

{kind=link}
Just a few years in the past, selecting an AI mannequin was comparatively easy. You most likely didn’t even know the time period AI mannequin as ChatGPT was used synonymously with it. It was the apparent (and possibly the one) selection on the time.
However occasions have modified. ChatGPT is not the one-stop for AI fashions. Claude, Grok, Gemini, Deepseek, Qwen, Kimi, Llama… and lots of extra can be found to make use of. This selection was alleged to empower the customers. However this is actuality has had the alternative impact!
It’s because these fashions feel and look the identical (the identical chatbot interface) and are evolving at a comparable tempo. So the actual query is not “Which mannequin is the very best?”
It’s: Which mannequin is the very best for me?
And primarily based on what I’ve seen, that is the place most individuals get it fallacious.
The Downside
ChatGPT can write polished emails for you. However so can Claude, DeepSeek, Gemini, and nearly each different AI mannequin in the present day.
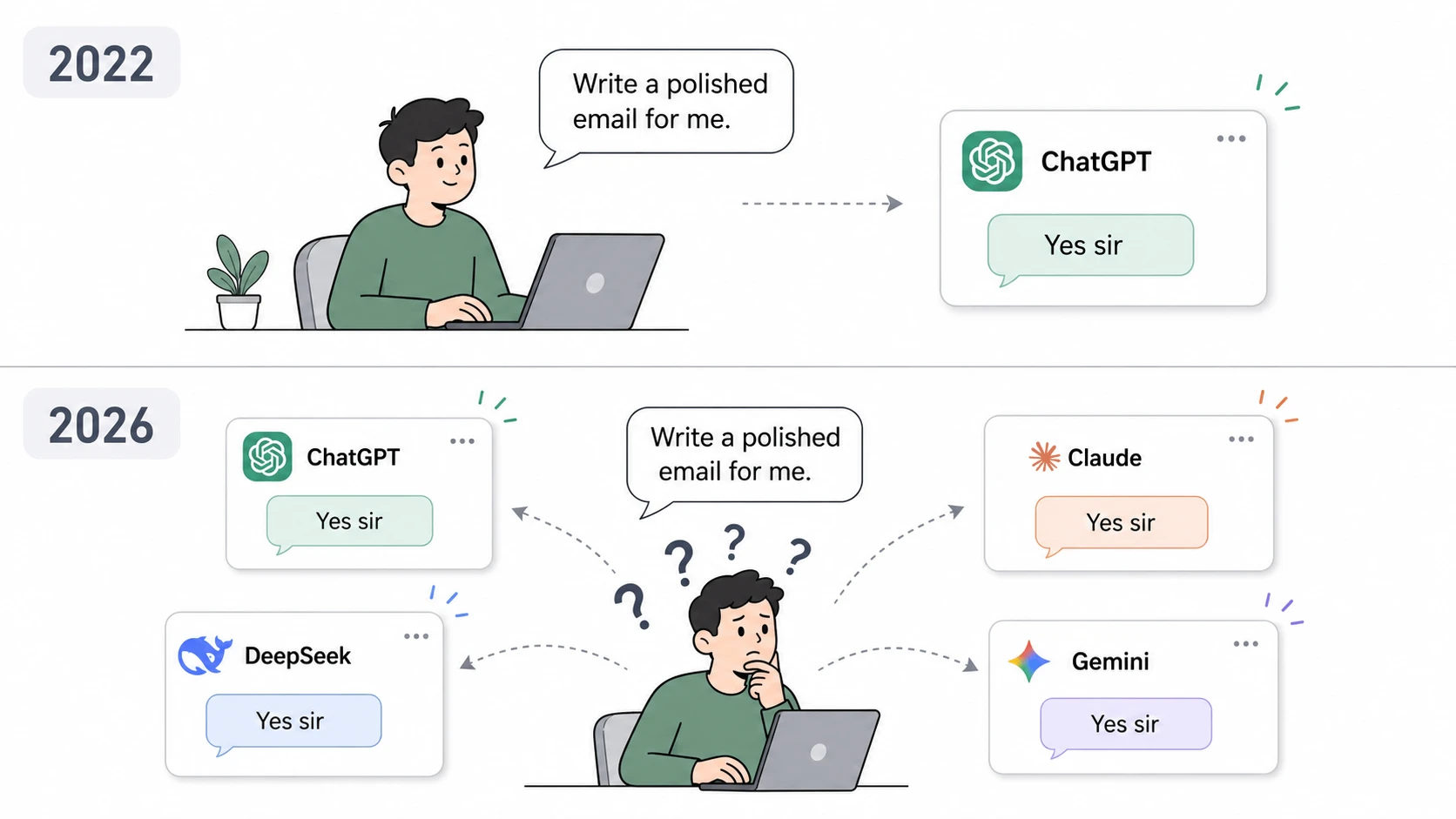
That’s the drawback.
On the floor degree, these fashions are interchangeable. They’ll all summarize paperwork, clarify ideas, write code, and reply questions. For the typical consumer, the variations are usually not instantly apparent.
So folks begin selecting fashions for the fallacious causes:
- Their pal beneficial it.
- It went viral on social media final week.
- It topped an AI benchmark (which isn’t all the time a very good indicator)
- It was the primary mannequin they tried.
- It occurs to be the default choice in an app they already use.
None of those are horrible causes. However they aren’t significantly considerate ones both.
The higher approach to decide on an AI mannequin is to cease asking which one is finest total and begin asking what you really want the mannequin to do. However earlier than going over what to do when selecting a mannequin, let’s check out a number of issues to not do.
Benchmarks: The Smoke Display screen
Most individuals begin utilizing a chatbot for one major motive. Perhaps they need assistance writing, coding, researching, or brainstorming.
And for those who’re right here for better of the very best in a particular area you need to use this desk as a information for selecting your mannequin:
Now if the earlier desk was capable of affect your mannequin selection, that is the precise drawback I used to be referring to.
As a result of, these outcomes have been obtained utilizing the flagship model of the listed fashions, that are all paid. This may not be an issue for many who have a subscription of those fashions, however for these with out, right here is how the equation modifications:
- Claude Opus: Can’t be accessed with no paid subscription.
- GPT-5.5 Pondering: Free customers get 10 GPT-5.5 messages each 5 hours, then chats change to the mini mannequin: Pondering entry is way more restricted than paid tiers.
- Gemini 3.1 Professional: Google makes use of compute-based limits that refresh each 5 hours till a weekly cap is reached: larger entry to Gemini 3.1 Professional is tied to Google AI Professional/Extremely plans.
- GPT Picture 2: ChatGPT Free contains picture era, however OpenAI lists it as restricted and slower.
You may clearly see how these fashions are not a selection for those who’re are missing a subscription.
Contemplating that a lot of the customers of an AI mannequin are utilizing the free tier, the disparity within the service mannequin is noteworthy.
Observe: This could provide you with a warning for any benchmark or metric for a mannequin. It’s because most of those are obtained utilizing the SOTA variants of the fashions that are normally paid. Their free variants — go away lots to be desired.
The Perspective: What works for Us?
Selecting a mannequin primarily based solely on benchmark rankings is lots like selecting a automobile primarily based solely on its high velocity. The quantity could also be right, however you may be in search of security and luxury (making it sort of pointless).
In observe, components like pricing, fee limits, context home windows, ecosystem integrations, and even response model desire usually have a much bigger impression on the consumer expertise than a number of share factors on a leaderboard.

That is why two folks can have a look at the very same benchmark outcomes and nonetheless arrive at fully totally different mannequin decisions.
- A software program engineer with a AI mannequin subscription
- A scholar utilizing free-tier instruments
- A marketer already embedded in Google’s ecosystem
These are fixing totally different issues below totally different constraints.
So earlier than deciding which mannequin to make use of, it helps to zoom out from the leaderboards and take into account the components that truly form your day-to-day expertise.
The Selection: Your Personal Framework
As a substitute of counting on a benchmark or a framework somebody posted on-line, we’ll construct our personal analysis metric.
Begin with one thing easy: checklist the three most typical duties you utilize a chatbot for.
Your precise duties.
For me, that may be:
- Writing a primary draft of an article.
- Evaluating a number of choices (on Amazon) and recommending one.
- Studying one thing new via a back-and-forth dialog.
The purpose is to floor the analysis in our personal actuality.
You don’t care if a mannequin tops a benchmark leaderboard if it fails on the stuff you really want it to do.
- Claude may be the neatest mannequin on paper, however for those who want picture era and it may possibly’t create photos, it’s ineffective.
- Gemini may rating exceptionally nicely on coding benchmarks whereas being horrible at making buying choices makes it a horrible selection.
So as a substitute of asking “Which mannequin is the very best?”, we’re asking a a lot narrower query:
Which mannequin is the very best for me?
When you’ve picked your duties, create a easy scoring rubric.
For every job, fee the mannequin on a scale of 1 to five. The precise standards don’t matter. Perhaps you care about accuracy. About velocity, or possibly you care about how usually the mannequin misunderstands directions.
Simply be sure to’re measuring the identical issues throughout each mannequin. Then run every job via each chatbot you’re evaluating.
My Selection
In my case upon analysis the highest 3 fashions proper now on my workload gave me the next outcomes:
| Activity | GPT | Claude | Gemini |
| Writing | ★★★★★ | ★★★★☆ | ★★☆☆☆ |
| Analysis | ★★★★★ | ★★★★☆ | ★★★★☆ |
| Studying | ★★★★☆ | ★★★★☆ | ★★★★☆ |
| Ultimate Rating |
14/15 Winner |
12/15 | 10/15 |
GPT-5.5 got here out forward for my workload as a result of it was constantly helpful throughout all three duties.
Conclusion
There is no such thing as a universally finest AI mannequin. The precise selection is dependent upon your desire and work. Benchmarks can information you, however they can not make that call for you.
The most secure strategy is easy: check a number of fashions on three duties you recurrently carry out, rating them constantly, and decide the one which wins in your use case. That retains your choice grounded in proof, not hype.
I focus on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, information evaluation, and data retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and luxuriate in expert-curated content material.