

{kind=link}

RLWRLD mentioned real-world interplay requires recognizing what to do, sustaining related state over time, and grounding selections in bodily significant indicators. | Supply: RLWRLD
RLWRLD final week introduced RLDX-1, a brand new dexterity-first basis mannequin. The corporate constructed the mannequin to deal with complicated duties within the real-world trade utilizing excessive degree-of-freedom (DoF) robotic fingers.
Current basis fashions typically lack important capabilities, similar to context memorization or pressure sensing, required for seamless real-world deployment, in accordance with RLWRLD. To handle this, RLDX-1 encompasses the whole robotics lifecycle. It integrates a scalable data-collection pipeline, a flexible structure design, strong coaching methodologies, and optimized deployment methods, mentioned the firm.
Consequently, RLDX-1 achieves state-of-the-art efficiency, claimed RLWRLD. The mannequin showcases precision and generalization throughout each simulated environments and bodily industrial functions.
RLWLRD designed the RLDX-1 basis mannequin from the bottom up for dexterous robotic fingers. Each element exists as a result of a particular failure mode on an actual activity required them. The result’s a single mannequin that may see, really feel, keep in mind, and adapt, deployable throughout single-arm, dual-arm, and humanoid embodiments with high-DoF fingers.
RLWRLD identifies 5 regimes of dexterity
The final mile of business automation is dexterity. Right now’s robots nonetheless can’t reliably pour espresso because the pot grows lighter, decide a transferring object off a conveyor, or rotate a hex nut with fingertips, famous Seoul, South Korea-based RLWRLD.
RLWRLD distilled these recurring buyer wants into DexBench, a benchmark that organizes them alongside 5 regimes of dexterity, the place every regime is a particular failure mode of right this moment’s robots.
These 5 regimes are:
- Grasp variety: 5-fingered fingers are the prerequisite each regime beneath assumes. RLWLRD has run greater than 10 of them in-house. It makes use of two knowledge pipelines to diversify greedy. Artificial robotic knowledge augments a dataset from a small teleoperation set, whereas Human Knowledge covers the high-DoF in-hand dexterity that teleoperation can’t attain.
- Spatial precision: The coverage should seize enough scene construction to put contact appropriately earlier than contact is made. RLDX-1 strengthens this functionality with a robot-specialized imaginative and prescient language mannequin (VLM) fine-tuned on robotic visible query and answering (VQA), the place the questions explicitly goal the geometric relationship between the robotic end-effector and the goal object. This coaching encourages the VLM to higher floor object areas and spatial relations which can be important for exact contact placement.
- Temporal precision: A single-frame coverage commits to the place objects had been; by the point the hand arrives, the conveyor object has moved. To handle this, the Movement Module extracts movement options from space-time visible correspondences and amortizes multi-frame context right into a compact illustration. It lets the coverage see the place and how briskly objects are going.
- Contact precision: A espresso pot rising lighter is visually invariant; the sign is in wrist torque. The Physics Module provides tactile and torque their very own streams and predicts future contact states alongside actions, so the coverage anticipates contact transitions earlier than they occur.
- Context consciousness: That is task-level reasoning that wraps across the three precisions. With out it, even a superbly executed movement is stranded on the single step it was deliberate for, mentioned RLWRLD. The coverage wants reminiscence, restoration, and progress-awareness.
RLDX is constructed on a multi-stream motion transformer
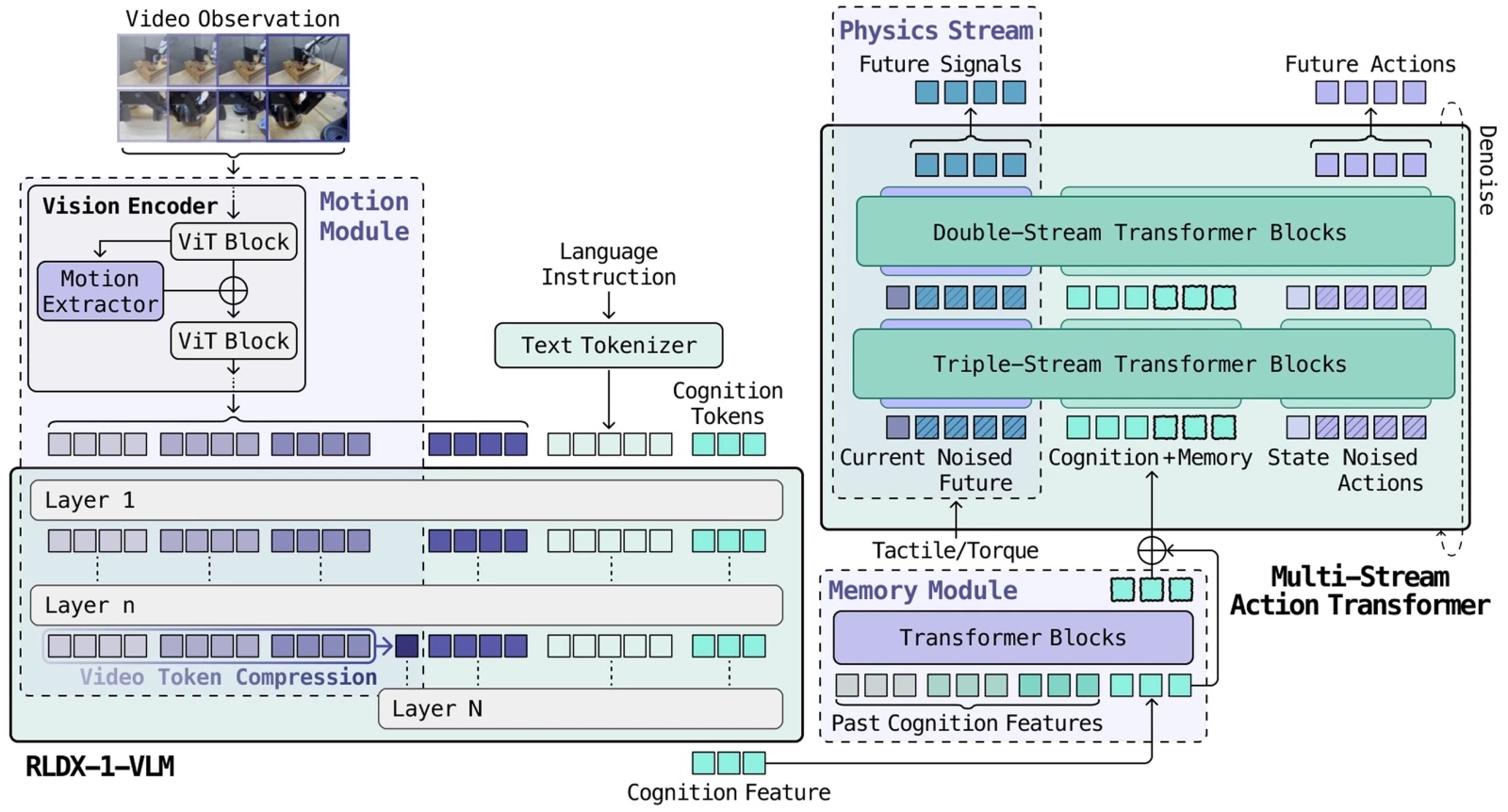
The complete RLDX structure. | Supply: RLWRLD
Every regime enters the mannequin as a essentially totally different modality: Torque is a high-rate steady stream, video is sparse high-dimensional frames, and reminiscence is stateful. In a single standard transformer, whichever modality dominates the gradient absorbs all of the capability whereas the remaining change into ornamental.
The architectural reply is Multi-Stream Motion Transformer (MSAT). Every modality will get its personal processing stream, and cognition tokens compress the VLM output right into a fixed-size interface. What follows unpacks every layer. The structure that holds these modalities collectively, the information engine that trains it, and the post-training that makes it deployable.
RLDX is constructed on MSAT, an structure the place every modality will get its personal processing stream, and joint self-attention lets them work together.
Current vision-language-action fashions (VLAs) fuse modalities inside a single transformer stream, the place whichever modality dominates the gradient absorbs all of the capability. MSAT provides every modality its personal devoted processing stream, then lets the streams talk by way of joint self-attention with out being pressured right into a shared illustration prematurely.
Early blocks hold modalities in parallel streams; later blocks fuse them for motion decoding, defined RLWRLD.
RLDX-1 makes use of a robot-specialized VLM
Basic-purpose VLMs are robust at visible reasoning, however they don’t robotically perceive what issues for robotic management, RLWRLD asserted. To shut this hole, RLDX-1 fine-tunes Qwen3-VL 8B on a robot-trajectory VQA dataset focusing on three action-relevant talents.
First, it targets spatial reasoning concerning the geometric relationship between the end-effector and goal objects. Second is activity understanding, which identifies the intermediate subtask implied by the present commentary. Third is motion grounding that causes concerning the low-level motion related to the present body.
The fine-tuned mannequin, RLDX-1-VLM, serves because the visible reasoning spine for motion technology: +3.42percentp over the vanilla VLM on RoboCasa.
A single-frame coverage is at all times one step behind the scene, famous RLWRLD. By the point the hand arrives, the conveyor object has moved. The Movement Module has two complementary items.
A video token compression layer feeds multi-frame observations by way of the VLM, compressing previous frames into movement tokens by way of common pooling, so the mannequin effectively sees the place issues are going. A movement studying layer within the imaginative and prescient encoder fashions spatio-temporal self-similarities (STSS), capturing rotation, velocity, and interplay dynamics immediately from visible options.
Collectively: +37.5percentp over GR00T N1.6 and π₀.₅ on performing a pick-and-place activity on conveyor belt.
RLDX-1’s Physics Module serves two key functionalities
The Physics Module integrates tactile and torque suggestions into RLDX as native modalities. These bodily indicators are essential for duties that require contact-rich object manipulation, primarily serving two key functionalities: weight estimation and speak to detection.
For weight estimation, when a robotic pours espresso, the module captures weight shifts throughout each fingers to tell RLDX exactly when to cease. For contact detection, a robotic must establish the precise second of contact to transition from approaching to selecting. Whereas joint angles present ambiguous data relating to contact timing, torque indicators supply distinct, sharp adjustments on the level of contact.
To totally leverage this, RLDX employs a devoted stream that not solely processes these indicators but additionally predicts future torque states, permitting the coverage to own informative bodily embeddings. Moreover, when such sensors are unavailable, the sensory stream robotically deactivates for sleek degradation to vision-only, permitting a single mannequin to assist varied {hardware} setups.
Inside RLDX-1’s cognition interface and reminiscence module
The VLM produces a wealthy scene understanding, however passing all of its tokens to the motion mannequin will be gradual and wasteful, mentioned RLWRLD.
The Cognition Interface appends 64 learnable cognition tokens to the VLM’s enter. Via consideration, they compress the complete sequence right into a fixed-size illustration that carries precisely the data the motion mannequin wants. The velocity win: +35percentp inference speedup (16.3→22.1 Hz).
However these tokens do double responsibility. The identical 64-token illustration turns into the unit of long-horizon reminiscence. A FIFO sliding cache shops previous cognition options throughout the rollout, and the Reminiscence Module attends over this cache to trace activity progress.
Pack a field, assemble a product, or depend 10 apples into an opaque bag. Every step relies on figuring out what already occurred, in accordance with RLWRLD. Compression and reminiscence are the identical mechanism, reused, it mentioned.
RLWRLD makes use of artificial knowledge to generate what it could’t accumulate
Actual teleoperation alone can’t populate the area a five-finger hand should cowl. RLWLRD’s artificial knowledge pipeline amplifies a small seed set of actual demonstrations utilizing video technology fashions, similar to Cosmos-Predict2.
A fine-tuned video mannequin synthesizes new trajectories at scale by various scene components. These embrace lighting, surfaces, positions, and backgrounds.
An inverse dynamics mannequin then annotates the generated movies with motion labels, adopted by a video high quality and motion-consistency filter that retains solely instruction-following and bodily believable artificial knowledge.
In the end, RLWRLD mentioned this yields video-action constant artificial knowledge that’s helpful for VLA coaching, moderately than merely plausible-looking outputs, with an round 5 instances enhance in knowledge scale, resulting in a 9.2% acquire in common success fee on the GR-1 Tabletop benchmark.

RLWRLD additionally learns from human fingers
There is no such thing as a higher trainer for a dexterous robotic hand than a human hand, RLWRLD mentioned. Teleoperation is usually too gradual and imprecise for five-finger manipulation, as standard controllers fail to seize the high-speed reflexes required for dynamic duties like catching or speedy regrasping.
Probably the most adopted different, UMI, matches the robotic finish effector onto a humanoid, however just for grippers, claimed RLWRLD. It cited DexUMI, which it mentioned ported the recipe to five-finger fingers and has not held up in observe: poor ergonomics, constrained hand movement, and a tool that have to be redesigned for each new robotic hand.
RLDX takes the alternative route: file from the naked human hand and shut the kinematic and morphological hole in software program, with a retargeting framework constructed for five-finger dexterity.
- The pipeline has 4 levels, mentioned RLWRLD:
- Monitor the human hand and object
- Reconstruct the workspace with 3D Gaussian Splatting
- Retarget onto the robotic hand
The corporate mentioned that makes use of can roll it out in simulation to supply VLA coaching knowledge. This yields over 200 demonstrations per hour and scales additional with automated augmentations, it mentioned.
RLWRLD supplies a coaching pipeline
RLDX is skilled by way of a three-stage pipeline, every stage constructing on the earlier checkpoint. The primary is pre-training for basic manipulation. The mannequin learns basic manipulation data throughout single-arm, dual-arm, and humanoid embodiments (many outfitted with dexterous five-finger fingers) by way of a shared MSAT core with per-embodiment encoders/decoders.
The pre-training combine comprises trajectories from numerous real-world datasets and our artificial robotic knowledge. RLWRLD randomly drops embodiment tags in order that the mannequin learns each an embodiment-conditioned coverage and an embodiment-agnostic one in a single spine.
Subsequent, it makes use of mid-training for goal embodiments. Ranging from the pre-trained checkpoint, the Reminiscence Module and Physics Module are added, initialized from scratch, with current weights preserved. Embodiment-specific dexterity knowledge builds temporal and sensory capabilities. Pre-training knowledge is partially reused to forestall catastrophic forgetting; Artificial robotic knowledge fill in for data-scarce embodiments.
Lastly, it makes use of post-training for deployment. Imitation studying alone leaves room for enchancment for higher success fee and optimum motions.
Two mechanisms shut the hole, equivalent to the 2 remaining faces of Context Consciousness:
- DAgger (Restoration) focuses coaching knowledge on the failures the mannequin truly makes. The mannequin is deployed and corrected when it goes out of distribution, and people corrections change into new coaching knowledge. Every iteration narrows the failure distribution till the error sample disappears.
- Progress-Conscious RL (Progress-Consciousness) is a separate VLM post-trained as a realized progress estimator. Given a trajectory, it predicts how shut the coverage is to finishing the duty. This supplies reinforcement studying (RL) with a dense, visually-grounded reward sign that drives the coverage towards activity progress with out hand-engineered, task-specific targets. By reusing batch on-policy knowledge, each rollout is totally exploited throughout a number of updates, making real-robot RL extra tractable and inexpensive.
RLWRLD mentioned its remaining coverage can full duties round 3 times sooner than imitation studying alone.
How does RLDX-1 carry out towards frequent benchmarks?
RLDX ships as three checkpoints: RLDX-1-PT (pre-trained checkpoint), RLDX-1-MT-ALLEX, and RLDX-1-MT-DROID (8.1B every, mid-trained for his or her goal platforms).
Serving an 8.1B coverage in a real-robot management loop in actual time is a graph and reminiscence drawback greater than a FLOPs one. RLWRLD benchmarks RLDX-1-PT in simulation towards GR00T N1.5/N1.6 and π₀ [4] / π₀.₅ / π₀-FAST, and likewise evaluates it on the OpenArm real-world benchmark with none platform-specific mid-training.
The mid-trained checkpoints — RLDX-1-MT-ALLEX, RLDX-1-MT-DROID — are then evaluated on their goal platforms. Every benchmark activity is designed to isolate a particular axis of dexterity. RLWRLD compares RLDX-1 towards robust baseline VLA fashions, together with π₀.₅ and GR00T N1.6.
On the OpenArm + Encourage 6-DoF hand platform, RLWRLD has evaluated RLDX-1-PT, with out OpenArm-specific mid-training, to probe how effectively the embodiment-agnostic pre-trained coverage generalizes to a platform it was not specialised for. The benchmark targets versatile intelligence, together with object grounding, instruction understanding, and generalization to unseen environments.
RLDX-1 constantly outperforms the baselines on the OpenArm benchmark for versatile intelligence. RLWRLD specified that π₀.₅ performs higher than GR00T N1.6 on in-domain duties, however its efficiency drops beneath GR00T N1.6 on out-of-domain duties, indicating restricted generalization to unseen settings.
GR00T N1.6 reveals a distinct limitation. It utterly fails on the article identification activity, suggesting that it struggles with fine-grained instance-level object grounding, reported the corporate. In distinction, RLDX-1 maintains balanced efficiency throughout totally different activity varieties with out collapsing on any particular functionality.
These outcomes point out that RLDX-1 just isn’t solely stronger in common success fee, but additionally extra dependable throughout the varied capabilities required for real-world humanoid manipulation, RLWRLD claimed.
Testing RLDX-1 with humanoids
Utilizing the ALLEX humanoid, RLWLRD constructed duties centered on movement consciousness, historical past consciousness, and bodily sign consciousness, evaluated with RLDX-1-MT-ALLEX specialised for the platform.
The outcomes present a big efficiency hole between RLDX-1 and current VLAs. On duties that require specialised useful capabilities, the foremost baselines obtain success charges beneath 30%, whereas RLDX-1 reaches practically 90%.
This means that current VLA fashions nonetheless wrestle when a activity requires greater than generic visual-language understanding, similar to monitoring movement, utilizing historical past, or deciphering bodily indicators. In distinction, RLDX-1 can deal with these capability-specific challenges way more reliably.
RLDX-1-MT-DROID specializes the pre-trained checkpoint to a single-arm Franka Analysis 3 platform with AnySkin tactile and joint torque sensing. RLWRLD evaluates two memory-dependent duties (Swap Cup, Shell Recreation) and two sensory-dependent duties (Plug Insertion, Egg Choose & Place) that train the Reminiscence Module and Physics Module on a non-humanoid embodiment.
What’s subsequent for RLWRLD
Per-task knowledge necessities fluctuate, RLWRLD noticed. Some duties converge rapidly with few demonstrations; others want comparatively in depth post-training.
Relating to the corporate’s long-horizon planning capacity, RLWRLD’s present experiments show memory-dependent decision-making over short-to-medium interplay horizons. Extending this functionality to considerably longer temporal contexts, similar to hour-long interactions, stays an necessary path for future work.
The corporate can be focusing on zero-shot capacity. RLDX-1 achieves robust instruction understanding below our present coaching and adaptation setting in comparison with different frontier VLAs, however its zero-shot generalization as a pre-trained coverage stays an open path.
RLWRLD additionally mentioned it hopes to increase RLDX-1 to the video/world mannequin. RLDX-1 will be prolonged towards video/world modeling, the place the mannequin learns to foretell future visible observations conditioned on language directions and actions. Such an extension may present a stronger foundation for long-horizon planning and action-conditioned creativeness in embodied environments, and it represents a promising path for future work, mentioned the corporate.