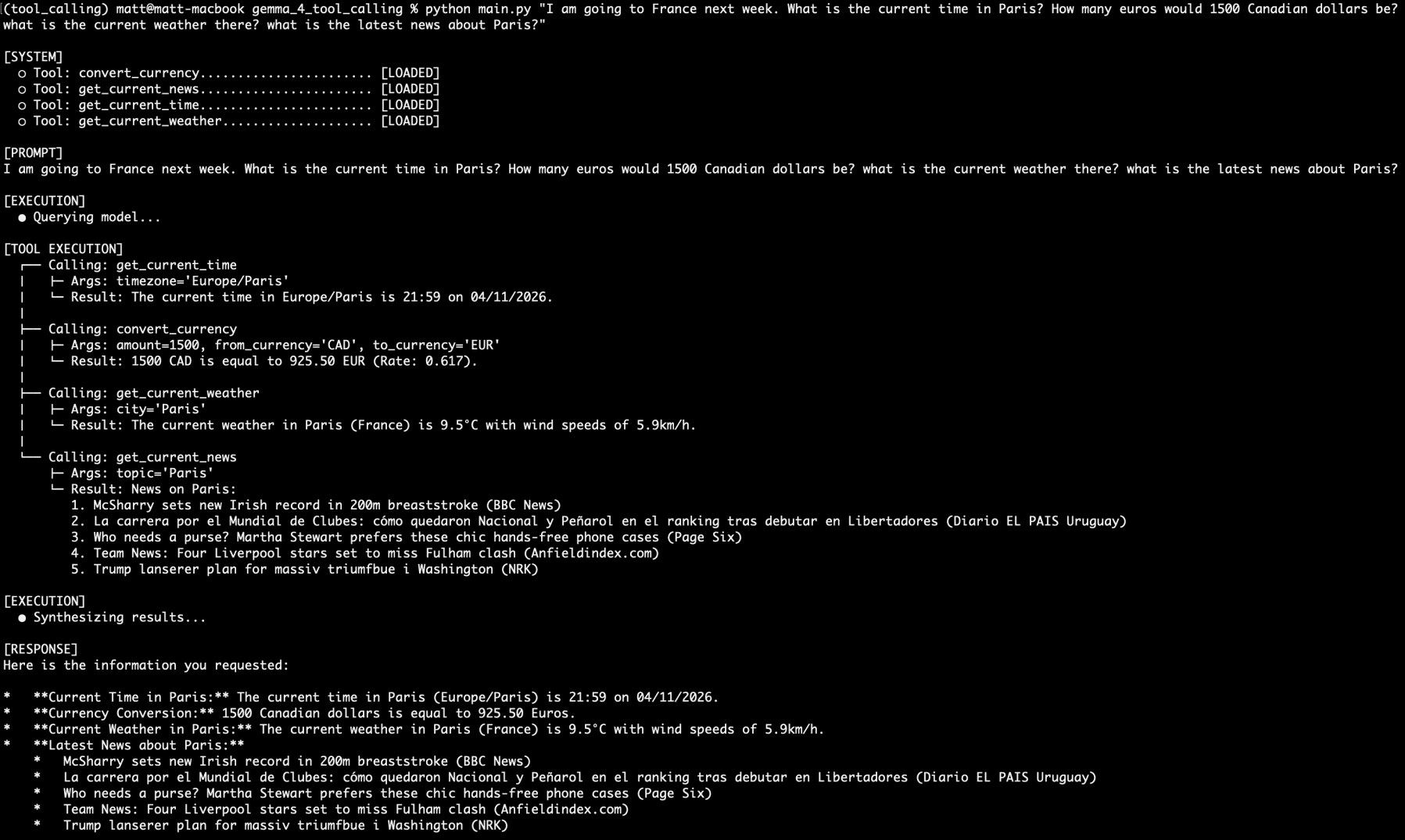
I’m going to France subsequent week…
Would you have a look at that. All 4 questions answered by 4 totally different capabilities from the 4 separate device calls. All on an area, non-public, extremely small language mannequin served by Ollama.
I ran queries on this setup over the course of the weekend, and by no means as soon as did the mannequin’s reasoning fail. By no means as soon as. A whole bunch of prompts. Admittedly, they had been on the identical 4 instruments, however no matter how obscure my in any other case cheap wording turn into, I couldn’t stump it.
Gemma 4 definitely seems to be a powerhouse of a small language mannequin reasoning engine with device calling capabilities. I’ll be turning my consideration to constructing out a completely agentic system subsequent, so keep tuned.
Conclusion
The appearance of device calling conduct inside open-weight fashions is without doubt one of the extra helpful and sensible developments in native AI of late. With the discharge of Gemma 4, we are able to function securely offline, constructing complicated techniques unfettered by cloud and API restrictions. By architecturally integrating direct entry to the net, native file techniques, uncooked knowledge processing logic, and localized APIs, even low-powered shopper units can function autonomously in ways in which had been beforehand restricted completely to cloud-tier {hardware}.