

{kind=link}
Each vulnerability has two clocks working. One belongs to the defender racing to seek out it; the opposite to the cyberattacker hoping to seek out it first. For so long as software program has existed, these clocks have favored the attacker, as a result of trendy code is huge, interconnected, and altering each day, whereas safety critiques occur at fastened moments in time. The area between “code shipped” and “code reviewed” is the place danger quietly accumulates.
A couple of months in the past, we got down to reshape that timing. We launched codename MDASH, Microsoft Safety’s multi-model agentic scanning system, constructed to find, validate, and assist remediate software program vulnerabilities end-to-end. The objective was easy to articulate and laborious to execute: take AI-powered vulnerability discovery and remediation functionality from a analysis challenge and switch them into production-grade protection at enterprise scale. That meant going past sample matching and constructing a system that would motive by means of the complexity of proprietary code and platforms like Home windows, Hyper-V, Azure, and identification programs.
Reasonably than depend on any single mannequin, the system orchestrates a panel of specialised AI brokers, every with its personal function in a structured pipeline, so safety groups can floor laborious bugs rapidly and systematically, increasing the attain of human-led assessment. Findings move into Microsoft Defender workflows, the place they are often prioritized alongside menace intelligence and runtime indicators, and into GitHub and Azure DevOps pipelines, the place they are often validated and remediated, a closed loop connecting discovery, validation, proof, and repair throughout the Microsoft stack.
After we launched the system, it topped a number one business benchmark. That was the announcement, and the beginning line. Within the weeks since, the system has moved from early functionality validation into lively use by Microsoft engineering groups throughout Home windows, Azure, and identification programs, utilized as a part of actual safety workflows somewhat than remoted testing environments. This publish explores what we’ve constructed since, the teachings we’ve discovered from turning analysis right into a production-quality system, and the alternatives forward as we concentrate on delivering real-world safety affect.
From the lab into the pipeline
Essentially the most significant change since launch is the place the system is getting used. Engineering groups throughout Home windows, Azure, and identification programs at the moment are making use of the system as a part of their safety workflows, working it alongside present processes and critiques, focusing on it on the surfaces which can be hardest to audit manually and have traditionally required probably the most effort to cowl. The objective is to make use of AI-driven evaluation to go deeper, earlier, and throughout a broader set of targets than conventional approaches permit.
The surfaces in scope are among the many most advanced Microsoft builds:
- Home windows, the kernel, Hyper-V, and the networking stack
- Azure, virtualization and core infrastructure companies
- Identification, Lively Listing Area Providers
These will not be simple targets. They’re the deep layers of the platform, parts the place reasoning about code requires understanding kernel calling conventions, object lifetime invariants, and belief boundaries that no language mannequin encountered in its coaching information. A single missed flaw at this layer can have outsized penalties. The system will not be changing safety groups working at this depth. It’s giving them significant attain into territory they may not cowl alone.
Codename MDASH has enabled our safety workforce to carry out vulnerability searching on the scale of Home windows with a a lot greater depth of study than was beforehand potential.”
—Home windows safety workforce (kernel, Hyper-V, networking stack)
That is additionally the place the system matches into Microsoft’s present DevSecOps story. It isn’t a standalone scanner bolted onto the aspect of engineering—it plugs into the instruments groups already use. Validated findings floor as code scanning alerts in GitHub Superior Safety (GHAS), showing inline on pull requests and within the repository’s safety tab so engineers triage them in the identical place they assessment code. The identical findings move into Azure DevOps, the place they’ll gate pipeline builds and open work objects for remediation, and into Microsoft Defender, the place they’re prioritized alongside menace intelligence and runtime indicators. Discovery is just the entry level: as a result of a discovering travels the identical path as each different code change—with an proprietor, a pull request, and a repair on the opposite aspect—it lands as actionable engineering work somewhat than stalling in a backlog. The impact is to strengthen the software program improvement lifecycle from the within, to not add yet another device for groups to have a tendency.
This month’s set of discoveries
The measure of any safety system is what it catches. This month’s Patch Tuesday cohort features a set of vulnerability discoveries throughout the Home windows ecosystem, Hyper-V, the Home windows kernel, Lively Listing Area Providers, Distant Desktop Consumer, HTTP.sys, DNS Consumer, and DHCP Consumer, spanning exploit courses together with distant code execution, elevation of privilege, and data disclosure.
The vary of assault vectors is important. A number of findings contain high-severity distant code execution vulnerabilities in core infrastructure layers which can be tough to scrutinize utilizing guide approaches alone. Others floor extra delicate points, comparable to privilege escalation by means of DNS parts and data disclosure by means of DHCP shopper conduct, that mirror the ability of code-centric reasoning utilized throughout many targets concurrently. Every was recognized earlier than exploitation, in areas of the codebase that may historically demand vital guide effort to assessment.
| CVE ID | Element | Kind | Exploit Class | CVSS (Widespread Vulnerability Scoring System) |
|---|---|---|---|---|
| CVE-2026-45607 | Home windows Hyper-V | Out-of-bounds Learn | Distant Code Execution | 8.4 |
| CVE-2026-45641 | Home windows Hyper-V | Kind Confusion | Distant Code Execution | 8.4 |
| CVE-2026-47652 | Home windows Hyper-V | Heap-based Buffer Overflow | Distant Code Execution | 8.2 |
| CVE-2026-41108 | Home windows DNS Consumer | Heap-based Buffer Overflow | Elevation of Privilege | 7.0 |
| CVE-2026-45608 | Home windows DHCP Consumer | Out-of-bounds Learn | Info Disclosure | 6.8 |
| CVE-2026-45634 | Home windows DHCP Consumer | Out-of-bounds Learn | Info Disclosure | 5.5 |
| CVE-2026-45648 | Home windows Lively Listing Area Providers | Stack-based Buffer Overflow | Distant Code Execution | 8.8 |
| CVE-2026-47289 | Distant Desktop Consumer | Heap-based Buffer Overflow | Distant Code Execution | 8.8 |
| CVE-2026-45657 | Home windows Kernel | Use-after-free | Distant Code Execution | 9.8 |
| CVE-2026-47291 | HTTP.sys | Integer Overflow | Distant Code Execution | 9.8 |
Past the headline: What the engineering work taught us
How the system improved
To enhance a system, you need to measure it. CyberGym, an business benchmark constructed on 1,507 real-world vulnerabilities, gave us a technique to iterate rapidly and see precisely the place we have been getting higher.
For the reason that preliminary announcement, we developed the system considerably: new capabilities added, and the complete pipeline rebuilt based mostly on buyer suggestions, CyberGym analysis outcomes, and in depth inner testing. The newest model has achieved 96.5% (any crash) on CyberGym, together with each goal and non-target vulnerabilities.
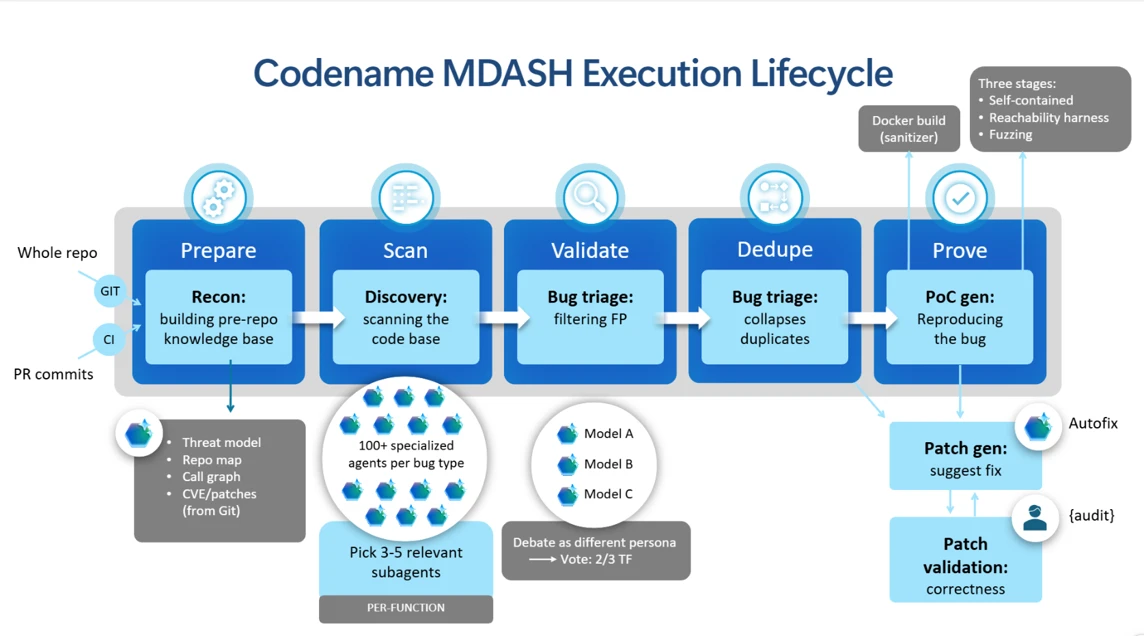
The positive factors have been concentrated within the earliest phases of the pipeline: put together and scan. These are foundational. Enhancements there immediately elevate the standard of all the things downstream, comparable to validation and proof era, the place exact understanding of the codebase and correct exploration are important. Particularly:
- Sharper scoping. The system now extra clearly distinguishes the code below audit from contextual code, defining dependencies based mostly on their function somewhat than their origin. Later phases can concentrate on what issues, enhancing each effectivity and sign high quality.
- Extra complete menace modeling. The system has a fuller view of a goal repository’s assault floor, significantly in figuring out entry factors for untrusted enter. This contains improved recognition of maintainer-defined entry factors, comparable to fuzz harnesses, that will reside exterior the first codebase however are important for assessing reachability. The system is best positioned to find out which findings are genuinely exploitable.
- A extra dependable name graph. The correctness and robustness of the decision graph, a core construction used throughout a number of pipeline phases, has been strengthened, enhancing the system’s capability to motive about code interactions, particularly for reachability evaluation throughout validation.
- Smarter routing to specialised brokers. A brand new routing mechanism filters out clearly irrelevant brokers whereas preserving robust candidates, lowering pointless computation whereas sustaining protection and permitting the system to scale throughout numerous targets.
The precept behind all of it’s the identical: the mannequin is one enter, the system round it’s the product. Higher understanding within the early phases produces extra correct conclusions later, no matter which mannequin is doing the reasoning.
Understanding the remaining 3.5%
Whereas the 96.55% rating beforehand introduced, represents a major step ahead, the system missed 3.5% of circumstances, 52 duties in whole.
We analyzed which pipeline stage contributed to every miss:
- Scan stage: 8 circumstances (15.4%), did not determine the supposed discovering.
- Validate stage: 10 circumstances (19.2%), incorrectly flagged supposed findings as false positives.
- Show stage: 34 circumstances (65.4%), did not generate a working proof-of-concept.
The next highlights the primary failure causes at every stage.
Scan stage failures
Incorrect scope from ambiguous descriptions. In some circumstances, the scope generated through the put together stage didn’t embrace the information or features containing the supposed vulnerability. This happens when bug descriptions are too common, particularly in repositories with a number of modules, making exact localization tough. In arvo:53536, the goal bug description reads:
“A stack-buffer-overflow happens within the code when a tag is discovered and the output dimension will not be checked to make sure it’s inside the bounds of the buffer.”
It identifies the vulnerability kind however provides little steerage on the place to look in a big codebase.
Missed prioritization of weak parts. The system prioritizes which information and features to investigate first and may typically de-emphasize much less apparent parts. In arvo:23547, the vulnerability resides in a lexer/parser part, however the system prioritized different C code paths as an alternative.
Validate stage failures
Hypothetical descriptions and code misinterpretation. Scan outcomes typically embrace hypothetical descriptions of vulnerabilities somewhat than concrete execution paths. When the validate stage can not verify a concrete path in code, it might reject the discovering.
Within the CyberGym benchmark case “arvo:3569,” the scan stage accurately recognized a use-after-free vulnerability, however the validate stage concluded there was no possible path to free the pointer, and rejected it. The scan-stage discovering included an outline like: “danger if any destructor or cleanup code makes an attempt to free…” That framing left the validate stage with out sufficient proof to verify reachability.
Show stage failures
Extremely structured enter necessities. Some targets require advanced, structured binary inputs, IVF/AV1, WPG, fonts, PDFs, the place crafting inputs that each fulfill format validation and attain the weak code path is inherently tough, making dependable proof-of-concept era difficult.
Fuzzing till timeout. For targets requiring extremely structured inputs, the system typically tried fuzzing-based approaches that discovered crashes however did not generate inputs accepted as legitimate by the goal inside time constraints.
Surroundings mismatch. In some circumstances, the system reproduced crashes regionally however these didn’t switch to the analysis harness, because of mismatches in construct configuration, incorrect goal choice, or execution paths that differed from the supposed setup.
Construct complexity and time constraints. In a number of circumstances, the construct course of failed, ran too lengthy, or exceeded the agent’s execution funds, stopping proof-of-concept era.
Paths to enchancment
Integrating fuzzing pipelines. The show stage is the first bottleneck in each benchmark and real-world settings. We’ll combine the system with present fuzzing ecosystems comparable to OSS-Fuzz, permitting us to reuse construct pipelines somewhat than reconstruct them and to attract on present seed corpora for simpler proof era. This strategy was not utilized throughout CyberGym analysis, as it might implicitly reuse identified proofs-of-concept, however will probably be adopted for real-world targets.
Extending evaluation past supply code. Some POC era failures have been because of restricted help for non-traditional code artifacts. Whereas the system handles standard languages comparable to C/C++ effectively, it doesn’t but totally help artifacts generated by instruments like lex/yacc. We’re extending our evaluation to cowl these circumstances and broaden our general protection.
Enhancing agent reasoning and output high quality. Failures in scan and validate phases typically stem from speculative or incomplete reasoning. We’ll refine agent directions, implement structured outputs, and add validation checks to scale back ambiguity and enhance reliability.
What newer fashions add
To isolate the affect of system-level enhancements, our major analysis (Exp-0, baseline) deliberately used the identical mannequin configuration because the earlier CyberGym benchmark, attributing positive factors on to pipeline enhancements somewhat than mannequin advances. Fashionable basis fashions proceed to evolve, nonetheless, and we ran further experiments on the 52 beforehand failed circumstances to know what stronger fashions contribute.

Experiment 1: Newer OpenAI fashions for bug discovery, Claude Opus 4.6 for show
- Configuration: Put together / Scan / Validate: GPT-5.4, GPT-5.5, GPT-5.4-mini, GPT-5.3-codex. Show: Claude Opus 4.6.
- End result: 19 of 52 circumstances solved (36.5%, any crash). Assuming no regressions on beforehand solved circumstances in Exp-0, projected success price: 97.8% (any crash).
The first acquire comes from higher-quality scan-stage findings. In comparison with Exp-0 baseline on this dataset, outputs are much less hypothetical and extra exact, with concrete execution particulars that enhance each validation accuracy and downstream proof era.
Within the CyberGym benchmark case “arvo:3569,” the baseline produces a obscure description, “danger if any destructor or cleanup code makes an attempt to free…”, whereas GPT-5.5 identifies a selected execution path: “line 210 calls pj_default_destructor (P,…), which frees P->params, Q (= P->opaque).” That grounded description provides validation a transparent path to motive about reachability.
GPT-5.5 additionally exhibits improved alignment between detected bugs and their corresponding widespread weak point enumeration (CWE) classes, contributing to simpler proof era.
Experiment 2: GPT-5.5 / GPT-5.5-cyber for show, utilizing bug discovery from Experiment 1
- Configuration: Put together / Scan / Validate: Bug discovery outputs from Experiment 1. Show: GPT-5.5 / GPT-5.5-cyber.
- End result (GPT-5.5): 21 of 52 circumstances solved (40.4%, any crash). Assuming no regressions on beforehand solved circumstances in Exp-0, projected success price: 97.9% (any crash).
- End result (GPT-5.5-cyber): 23 of 52 circumstances solved (44.2%, any crash). Assuming no regressions on beforehand solved circumstances in Exp-0, projected success price: 98.1% (any crash).
Each GPT-5.5 and GPT-5.5-cyber discovered extra crashes than Claude Opus 4.6 within the show stage. The acquire is significant however extra modest than the enhancements noticed in scan. This dataset alone will not be enough to conclude these fashions are constantly stronger throughout all proof-of-concept era duties.
Three distinct methods emerged throughout all fashions within the show stage:
- Code-based, reasoning over code paths to craft inputs.
- Fuzzing-based, looking the enter area for crashes.
- Customized instrumentation-based, exposing vulnerability-relevant variables and utilizing them as suggestions indicators to information enter era.
All three fashions utilized all three methods throughout the 52 circumstances however differed by which targets they utilized them to, and that choice drove variations in final result. In arvo:61902, solely GPT-5.5-cyber generated a working proof-of-concept, making use of a customized instrumentation-based strategy that reframed the duty as a hill-climbing downside: lowering “perceive the codec effectively sufficient to craft adversarial audio” to “search till this worth exceeds 128.”
Seeing previous the rating
CyberGym has been a useful platform for fast iteration, steady analysis, and measurable progress. By way of this suggestions loop, the system has superior dramatically, reaching 96.5% efficiency on the benchmark, with newer fashions already contributing a further 1%-2% enchancment past that baseline. Reaching this degree of efficiency in such a brief interval is a robust indicator of the underlying structure, analysis course, and engineering rigor driving the hassle.
On the identical time, we’re cautious to interpret these outcomes appropriately. A 96.5% CyberGym rating demonstrates that the system can motive successfully over a broad and difficult set of identified vulnerabilities. Equally vital, it highlights a possibility to broaden our analysis framework. Actual-world vulnerability discovery entails ambiguity, incomplete data, and always evolving software program ecosystems—dimensions that reach past any fastened benchmark. That is exactly what makes the subsequent section of the work so thrilling: making use of these capabilities to more and more life like environments and pushing the frontier from benchmark excellence to real-world affect.
The place we go subsequent
We’ll chart our course in two instructions.
First, we’re advancing the system to function in real real-world environments, focusing on cost-efficient discovery of beforehand unknown vulnerabilities, mixed with built-in capabilities to triage and repair points at scale. Discovering the bug is half the job. Closing it’s the different half.
Second, we see a transparent alternative to advance the benchmark to seize the complexity, ambiguity, and end-to-end workflows of how real-world vulnerability discovery truly occurs.
The mannequin variation experiments level towards the identical conclusion: the system and the fashions enhance in complementary methods. To show our pipeline positive factors weren’t merely mannequin positive factors, we held the mannequin configuration fixed within the core analysis, then examined newer fashions individually. The extra positive factors have been actual, particularly within the precision of scan-stage findings. That isn’t a complication in deciphering the outcomes. It’s a roadmap.
Protection at AI pace
Come again to the 2 clocks. The arc of this work is the story of the second they switched locations: from a defender racing to catch up, to a defender with AI-driven evaluation reaching deeper into manufacturing code, earlier within the course of, throughout a broader floor than any guide program might maintain.
That’s what defending at AI pace means. Not sooner scanning in isolation, however a posture that retains tempo with the best way software program is definitely constructed and shipped at the moment, the place each enchancment to the pipeline makes the subsequent discovering extra exact, and the system and the fashions develop stronger collectively.
Be taught extra
Codename MDASH is simply getting began. We want you with us for the subsequent chapter.
Signal as much as comply with codename MDASH and be part of the non-public preview. To go deeper on the engineering behind codename MDASH, discover our technical weblog sequence.
To be taught extra about Microsoft Safety options, go to our web site. Bookmark the Safety weblog to maintain up with our skilled protection on safety issues. Additionally, comply with us on LinkedIn (Microsoft Safety) and X (@MSFTSecurity) for the most recent information and updates on cybersecurity.