

{kind=link}
The significance of understanding a mannequin’s origins has been a frequent subject of debate amongst researchers and business specialists, and our personal AI analysis confirms that AI provide chain safety stays a weak hyperlink. Monitoring the place fashions come from, referred to as “mannequin provenance,” can be important for the way forward for AI mannequin and provide chain safety. To assist with this, we’re releasing our new Mannequin Provenance Equipment as an open supply software.
Consider the Mannequin Provenance Equipment as a DNA take a look at for AI fashions. The present AI provide chain, from datasets used for coaching to the deployment of a completed mannequin, is opaque. Documentation on open mannequin repositories might be faked, and necessary particulars within the metadata might be eliminated or modified. Very similar to a DNA take a look at reveals organic origins, the Mannequin Provenance Equipment examines each metadata and the precise realized parameters of a mannequin (like a novel genome that includes a mannequin), to evaluate whether or not fashions share a standard origin and establish indicators of modification. This, mixed with a structure that defines provenance linkages, are necessary steps towards offering evidence-based assurance that the AI you deploy is what it says it’s.
Latest developments present simply how complicated and interconnected AI provide chains have develop into, with groups drawing on a mixture of proprietary methods, open fashions, and third-party parts. Instances like Cursor’s Composer 2 that had been partly constructed on Kimi 2.5, together with broader business adoption of worldwide developed fashions, spotlight the necessity for clear provenance so organizations could make absolutely knowledgeable choices about tips on how to handle any dangers with AI they develop and deploy.
Why this Issues
Many organizations use AI fashions downloaded from open supply mannequin repositories like HuggingFace, which at the moment hosts over 2 million fashions. After downloading and fine-tuning these fashions, organizations usually fail to maintain a transparent report of the adjustments made. Consequently, there may be normally no technique to monitor how the mannequin was modified throughout its improvement. Whereas mannequin repositories have hosted steerage on the significance of mannequin playing cards and metadata, earlier analysis about mannequin upkeep and revisions point out that mannequin upkeep varies considerably, which can influence downstream customers of these fashions.
Past shortcomings in documentation, there may be additionally usually no verification of claims for fashions hosted on these repositories; builders can declare a mannequin is skilled from scratch, but it surely may very well be a modified copy of one other mannequin. Complicating the difficulty additional: fashions may embody biases in coaching information, vulnerabilities within the mannequin’s structure, or licensing caveats from their creators.
When organizations don’t know the place their AI fashions truly come from, they’re flying blind on safety, compliance, and legal responsibility. With out perception into mannequin provenance, there are implications on quite a few components:
- Poisoned or susceptible fashions: An enterprise might deploy a mannequin that has been poisoned or is susceptible to manipulation. If unaccounted for, these vulnerabilities can proceed to propagate, whether or not they have an effect on an inside chatbot, an agent software, or a customer-facing software. Equally, an enterprise might deploy a mannequin that has biases in its coaching information that make it a poor selection for its use case or make it prone to manipulation. The vulnerabilities are inherited and would persist in generative and agentic purposes. With out provenance, organizations don’t have any straightforward technique to hint an incident again to its root trigger, and no technique to decide which different fashions of their stack are additionally affected.
- Licensing and regulatory danger: Regulatory frameworks are more and more requiring organizations to doc how AI methods are constructed and the place their parts originate. The European Union (EU) AI Act, for instance, mandates documentation of coaching information, traits of coaching methodology, and danger assessments for “high-risk methods.” In the meantime, the Nationwide Institute for Requirements and Know-how (NIST)’s AI Danger Administration Framework identifies third-party AI element dangers as a key space for organizational governance. As these necessities evolve, organizations might face downstream compliance gaps. Furthermore, some open weight fashions even have restrictive licensing, so if a mannequin seems to be a spinoff of 1 with restrictive licensing (e.g., one skilled in a jurisdiction topic to export controls; others might impose restrictions primarily based on firm measurement), there could also be different authorized or compliance issues.
- Provide chain integrity danger: Fashions might be mislabeled, repackaged, or uploaded with out attribution, and a mannequin card can declare to be “skilled from scratch,” however it might truly be a modified copy of one other mannequin. With out technical verification of provenance, organizations are trusting claims that nobody has validated.
- Incident response danger: If a mannequin experiences a safety problem or exhibits proof of manipulation, it is going to make it tougher to remediate and resolve points should you don’t have perception into the mannequin’s lineage. Organizations wouldn’t have the ability to decide whether or not the issue is the mannequin itself, a associated mannequin, its father or mother, or one thing else that’s launched throughout fine-tuning. At this time, it is a guide and tedious investigatory course of.
When contemplating tips on how to strategy mannequin provenance, the problem for a lot of organizations is that fashionable mannequin households share an identical architectures. Fashions from Meta, Alibaba, DeepSeek, and Mistral use the identical constructing blocks equivalent to grouped-query consideration, rotary positional embeddings, and Root Imply Sq. Normalization (RMSNorm). A config file can describe the structure but it surely can not inform whether or not the weights had been copied from one other mannequin or skilled independently.
How Mannequin Provenance Equipment works
Mannequin Provenance Equipment is a Python toolkit and command-line interface (CLI) that that may decide whether or not two AI fashions share a standard origin by analyzing structure metadata, tokenizer construction, and the realized weights themselves, utilizing a tiered technique that begins with quick structural checks and progresses to deeper weight-level evaluation when metadata alone is inconclusive.
Mannequin Provenance Equipment generates a wealthy “fingerprint” for every mannequin utilizing metadata indicators, tokenizer similarity, and weight-level identification indicators equivalent to embedding geometry, normalization layers, vitality profiles, and direct weight comparisons. These indicators are then in comparison with produce a single provenance rating that displays whether or not two fashions share a standard origin or coaching lineage. The system works on any transformer mannequin with downloadable weights and progresses in two phases:
Stage 1 is a quick architectural screening, the place Mannequin Provenance Equipment compares mannequin configurations and structural metadata earlier than loading any weights. If two fashions share an identical structure specs, they are often confidently categorised as associated, enabling speedy decision for a big portion of circumstances with excessive precision.
When metadata is ambiguous, equivalent to when two fashions use the identical architectural template however might have been skilled independently, the pipeline progresses to Stage 2: weight-level evaluation. Provenance Equipment extracts 5 complementary indicators from the precise mannequin weights:
- Embedding Anchor Similarity (EAS): Compares the geometric relationships between token embeddings. This construction is exclusive to a coaching run and survives fine-tuning.
- Embedding Norm Distribution (END): Analyzes the distribution of embedding magnitudes, which encode phrase frequency patterns realized throughout coaching.
- Norm Layer Fingerprint (NLF): Reads the tiny normalization layers that act as a steady fingerprint as a result of they continue to be steady throughout fine-tuning.
- Layer Vitality Profile (LEP): Compares normalized vitality curve distributions throughout the depth of the community. Completely different coaching runs produce completely different vitality distributions even when the structure is an identical.
- Weight-Worth Cosine (WVC): Instantly compares weight values between a subsample of corresponding layers. Independently skilled fashions would seemingly exhibit basically zero correlation right here.
These indicators are mixed right into a single identification rating utilizing empirically calibrated weights. When any sign can’t be computed (e.g., when fashions have completely different layer counts), it’s excluded and the remaining indicators compensate routinely.
Whereas we compute and assess tokenizer indicators—vocabulary overlap evaluation (VOA) and tokenizer characteristic vector (TFV)—for diagnostics, they don’t affect provenance assessments. Many independently skilled fashions share tokenizers (e.g., StableLM and Pythia each use the GPT-NeoX tokenizer and might rating as “related” regardless of having no weight lineage) and together with them would create false positives.
Mannequin Provenance Equipment additionally options two modes
In examine mode, take any two fashions (from Hugging Face or native checkpoints) and get an in depth breakdown of their similarity throughout metadata, tokenizer construction, and most significantly, weight-level indicators together with a remaining composite rating that displays shared lineage.
In scan mode, begin with a single mannequin and match it towards a database of identified fingerprints to floor the closest lineage candidates, turning provenance right into a search downside.
Alongside this launch, we’re additionally transport an preliminary fingerprint database protecting ~150 base fashions throughout 45+ households and 20+ publishers, starting from 135M to 70B+ parameters—giving scan mode a powerful basis to establish real-world lineage relationships.
Outcomes
We evaluated Mannequin Provenance Equipment towards a 111-pair benchmark (55 related, 56 dissimilar fashions) designed to incorporate tough real-world circumstances: aggressive distillation, quantization throughout codecs, cross-organization fine-tuning, LoRA merging, continued pretraining with vocabulary extension, same-tokenizer traps, and unbiased reproductions of common architectures. Outcomes are proven in Desk 1 beneath:
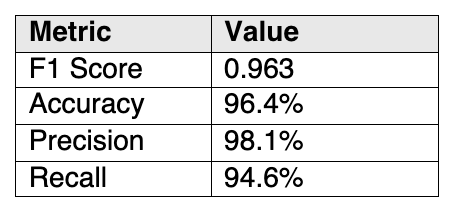 Desk 1. Outcomes of working Mannequin Provenance Equipment towards a 111-pair benchmark at a similarity-dissimilarity threshold of 0.70 (on 0-1 scale)
Desk 1. Outcomes of working Mannequin Provenance Equipment towards a 111-pair benchmark at a similarity-dissimilarity threshold of 0.70 (on 0-1 scale)
In analysis, Mannequin Provenance Equipment precisely recognized:
- Normal derivatives (fine-tuning, quantization, alignment) — 100% recall
- Cross-organization derivatives (fashions fine-tuned and launched below a distinct title by a distinct group) — 100% recall
- Identical-tokenizer traps (independently skilled fashions that occur to share a tokenizer)— 100% specificity
- Unbiased reproductions (similar structure, completely different coaching equivalent to open_llama vs. Llama-2) — accurately recognized as unrelated
Solely 4 out of 111 pairs had been misclassified, all involving excessive architectural transformations: distilling a 12-layer mannequin with 768 hidden dimensions right down to 4 layers whereas halving the hidden dimensions, or utterly rebuilding a vocabulary for domain-specific continued pre-training. These symbolize elementary limits of pairwise weight comparability and should not thought-about pipeline bugs.
The chart beneath (Determine 1) exhibits the distribution of Mannequin Provenance Equipment scores throughout all 111 benchmark pairs. Associated mannequin pairs (inexperienced) cluster close to 1.0, whereas unrelated pairs (crimson) cluster nicely beneath the 0.70 threshold. The hole between the 2 distributions is what makes the system dependable, as there may be little or no overlap within the determination area.
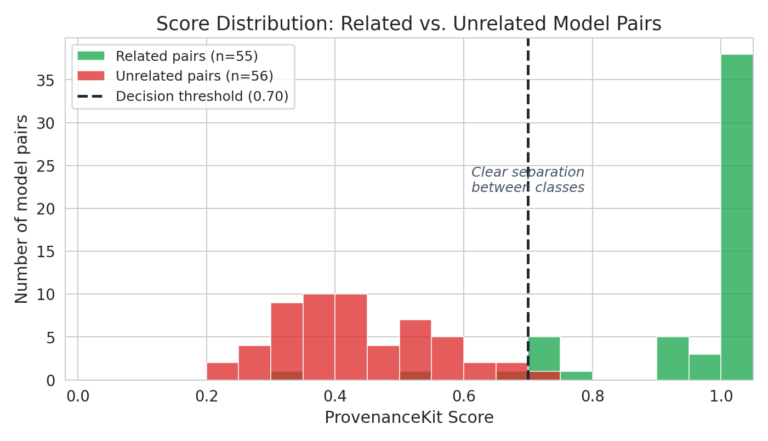 Determine 1. Mannequin Provenance Equipment efficiency towards benchmarked units
Determine 1. Mannequin Provenance Equipment efficiency towards benchmarked units
Under, see an instance (Determine 2) that compares two DeepSeek household fine-tuned fashions utilizing Mannequin Provenance Equipment, which demonstrates related lineage throughout all metadata- and weight-based options:
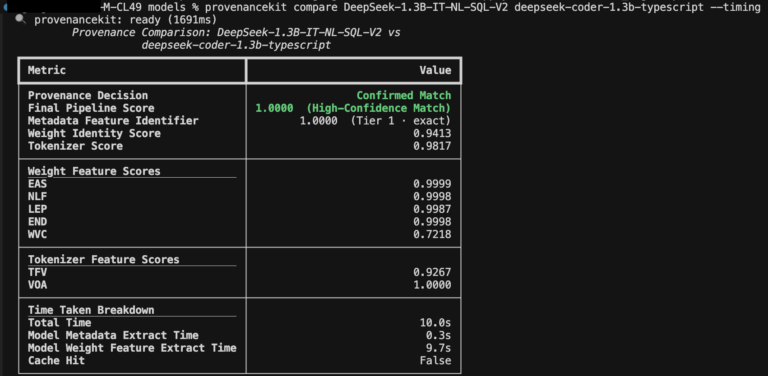 Determine 2. Evaluating two DeepSeek fine-tuned fashions having shared lineage
Determine 2. Evaluating two DeepSeek fine-tuned fashions having shared lineage
Conclusion
As fashions are repeatedly fine-tuned, distilled, merged, and repackaged, mannequin recordsdata have developed previous static property. Lineage turns into tougher to trace and simpler to obscure, and answering the query of “what are the origins of this mannequin?” requires extra nuanced approaches. Our launch of Mannequin Provenance Equipment is a step in the direction of offering an evidence-based strategy to mannequin provenance.
Getting Began
 Determine 3. Screenshot of Mannequin Provenance Equipment’s command line interface
Determine 3. Screenshot of Mannequin Provenance Equipment’s command line interface
Getting began with Mannequin Provenance Equipment is straightforward: all the pipeline runs on CPU and might scale to mannequin measurement. Architectural matches resolve in milliseconds and extracted options are cached for reuse.
Mannequin Provenance Equipment is accessible at this time.
Try the repository on Github right here: https://github.com/cisco-ai-defense/model-provenance-kit
Our dataset of base mannequin fingerprints is accessible on Hugging Face right here: https://huggingface.co/datasets/cisco-ai/model-provenance-kit