

{kind=link}
When engineering groups at Slack, Reddit, Canva, Airbnb, Shopify, and Uber must ship code with confidence, they depend on Buildkite. As a CI/CD platform, Buildkite orchestrates complicated construct, take a look at, and deployment pipelines for a number of the most demanding engineering organizations on the earth. It handles all the pieces from routine code commits to synthetic intelligence (AI) model-training workloads, processing over 50 billion requests per 30 days.
On the coronary heart of Buildkite’s take a look at orchestration portfolio is Take a look at Engine, a specialised analytics product designed to assist engineering groups perceive and optimize their take a look at suites at scale. Take a look at Engine aggregates outcomes throughout hundreds of builds, flags flaky checks, runs parallel take a look at execution throughout machine fleets, and delivers interactive analytics on take a look at execution information. It helps arbitrary metadata tagging for dimensions like occasion sort, structure, language model, cloud supplier, and have flags.
The problem? Delivering all of this in actual time, throughout a number of enterprise tenants, at a quantity that may stress even probably the most sturdy information infrastructure. On this put up, we discover how Buildkite makes use of Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink to energy Take a look at Engine’s streaming-first analytics structure at scale.
The issue: When scale breaks conventional architectures
Buildkite’s Take a look at Engine should ingest and serve analytics on take a look at telemetry from hundreds of distributed pipelines concurrently, for a number of enterprise clients. The size is unforgiving: 50 billion take a look at executions per 30 days, 500K occasions per second at peak ingestion, and webhook payloads reaching 21 MB.
The architectural evolution and its limits
The unique Rails and PostgreSQL stack couldn’t maintain this development. In 2024, the crew re-architected round a distributed streaming layer, a stateful stream processor for pre-aggregations, and a number of specialised shops: a key-value retailer for quick lookups, a relational database for pre-computed aggregates, and an open desk format (Iceberg) with a distributed question engine (Trino) for versatile querying.
But the core rigidity remained unsolved. Enterprise clients demanded interactive, arbitrary slicing of billions of data throughout high-cardinality dimensions, not canned reviews. The stream processor couldn’t deal with advert hoc aggregations at question time. The important thing-value retailer was blind to analytical queries. The distributed question engine supplied flexibility however was too gradual for interactive use.
The consequence was a system that was costly and operationally complicated. It included 9 relational database clusters, sprawling ETL pipelines, and 24/7 pre-aggregation jobs working no matter demand. It nonetheless couldn’t ship the one factor clients wanted most: quick, versatile, interactive analytics at scale.
Structure and implementation: MSK and Amazon Managed Service for Apache Flink because the streaming spine
The answer Buildkite arrived at facilities on Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink because the real-time information streaming and processing layers, decoupling high-throughput ingestion from downstream analytics.
The information pipeline
The next diagram reveals the end-to-end information movement from CI/CD brokers by way of Amazon MSK and Amazon Managed Service for Apache Flink to the analytics layer.
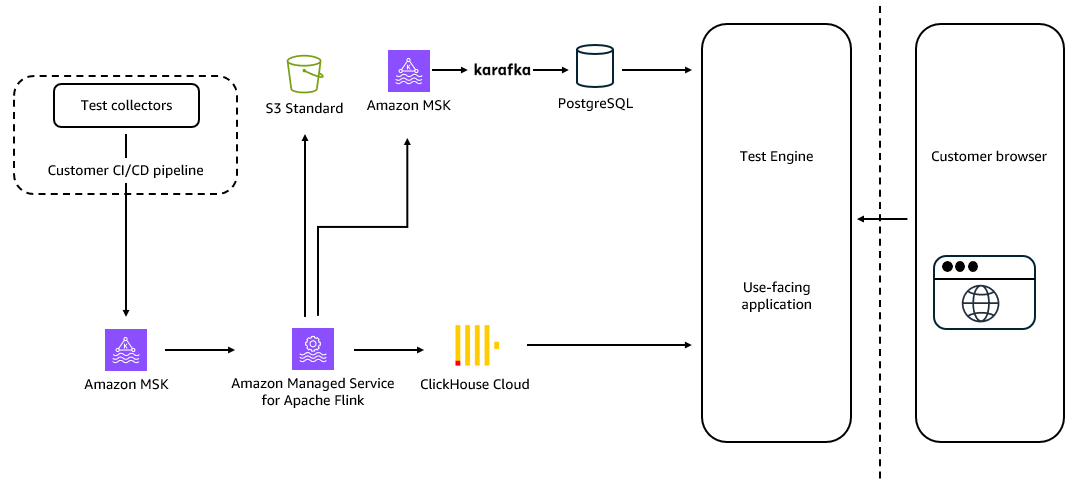
Amazon MSK sits on the crucial junction between information producers (the distributed CI/CD brokers and take a look at collectors working throughout buyer infrastructure) and the downstream processing and analytics layers. Amazon Managed Service for Apache Flink then transforms these uncooked occasion streams into enriched, queryable information earlier than it reaches the analytics retailer.
Excessive-throughput ingestion from CI/CD pipelines
Amazon MSK’s position begins at ingestion. Take a look at collectors embedded in CI/CD pipelines publish take a look at execution occasions on to Kafka matters. The present Amazon MSK cluster handles between 5 MB/sec and 100 MB/sec of inbound information underneath regular working situations. The structure is designed to soak up the numerous variance inherent in CI/CD workloads, the place pipeline exercise is bursty and correlated with engineering crew working hours throughout international time zones.
When the Buildkite challenge was initiated, MSK Specific Brokers weren’t but obtainable, main the crew to undertake MSK Tiered Storage as the first mechanism for scaling and restoration. With MSK Specific Brokers now usually obtainable, the crew is evaluating a migration of its most crucial log ingestion workload, which sustains as much as 1 GB/s at peak ingestion. MSK Specific Brokers carry computerized storage scaling with zero storage administration overhead, as much as 20x sooner scaling and 90% sooner dealer restoration, 3x increased per-broker throughput, 5x extra partitions per dealer, and built-in Clever Rebalancing.
Actual-time stream processing with Amazon Managed Service for Apache Flink
Sitting between Amazon MSK and the analytics layer, Amazon Managed Service for Apache Flink acts because the stateful stream processing engine that transforms uncooked occasion streams earlier than they attain downstream programs. Buildkite chosen Flink for its exactly-once processing, mature stateful computation mannequin, and deep Kafka integration. Dealing with sustained peaks of over 25,000 occasions per second, Amazon Managed Service for Apache Flink eliminates the operational overhead of cluster provisioning, model upgrades, checkpointing, and job restoration. This frees engineering groups to concentrate on software logic.
Amazon Managed Service for Apache Flink powers key stateful processing duties, together with flaky take a look at detection by way of time-windowed sample matching, enriching execution occasions with pipeline and buyer metadata, and routing processed information to downstream programs akin to ClickHouse for analytics, PostgreSQL for operational workloads, and Amazon Easy Storage Service (Amazon S3) for long-term archival.
Reliability and fault tolerance
Amazon MSK’s three-replica configuration ensures that no single dealer failure may cause information loss or ingestion interruption. Mixed with versatile information retention, the structure offers a significant replay window. If a downstream client (Amazon Managed Service for Apache Flink, ClickHouse, or one other service) experiences an outage, it may resume processing from its final dedicated offset with out information loss.
In the course of the migration to the present structure, Buildkite employed a dual-write technique: concurrently writing to each the present PostgreSQL pipeline and the brand new Amazon MSK/ClickHouse path. This method allowed the crew to validate information consistency and step by step shift site visitors with out risking customer-facing disruption. This sample speaks to the operational maturity Amazon MSK offers.
Operational effectivity features
The shift to a streaming-first structure, mixed with the downstream simplification of the analytics engine, produced important operational enhancements:
- Flink workloads diminished by 60%+: Eliminating pre-aggregation jobs that ran constantly no matter demand.
- Key/worth retailer fully retired: Amazon MSK’s buffering functionality, mixed with ClickHouse’s question efficiency, eradicated the necessity for a separate fast-lookup retailer.
- PostgreSQL capability reduce in half: 9 separate database clusters consolidated and right-sized.
- Hundreds of traces of software code deleted: Less complicated structure means much less ETL code, fewer failure modes, and sooner onboarding for brand spanking new engineers.
Platform efficiency at a look
| Metric | Worth |
| Month-to-month take a look at executions (for take a look at engine platform) | 50 billion (4x development from 3B) |
| Sustained peak ingestion | 500K occasions/second |
| Whole data in analytics retailer | 200 billion |
| Log ingestion requests | 70,000+ per second |
| Peak webhook throughput | 1.7 GB/second |
| MSK inbound throughput vary | 5 MB/sec – 100 MB/sec |
Enterprise and developer impression
The technical structure finally exists to serve one function: serving to builders ship higher software program sooner. The streaming-first structure constructed on Amazon MSK and Amazon Managed Service for Apache Flink delivers on that promise throughout 4 dimensions.
On-demand analytics changed pre-computed reviews. Prospects can now interactively slice and cube 70 billion data throughout arbitrary metadata dimensions. They get solutions to queries like “Present me P50 take a look at durations by occasion sort and structure for the final 30 days” in seconds, not hours. Actual-time log streaming by way of the “reside tail” function means builders not anticipate a construct to finish earlier than diagnosing failures. At 25,000 occasions per second, this expertise scales throughout hundreds of concurrent enterprise pipelines with out degradation.
Smarter take a look at intelligence comes from Amazon Managed Service for Apache Flink’s stateful flaky take a look at detection: when a take a look at begins exhibiting intermittent failure patterns, Amazon Managed Service for Apache Flink identifies it because it occurs, not after the actual fact. That is what separates a proactive analytics platform from a reactive one. It requires publishing information to Kafka, processing with Flink, and letting ClickHouse deal with the complicated learn requests.
Conclusion: Streaming as a strategic basis
Buildkite’s journey from a Rails/Postgres monolith to a streaming-first analytics platform displays a sample more and more widespread amongst enterprise SaaS corporations: a dependable, high-throughput streaming and processing layer isn’t an optimization. It’s a prerequisite for working at scale.
Amazon MSK and Amazon Managed Service for Apache Flink type the spine that helps Buildkite ingest 50 billion take a look at executions per 30 days, serve real-time interactive analytics to enterprise clients, and achieve this at decrease price than the extra complicated structure it changed. Amazon MSK handles sturdy, elastic occasion buffering. Amazon Managed Service for Apache Flink transforms uncooked streams into enriched, queryable information. Collectively they take up the operational complexity that may in any other case eat engineering capability.
For platform engineers evaluating streaming infrastructure for multi-tenant SaaS workloads, the sign is obvious: spend money on the streaming spine early, and let managed providers deal with the operational complexity.
To be taught extra about Amazon MSK and Amazon Managed Service for Apache Flink, go to aws.amazon.com/msk and aws.amazon.com/managed-service-apache-flink.
Concerning the authors