

{kind=link}
On this article, you’ll find out how the seven layers of a manufacturing AI agent stack match collectively, from the inspiration mannequin all the way down to deployment infrastructure.
Subjects we’ll cowl embrace:
- What every layer of the stack does, from the inspiration mannequin and orchestration framework via reminiscence, retrieval, instruments, observability, and deployment.
- The best way to implement every layer with working code, together with a stateful agent, a reminiscence system, a RAG pipeline, customized instruments, and tracing.
- Which mixture of applied sciences to make use of at every layer relying on whether or not you’re prototyping, scaling a startup, or working in an enterprise atmosphere.

Introduction
Image this: you ask an AI agent to analysis three opponents, pull the pricing knowledge from every of their web sites, summarize the findings right into a structured report, and drop it in a Slack channel by 9am. You hit enter. Thirty seconds later, the report is there.
What simply occurred underneath the hood shouldn’t be magic, and it’s not one factor. It’s seven distinct layers of know-how working in sequence, each dealing with a particular job, each able to breaking in its personal particular approach. The mannequin on the prime will get all the eye. The six layers beneath it are what decide whether or not the agent really works.
In accordance with Gartner, 40% of enterprise functions can be built-in with task-specific AI brokers by the top of 2026, up from lower than 5% in 2025. That isn’t a gradual curve. That could be a near-vertical adoption line, and the engineers and technical leads chargeable for these deployments want to grasp the complete stack, not simply the layer they occur to personal.
This text goes via every layer so as, from the inspiration mannequin all the way down to deployment infrastructure. By the top, you’ll know what every bit is, why it exists, how the layers join to one another, and what to really use at every stage.
Layer 1: The Basis Mannequin
The muse mannequin is the cognitive core of an agent. It’s the place reasoning occurs, language is known, and selections about what to do subsequent are made. All the things else within the stack is both feeding context into it or appearing on what it produces.
In sensible phrases, your predominant choices in 2026 are OpenAI’s GPT-5.5, Anthropic’s Claude Sonnet 4.6 (or Claude Opus 4.8 for more durable reasoning), Google’s Gemini 3.1 Professional, and open-weight fashions like Meta’s Llama 4 and Mistral Massive 3. Every has trade-offs price understanding earlier than you commit.
GPT-5.5 is quick for on a regular basis calls and dependable at tool-calling, and it has probably the most mature ecosystem of integrations and the widest neighborhood of builders who’ve already run into and solved the sting instances you’ll encounter. Claude Sonnet 4.6 handles lengthy paperwork and nuanced instruction-following nicely at a cheaper price level than Anthropic’s Opus tier, which issues in document-heavy workflows; attain for Claude Opus 4.8 when a process wants deeper, longer-horizon reasoning. Gemini 3.1 Professional has a 1 million token context window, which is related in case your agent must course of massive codebases or prolonged data bases in a single move. Open-weight fashions like Llama 4 provide you with full management over deployment and knowledge residency, at the price of the infrastructure overhead of working them your self.
There is no such thing as a longer a tough cut up between “commonplace” and “reasoning” mannequin households, the best way there was in 2025; OpenAI, Anthropic, and Google have every folded reasoning right into a single mannequin that decides how lengthy to suppose. GPT-5.5 ships with adjustable reasoning effort ranges (from none as much as xhigh), and the identical applies to Claude’s effort parameter and Gemini’s pondering ranges. For many agent workflows, the default or low-effort setting is the best alternative: quick and low cost. For duties that require cautious planning or mathematical reasoning, dialling the trouble stage up earns again its value in correctness.
Layer 2: The Orchestration Framework
If the inspiration mannequin is the mind, the orchestration framework is the nervous system. It handles the management stream: deciding what the agent ought to do subsequent, when it ought to name a device, the way it ought to deal with the end result, and the way the entire reasoning loop stays coherent throughout a number of steps.
The sample that the majority frameworks implement is named ReAct (Reasoning and Performing). The agent produces a thought, decides on an motion, executes the motion via a device, observes the end result, after which thinks once more. This loop repeats till the agent produces a remaining reply. It sounds easy. In apply, it’s the place most manufacturing failures happen: the agent calls the unsuitable device, will get caught in a loop, or fails to recognise when it has sufficient data to cease.
- LangChain is probably the most broadly adopted framework. It affords a big ecosystem of integrations and good documentation. The criticism that it provides an excessive amount of abstraction is honest on the prototype stage, however much less related when you want the options that abstraction offers. LangGraph, constructed by the identical crew, is healthier suited to stateful multi-agent workflows the place you want fine-grained management over the execution graph. In case your agent entails a number of specialists coordinating on a process, LangGraph is the cleaner alternative.
- CrewAI is designed particularly for multi-agent coordination. It enables you to outline brokers with roles, assign them duties, and have them collaborate inside a structured workflow. It’s higher-level than LangGraph and sooner to get working, however offers you much less management over the execution particulars. AutoGen, from Microsoft, takes a conversational method to multi-agent techniques. Brokers work together with one another via a message-passing interface, which makes the interplay logic very readable.
- Semantic Kernel is Microsoft’s enterprise-focused choice, with production-ready assist for C#, Python, and Java. In case you are working in an enterprise atmosphere already working on the Microsoft stack, it matches naturally. LlamaIndex began as a doc ingestion and retrieval framework and has since grown right into a full agent framework, with significantly robust assist for RAG-heavy workflows.
The suitable alternative depends upon what your agent must do. For a single-agent process runner: LangGraph or LangChain. For a coordinated crew of specialised brokers: CrewAI or AutoGen. For enterprise environments: Semantic Kernel. For document-heavy retrieval workflows: LlamaIndex.
Here’s a minimal working agent in LangGraph that handles device use and maintains state.
Stipulations:
|
pip set up langgraph langchain–openai langchain–neighborhood python–dotenv |
The best way to run: Save as agent.py, add your OPENAI_API_KEY to a .env file, then run python agent.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# agent.py # Minimal stateful agent with device use constructed on LangGraph # Python 3.10+ | LangGraph 0.2+ | LangChain 0.3+
import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain_community.instruments import DuckDuckGoSearchRun from langchain_core.messages import HumanMessage from langgraph.prebuilt import create_react_agent
# Load API key from .env file load_dotenv()
# Initialize the language mannequin # temperature=0 for deterministic, centered responses in agentic duties llm = ChatOpenAI( mannequin=“gpt-5.5”, temperature=0, api_key=os.getenv(“OPENAI_API_KEY”) )
# Register the instruments the agent can use # DuckDuckGoSearchRun requires no API key — good for improvement instruments = [DuckDuckGoSearchRun()]
# create_react_agent from LangGraph wires collectively the LLM, # instruments, and a built-in ReAct loop — no boilerplate required agent = create_react_agent(llm, instruments)
# Run the agent with a pattern question # The agent will resolve whether or not to make use of a device primarily based on the query end result = agent.invoke({ “messages”: [HumanMessage(content=“What is the current market cap of Nvidia?”)] })
# The ultimate response is the final message within the messages record print(end result[“messages”][–1].content material) |
What this does: create_react_agent handles the complete ReAct loop routinely. The agent receives the query, decides it wants present knowledge, calls the DuckDuckGo search device, reads the end result, and synthesizes a remaining reply. The messages record within the output incorporates the complete hint of that reasoning course of.
Layer 3: Reminiscence Programs
Statelessness is the default conduct of any LLM. Each name begins from scratch, with no data of what got here earlier than except you explicitly move that context in. For a one-shot query, that’s fantastic. For an agent that should observe a dialog, bear in mind a consumer’s preferences, or construct on work it did yesterday, it’s a elementary downside.
In accordance with Atlan’s analysis on AI agent reminiscence, 95% of enterprise generative AI pilots delivered zero measurable ROI in 2025, with failure attributed to context readiness relatively than mannequin high quality. Brokers are failing not as a result of the mannequin is unsuitable, however as a result of the reminiscence layer shouldn’t be there.
There are 4 forms of reminiscence in a manufacturing agent, and each handles a distinct job:
- Working reminiscence (in-context) is the lively context window. It holds the present dialog, any paperwork you could have handed in, and the outcomes of current device calls. It’s quick and requires no infrastructure, however it’s session-bound. When the session ends, it’s gone.
- Episodic reminiscence is a log of prior interactions. As described within the analysis on reminiscence sorts, episodic reminiscence shops what occurred: timestamp, process, actions taken, consequence. That is what permits an agent to reply “What did we work on final Tuesday?” or “What did the consumer say about this mission three periods in the past?“
- Semantic reminiscence is factual data saved externally, together with definitions, entity relationships, and domain-specific info that the mannequin was not educated on. That is the place your RAG pipeline feeds in (extra on that within the subsequent layer).
- Procedural reminiscence encodes workflows and tool-use patterns, repeatable behaviors the agent ought to all the time comply with. This lives within the system immediate or a version-controlled instruction file, and it shapes each response the agent produces.
Right here is how you can implement working and episodic reminiscence collectively utilizing LangChain’s advisable sample for LangChain 0.3+:
Stipulations:
|
pip set up langchain langchain–openai python–dotenv |
The best way to run: Save as reminiscence.py, guarantee your .env has OPENAI_API_KEY, then run python reminiscence.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
# reminiscence.py # Working reminiscence + episodic reminiscence for persistent agent context # Makes use of the present LangChain 0.3+ sample (legacy ConversationBufferMemory is deprecated)
import os import json from datetime import datetime from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain_core.messages import HumanMessage, AIMessage, SystemMessage, trim_messages
load_dotenv()
llm = ChatOpenAI( mannequin=“gpt-5.5”, temperature=0.2, api_key=os.getenv(“OPENAI_API_KEY”) )
# ── EPISODIC MEMORY STORE ───────────────────────────────────────────────────── # In manufacturing, substitute this record with a database (SQLite, Postgres, Redis). # The construction right here: every episode is a dict with timestamp, consumer enter, and agent response. episodic_store: record[dict] = []
def save_episode(user_input: str, agent_response: str) -> None: “”“Save a dialog flip to the episodic retailer.”“” episodic_store.append({ “timestamp”: datetime.now().isoformat(), “consumer”: user_input, “agent”: agent_response })
def load_recent_episodes(n: int = 5) -> str: “”“Retrieve the final N episodes as a formatted string for injection into context.”“” if not episodic_store: return “No prior dialog historical past.” current = episodic_store[–n:] return “n”.be part of( f“[{ep[‘timestamp’]}] Consumer: {ep[‘user’]} | Agent: {ep[‘agent’]}” for ep in current )
# ── WORKING MEMORY (IN-CONTEXT) ─────────────────────────────────────────────── # We handle the message record ourselves and move it via trim_messages # earlier than every LLM name to remain inside the mannequin’s context restrict. # max_tokens=4000 leaves headroom for the mannequin’s response. working_memory: record = []
def chat(user_input: str) -> str: “”“ Ship a message to the agent. Episodic historical past is injected into the system immediate. Working reminiscence is trimmed earlier than every name to stop context overflow. ““” # Inject episodic reminiscence into the system immediate so the mannequin has long-term context system = SystemMessage(content material=( “You’re a useful, context-aware assistant.nn” “Latest dialog historical past:n” f“{load_recent_episodes()}” ))
# Add the brand new consumer message to working reminiscence working_memory.append(HumanMessage(content material=user_input))
# Trim working reminiscence to remain inside the context window # This compresses older messages relatively than dropping them fully trimmed = trim_messages( working_memory, max_tokens=4000, technique=“final”, # Maintain the newest messages token_counter=llm, # Use the mannequin’s tokenizer for correct counts include_system=True, allow_partial=False )
# Name the mannequin with system context + trimmed working reminiscence response = llm.invoke([system] + trimmed) reply = response.content material
# Save the alternate to episodic reminiscence and add the reply to working reminiscence save_episode(user_input, reply) working_memory.append(AIMessage(content material=reply))
return reply
# ── DEMO ────────────────────────────────────────────────────────────────────── if __name__ == “__main__”: print(chat(“My identify is Alex and I am constructing a RAG pipeline for authorized paperwork.”)) print(chat(“What’s the very best vector database for my use case?”)) print(chat(“What did I let you know I used to be constructing?”)) # Exams episodic recall |
What this does: The episodic_store acts as a light-weight persistent log that will get summarized into the system immediate on each name. The working_memory record holds the in-session message historical past and will get trimmed by trim_messages earlier than every LLM name to stop token overflow. The ultimate take a look at query, “What did I let you know I used to be constructing?” verifies that episodic recall is working accurately even after the context window has moved on.
Layer 4: Vector Databases and Retrieval (RAG)
Basis fashions know rather a lot, however they have no idea your paperwork. They weren’t educated in your inner data base, your buyer assist historical past, your proprietary analysis, or something that has occurred since their coaching cutoff. Retrieval-Augmented Era (RAG) is the way you repair that.
The idea is easy: as a substitute of making an attempt to suit a whole data base into the context window, you change your paperwork into numerical representations (embeddings), retailer them in a vector database, and retrieve solely probably the most related chunks at question time. The agent will get a context window filled with exactly the best data relatively than the whole lot you could have ever written.
The worldwide vector database market reached $3.2 billion in 2025 and is rising at 24% yearly, which displays how central retrieval has develop into to manufacturing AI techniques.
The main choices every serve a distinct use case:
- Pinecone is absolutely managed with zero infrastructure overhead. You pay for it, push vectors to it, and question it. At 100 million vectors, it maintains recall with out tuning. The suitable alternative whenever you need to ship and never take into consideration infrastructure.
- Weaviate is open-source with a managed cloud choice, and it leads the sphere on hybrid search combining vector similarity, key phrase matching (BM25), and metadata filtering in a single question. In case your retrieval wants require greater than pure semantic search, Weaviate handles it natively.
- Chroma is developer-first and runs regionally with no infrastructure. The 2025 Rust rewrite made it considerably sooner. It’s the proper alternative for prototyping and small-to-medium manufacturing workloads the place developer expertise issues greater than scale.
- pgvector is a PostgreSQL extension that provides vector search to a database you might already be working. In case your crew already runs Postgres, pgvector is the lowest-friction path to manufacturing RAG. It handles hundreds of thousands of vectors with HNSW indexing and stays inside single-node PostgreSQL limits for many manufacturing workloads.
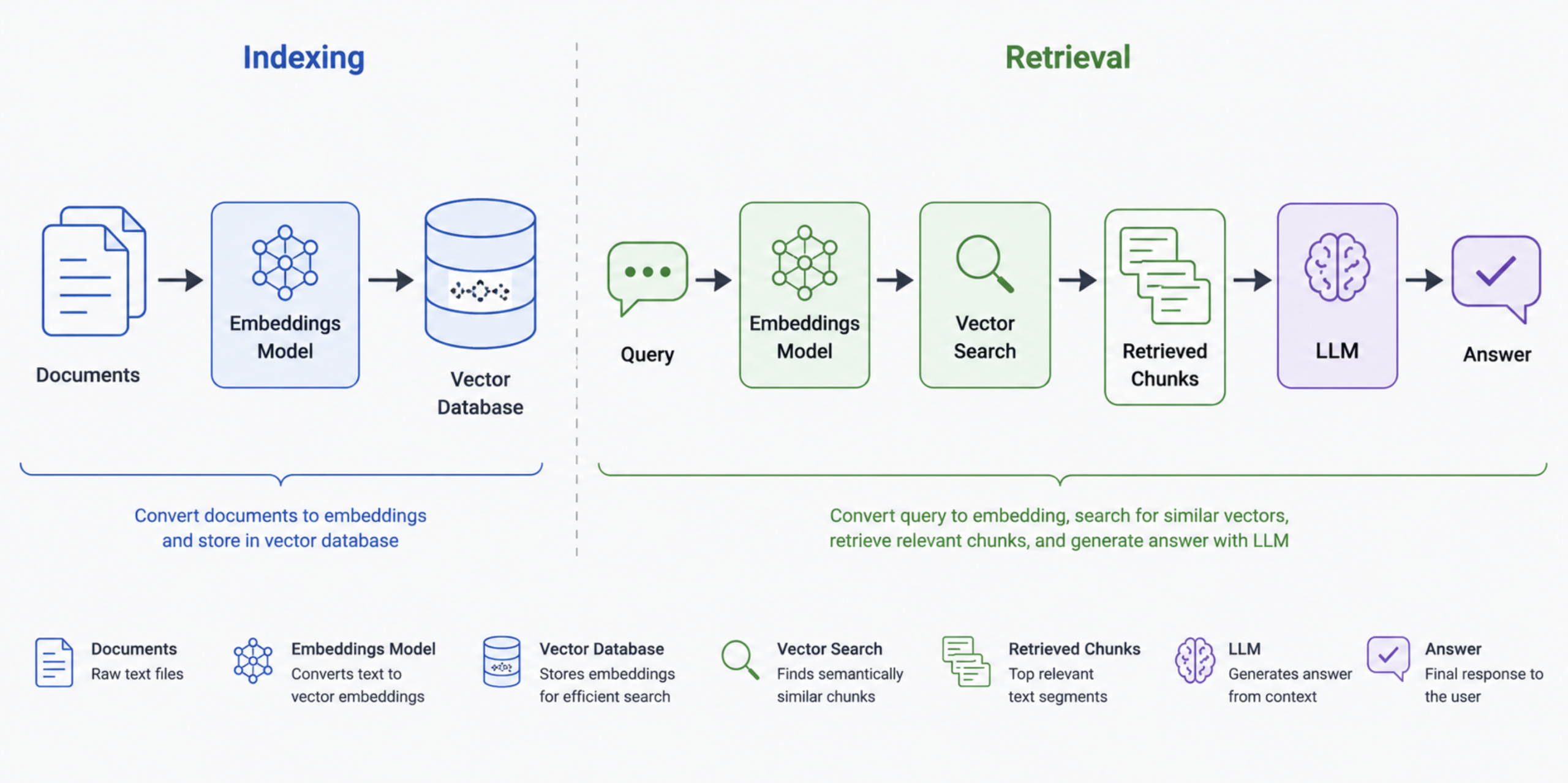
A horizontal three-step stream diagram exhibiting the RAG pipeline: Paperwork → Embeddings Mannequin → Vector Database (click on to enlarge)
Here’s a working RAG pipeline utilizing Chroma and OpenAI embeddings.
Stipulations:
|
pip set up langchain langchain–openai langchain–chroma langchain–textual content–splitters chromadb python–dotenv |
The best way to run: Save as rag_pipeline.py, add OPENAI_API_KEY to your .env, then run python rag_pipeline.py.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
# rag_pipeline.py # Minimal RAG pipeline: ingest paperwork → embed → retailer in Chroma → retrieve and reply # Python 3.10+ | ChromaDB 0.5+ | LangChain 0.3+
import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_chroma import Chroma from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_core.paperwork import Doc from langchain_core.prompts import ChatPromptTemplate
load_dotenv()
# ── STEP 1: SAMPLE DOCUMENTS ────────────────────────────────────────────────── # Exchange this record with actual paperwork out of your data base. # In manufacturing, load from PDFs, databases, APIs, or file techniques. paperwork = [ Document(page_content=“Pinecone is a managed vector database optimized for fast, “ “low-latency similarity search at scale. It handles infrastructure automatically “ “and is best for production RAG when you don’t want to manage servers.”, metadata={“source”: “vector_db_guide”, “topic”: “pinecone”}),
Document(page_content=“Weaviate is an open-source vector database with native hybrid search “ “support, combining BM25 keyword search with dense vector search in a single query. “ “It can be self-hosted or used via Weaviate Cloud.”, metadata={“source”: “vector_db_guide”, “topic”: “weaviate”}),
Document(page_content=“Chroma is a developer-friendly, local-first vector database ideal for “ “prototyping. The 2025 Rust rewrite significantly improved performance. “ “Best for small-to-medium production workloads and local development.”, metadata={“source”: “vector_db_guide”, “topic”: “chroma”}),
Document(page_content=“pgvector is a PostgreSQL extension that adds vector similarity search “ “to an existing Postgres database. With HNSW indexing, it handles millions of vectors “ “at low latency. Best choice if your team already runs PostgreSQL in production.”, metadata={“source”: “vector_db_guide”, “topic”: “pgvector”}), ]
# ── STEP 2: CHUNK THE DOCUMENTS ─────────────────────────────────────────────── # Massive paperwork are cut up into smaller chunks earlier than embedding. # chunk_size=500 characters; chunk_overlap=50 preserves context throughout chunk boundaries. splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = splitter.split_documents(paperwork)
# ── STEP 3: EMBED AND STORE IN CHROMA ──────────────────────────────────────── # OpenAIEmbeddings converts every chunk right into a high-dimensional vector. # Chroma shops these vectors regionally within the ./chroma_db listing. # On subsequent runs, the present retailer is loaded relatively than rebuilt. embeddings = OpenAIEmbeddings( mannequin=“text-embedding-3-small”, # Quick and cost-effective for many RAG duties api_key=os.getenv(“OPENAI_API_KEY”) )
vectorstore = Chroma.from_documents( paperwork=chunks, embedding=embeddings, persist_directory=“./chroma_db” # Persist to disk so you do not re-embed on each run )
# ── STEP 4: RETRIEVAL ────────────────────────────────────────────────────────── # Converts the question into an embedding and finds probably the most related chunks. # okay=3 returns the highest 3 most related chunks. retriever = vectorstore.as_retriever(search_kwargs={“okay”: 3})
# ── STEP 5: GENERATION ──────────────────────────────────────────────────────── llm = ChatOpenAI( mannequin=“gpt-5.5”, temperature=0, api_key=os.getenv(“OPENAI_API_KEY”) )
# The immediate tells the mannequin to make use of solely the retrieved context. # This prevents the mannequin from hallucinating info not in your data base. rag_prompt = ChatPromptTemplate.from_messages([ (“system”, “Answer the question using only the provided context. “ “If the answer isn’t in the context, say so clearly.nn” “Context:n{context}”), (“human”, “{question}”) ])
def reply(query: str) -> str: “”“Retrieve related chunks and generate a grounded reply.”“” # Retrieve probably the most related doc chunks for this query retrieved_docs = retriever.invoke(query)
# Mix the retrieved chunks right into a single context block context = “nn”.be part of(doc.page_content for doc in retrieved_docs)
# Construct and invoke the immediate with the query and retrieved context immediate = rag_prompt.invoke({“context”: context, “query”: query}) response = llm.invoke(immediate) return response.content material
# ── DEMO ────────────────────────────────────────────────────────────────────── if __name__ == “__main__”: q = “Which vector database ought to I exploit if I already run PostgreSQL?” print(f“Q: {q}nA: {reply(q)}”) |
What this does: The pipeline has two phases. Throughout indexing, paperwork are chunked, transformed to embeddings through OpenAI’s text-embedding-3-small mannequin, and saved in a neighborhood Chroma database. Throughout retrieval, the question is embedded utilizing the identical mannequin, the three most related chunks are pulled from Chroma, and the LLM makes use of these chunks and solely these chunks to reply. The persist_directory parameter means Chroma saves the vectors to disk, so you don’t pay to re-embed your paperwork on each run.
Layer 5: Instruments and Exterior Integrations
An agent with out instruments is a really costly textual content predictor. Instruments are what give brokers the power to behave on the world relatively than simply speak about it.
In technical phrases, a device is a perform that the mannequin can select to name. You describe what the perform does in pure language, outline its enter parameters with a schema, and the mannequin decides when calling that perform would assist it reply the query. The mannequin doesn’t execute the perform; your code does. The mannequin simply decides when and with what arguments.
The classes of instruments that matter most in manufacturing brokers are: net search (for present data), code execution (for calculation and knowledge processing), file I/O (for studying and writing paperwork), API calls (for connecting to exterior companies), and browser use (for interacting with net interfaces that shouldn’t have APIs).
One improvement price understanding is the Mannequin Context Protocol (MCP), launched by Anthropic in late 2024. MCP is a standardized approach for fashions to speak with exterior instruments and knowledge sources. Relatively than each crew writing customized integration code for each device, MCP offers a shared protocol. Amazon Bedrock Brokers added native MCP assist in 2025, and adoption throughout the ecosystem is rising quick.
The one most vital factor about device design is the schema. The mannequin decides whether or not to make use of a device primarily based on its description and decides what arguments to move primarily based on the parameter schema. A obscure description produces unsuitable device calls. A well-typed schema with clear parameter descriptions produces dependable ones.
Stipulations:
|
pip set up langchain langchain–openai langchain–neighborhood python–dotenv |
The best way to run: Save as instruments.py, add OPENAI_API_KEY to your .env, then run python instruments.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
# instruments.py # Defining, registering, and utilizing instruments with a LangChain agent # Python 3.10+ | LangChain 0.3+
import os import json import requests from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain.instruments import device from langchain_community.instruments import DuckDuckGoSearchRun from langchain_core.messages import HumanMessage from langgraph.prebuilt import create_react_agent
load_dotenv()
llm = ChatOpenAI(mannequin=“gpt-5.5”, temperature=0, api_key=os.getenv(“OPENAI_API_KEY”))
# ── TOOL 1: WEB SEARCH ──────────────────────────────────────────────────────── # Constructed-in DuckDuckGo device — no API key wanted. search = DuckDuckGoSearchRun()
# ── TOOL 2: WEATHER LOOKUP ──────────────────────────────────────────────────── # The @device decorator does three issues: # 1. Registers the perform as a callable device # 2. Makes use of the perform identify because the device identify # 3. Makes use of the docstring because the device description (that is what the mannequin reads) # The outline is important — obscure descriptions trigger unsuitable device calls. @device def get_weather(metropolis: str) -> str: “”“ Fetch the present climate for a given metropolis. Use this when the consumer asks about climate circumstances, temperature, or forecasts. Enter: metropolis identify as a string (e.g., ‘London’, ‘Tokyo’, ‘New York’). ““” attempt: # Utilizing open-meteo (free, no API key) for geocoding and climate geo_url = f“https://geocoding-api.open-meteo.com/v1/search?identify={metropolis}&rely=1” geo = requests.get(geo_url, timeout=5).json()
if not geo.get(“outcomes”): return f“Couldn’t discover location knowledge for ‘{metropolis}’.”
lat = geo[“results”][0][“latitude”] lon = geo[“results”][0][“longitude”]
weather_url = ( f“https://api.open-meteo.com/v1/forecast” f“?latitude={lat}&longitude={lon}” f“¤t_weather=true” ) climate = requests.get(weather_url, timeout=5).json() present = climate.get(“current_weather”, {})
return ( f“Climate in {metropolis}: “ f“{present.get(‘temperature’, ‘N/A’)}°C, “ f“wind velocity {present.get(‘windspeed’, ‘N/A’)} km/h.” ) besides Exception as e: # At all times return a string from instruments, even on failure. # Elevating exceptions from instruments can crash the agent loop. return f“Climate lookup failed for ‘{metropolis}’: {str(e)}”
# ── TOOL 3: JSON CALCULATOR ─────────────────────────────────────────────────── @device def calculate(expression: str) -> str: “”“ Consider a mathematical expression and return the end result. Use this for arithmetic, proportion calculations, or any numerical computation. Enter: a sound Python mathematical expression as a string (e.g., ‘(150 * 1.08) / 12’). Do NOT use for complicated code execution — solely simple arithmetic expressions. ““” attempt: # eval is scoped to solely permit math — no builtins, no imports end result = eval(expression, {“__builtins__”: {}}, {}) return f“End result: {end result}” besides Exception as e: return f“Calculation error: {str(e)}”
# ── REGISTER TOOLS AND BUILD AGENT ──────────────────────────────────────────── instruments = [search, get_weather, calculate] agent = create_react_agent(llm, instruments)
# ── DEMO ────────────────────────────────────────────────────────────────────── if __name__ == “__main__”: queries = [ “What is the weather in Lagos right now?”, “If I earn $85,000 a year, what is my monthly gross salary?”, “Who won the most recent FIFA World Cup?” ]
for question in queries: print(f“nQuery: {question}”) end result = agent.invoke({“messages”: [HumanMessage(content=query)]}) print(f“Reply: {end result[‘messages’][-1].content material}”) |
What this does: Three instruments are registered: an internet search device for present occasions, a climate device that calls a free API with no key required, and a calculator that safely evaluates mathematical expressions. The agent receives every question, causes about which device to make use of, calls it, and synthesizes a solution from the end result. The important thing design element to note is within the docstrings; every device description is exact about what the device does, when to make use of it, and what format the enter ought to take.
Layer 6: Observability and Analysis
Here’s a manufacturing reality that doesn’t get stated sufficient: LLMs fail silently. Because the crew at Kanerika put it, a hallucinated reply nonetheless returns HTTP 200. An ordinary infrastructure monitoring device sees a profitable request. You see nothing uncommon. In the meantime, your agent has been confidently giving unsuitable solutions for 3 days.
Conventional monitoring was constructed for a world the place “right” is binary: the perform returned the best sort, the API returned 200, the question accomplished in underneath 100ms. LLM correctness is semantic. The response could be structurally legitimate, grammatically fluent, and fully unsuitable. That requires a distinct observability layer fully.
There are three issues a very good LLM observability setup tracks. Tracing follows each step of the agent’s execution: the LLM calls, the device invocations, the retrieval queries, the intermediate reasoning steps, and the way lengthy each took. Analysis scores the output towards metrics that matter: faithfulness (did it keep grounded within the retrieved context?), relevance (did it reply the query requested?), and hallucination fee. Monitoring tracks behavioral drift over time, whether or not the agent’s efficiency on a given class of inputs is getting higher or worse because the mannequin and prompts evolve.
The main platforms every have a distinct energy. LangSmith offers the deepest integration with LangChain and LangGraph. In case you are already in that ecosystem, it’s the quickest path to working traces. Langfuse is open-source with over 19,000 GitHub stars and an MIT license, self-hostable, and works with any framework. Arize Phoenix brings ML-grade analysis rigor and ships with over 50 research-backed metrics masking faithfulness, relevance, security, and hallucination detection.
In accordance with MLflow’s evaluation of observability platforms, the best alternative typically comes all the way down to your framework: LangChain groups get probably the most from LangSmith, whereas groups on LlamaIndex or uncooked API calls are higher served by Phoenix or Langfuse.
Right here is how you can add Langfuse tracing to an present agent with minimal modifications.
Stipulations:
|
pip set up langfuse langchain langchain–openai python–dotenv |
Enroll at langfuse.com for a free account and add LANGFUSE_PUBLIC_KEY and LANGFUSE_SECRET_KEY to your .env. Self-hosting can also be obtainable in the event you favor to maintain knowledge by yourself infrastructure.
The best way to run: Save as observability.py and run python observability.py. Open your Langfuse dashboard to see the hint.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# observability.py # Including Langfuse tracing to a LangChain agent # Langfuse captures each LLM name, device invocation, and token rely routinely.
import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain_community.instruments import DuckDuckGoSearchRun from langchain_core.messages import HumanMessage from langgraph.prebuilt import create_react_agent
# Langfuse integrates through the CallbackHandler sample. # It intercepts each LangChain occasion and sends it to your Langfuse dashboard. from langfuse.langchain import CallbackHandler
load_dotenv()
# ── LANGFUSE SETUP ───────────────────────────────────────────────────────────── # CallbackHandler reads LANGFUSE_PUBLIC_KEY and LANGFUSE_SECRET_KEY from the atmosphere. # session_id teams all associated traces into one session — helpful for debugging conversations. # user_id ties traces to a particular consumer for per-user efficiency evaluation. langfuse_handler = CallbackHandler( session_id=“demo_session_001”, user_id=“demo_user” )
# ── AGENT SETUP ──────────────────────────────────────────────────────────────── llm = ChatOpenAI( mannequin=“gpt-5.5”, temperature=0, api_key=os.getenv(“OPENAI_API_KEY”), callbacks=[langfuse_handler] # Connect the handler right here — that is the one change )
instruments = [DuckDuckGoSearchRun()] agent = create_react_agent(llm, instruments)
# ── RUN WITH TRACING ────────────────────────────────────────────────────────── # Go the handler in config so it traces device calls in addition to LLM calls. # With out this, solely the LLM calls are traced — device invocations are invisible. end result = agent.invoke( {“messages”: [HumanMessage(content=“What is the latest version of Python?”)]}, config={“callbacks”: [langfuse_handler]} )
print(end result[“messages”][–1].content material)
# Flush ensures all traces are despatched to Langfuse earlier than the script exits. # In a long-running server, that is dealt with routinely. langfuse_handler.flush()
print(“nTrace despatched to Langfuse. Examine your dashboard at https://cloud.langfuse.com”) |
What this does: Two modifications from a normal agent setup: the CallbackHandler is initialized with a session and consumer ID, and it’s connected to each the LLM and the agent.invoke config. That’s sufficient for Langfuse to seize the complete hint of each LLM name, each device invocation, token counts, latency, and the entire enter/output at every step. All the things it is advisable to debug a manufacturing failure or observe high quality drift over time.
Layer 7: Deployment Infrastructure
You’ll be able to have a flawless agent in improvement that turns right into a upkeep downside in manufacturing. The infrastructure layer is the place that hole lives.
At a minimal, your agent ought to be containerized with Docker. Containers provide you with constant conduct throughout environments, simple dependency administration, and a clear path to any cloud deployment goal. The choice — transport Python scripts with a necessities.txt and hoping the atmosphere matches — creates a category of bugs that wastes engineering time disproportionate to the trouble containerization would have taken.
For many manufacturing brokers, you could have two architectural choices for the serving layer: a synchronous API or an async queue. A synchronous API (Flask or FastAPI) works when your agent completes in underneath just a few seconds, and you’ll afford to carry the HTTP connection open.
When your agent entails a number of device calls, lengthy retrieval pipelines, or doc processing which may take 30 to 60 seconds, an async queue (Celery, AWS SQS, or Google Pub/Sub) is the higher alternative. The consumer submits a job, will get a process ID again instantly, and polls for the end result.
On the cloud aspect, all three main platforms now have managed agent infrastructure. Amazon’s AgentCore, which turned usually obtainable in October 2025, offers devoted agentic infrastructure on AWS for reminiscence administration, device execution, and session dealing with with out provisioning servers. Google Vertex AI Agent Builder is the pure alternative for groups already within the GCP ecosystem, with native Gemini integration and built-in observability. Azure OpenAI Service with Semantic Kernel is the enterprise default for Microsoft outlets.
For value administration, three practices make the largest distinction: caching (returning saved responses for repeated an identical queries relatively than calling the mannequin once more), request batching (grouping non-urgent duties to scale back per-call overhead), and setting max_iterations in your agent executor to stop runaway loops from consuming tokens with out sure.

A vertical stack diagram exhibiting all 7 layers labeled prime to backside: Basis Mannequin, Orchestration Framework, Reminiscence Programs, Vector Database and RAG, Instruments and Integrations, Observability and Analysis, Deployment Infrastructure (click on to enlarge)
Placing It All Collectively
The suitable decisions at every layer rely on the place you’re within the mission lifecycle. Here’s a sensible reference that displays the analysis and trade-offs mentioned above.
Prototype (transfer quick, minimal infrastructure):
| Layer | Selection | Motive |
|---|---|---|
| Basis Mannequin | GPT-5.5 | Dependable tool-calling, mature ecosystem |
| Orchestration | LangGraph | Quick setup, good documentation |
| Reminiscence | In-context solely | No infrastructure wanted |
| Vector DB | Chroma | Native, no ops, good developer expertise |
| Instruments | DuckDuckGo + customized @device capabilities | Zero API keys required |
| Observability | Langfuse (cloud free tier) | One-line setup |
| Deployment | Native / Docker | Ship quick |
Manufacturing Startup (scale with management):
| Layer | Selection | Motive |
|---|---|---|
| Basis Mannequin | GPT-5.5 + Claude Sonnet 4.6 fallback | Reliability with redundancy |
| Orchestration | LangGraph or CrewAI | State administration and multi-agent assist |
| Reminiscence | Episodic (Postgres) + Semantic (RAG) | Full persistent context |
| Vector DB | Weaviate or Pinecone | Scale and hybrid search |
| Instruments | Full device suite with MCP | Standardized integrations |
| Observability | Langfuse self-hosted or Arize Phoenix | Information management + ML-grade evals |
| Deployment | Docker + Kubernetes + async queue | Manufacturing-grade, cost-controlled |
Enterprise:
| Layer | Selection | Motive |
|---|---|---|
| Basis Mannequin | Azure OpenAI or AWS Bedrock | Compliance, knowledge residency, SLA |
| Orchestration | Semantic Kernel or LangGraph | Enterprise language assist, governance |
| Reminiscence | Managed reminiscence with audit path | Regulatory necessities |
| Vector DB | Weaviate or pgvector | Self-hostable, compliance-ready |
| Instruments | MCP-based, internally authorised | Safety overview and entry management |
| Observability | Langfuse self-hosted or Datadog LLM module | Current infrastructure integration |
| Deployment | AWS AgentCore / Vertex AI Agent Builder | Absolutely managed, ruled, auditable |
Conclusion
The muse mannequin is the a part of this stack that will get written about. The opposite six layers are the components that decide whether or not what you constructed really works in manufacturing.
An agent fails on the orchestration layer when the ReAct loop will get caught. It fails on the reminiscence layer when it forgets the context it wants. It fails on the retrieval layer when the unsuitable chunks are returned, and the mannequin hallucinates a grounded-sounding reply. It fails on the instruments layer when a schema is just too obscure, and the mannequin calls the unsuitable perform. It fails on the observability layer when you don’t have any solution to know that any of that is occurring. And it fails on the deployment layer when the infrastructure can not deal with the latency or value necessities of actual visitors.
Gartner estimates that over 40% of agentic AI initiatives are prone to cancellation by 2027 attributable to unclear worth, rising prices, and weak governance. Most of these failures will hint again to not a foul mannequin alternative however to a stack that was constructed layer by layer and not using a clear image of how the layers join.
Understanding the complete stack doesn’t imply it’s important to construct all of it. It means what selections you’re making and what you’re buying and selling off whenever you make them. That’s the distinction between an agent that works in a demo and one which ships.