

{kind=link}
On this article, you’ll find out how context engineering and reminiscence engineering resolve completely different issues in agentic AI methods, and the way the 2 disciplines meet on the level the place retrieved reminiscence enters the context window.
Matters we’ll cowl embody:
- What context engineering entails, together with selective inclusion, structural placement, and compression, and why it issues for reasoning high quality inside a single inference name.
- What reminiscence engineering entails, together with write coverage design, storage layer choice, retrieval technique, and upkeep, and the way these form long-term reliability.
- How reminiscence and context engineering meet on the retrieval boundary, and the 2 most typical failure modes that happen when this boundary shouldn’t be managed effectively.
With that framing in place, right here’s how every self-discipline works.
Introduction
As AI brokers transfer into longer workflows and multi-session use circumstances, a well-recognized sample emerges. Constraints get dropped mid-task, retrieved info resurfaces when it shouldn’t, and context from an earlier step bleeds into the present one. The failures are laborious to pinpoint as a result of no single part is clearly at fault.
More often than not, the issue lies in two areas that get constructed collectively, conflated, or skipped: context engineering and reminiscence engineering. They’re associated however distinct, fail in numerous methods, and require completely different methods to get proper.
This text covers the core choices behind every self-discipline and the place they work together:
- What context engineering entails and the particular choices that decide whether or not an agent causes effectively inside a single name
- What reminiscence engineering entails and the way write coverage, storage, retrieval, and upkeep every have an effect on long-term reliability
- How the 2 disciplines share a boundary at retrieval time and what it takes to handle that boundary effectively
Understanding each, individually and collectively, is what determines whether or not an agent holds up throughout actual workloads.
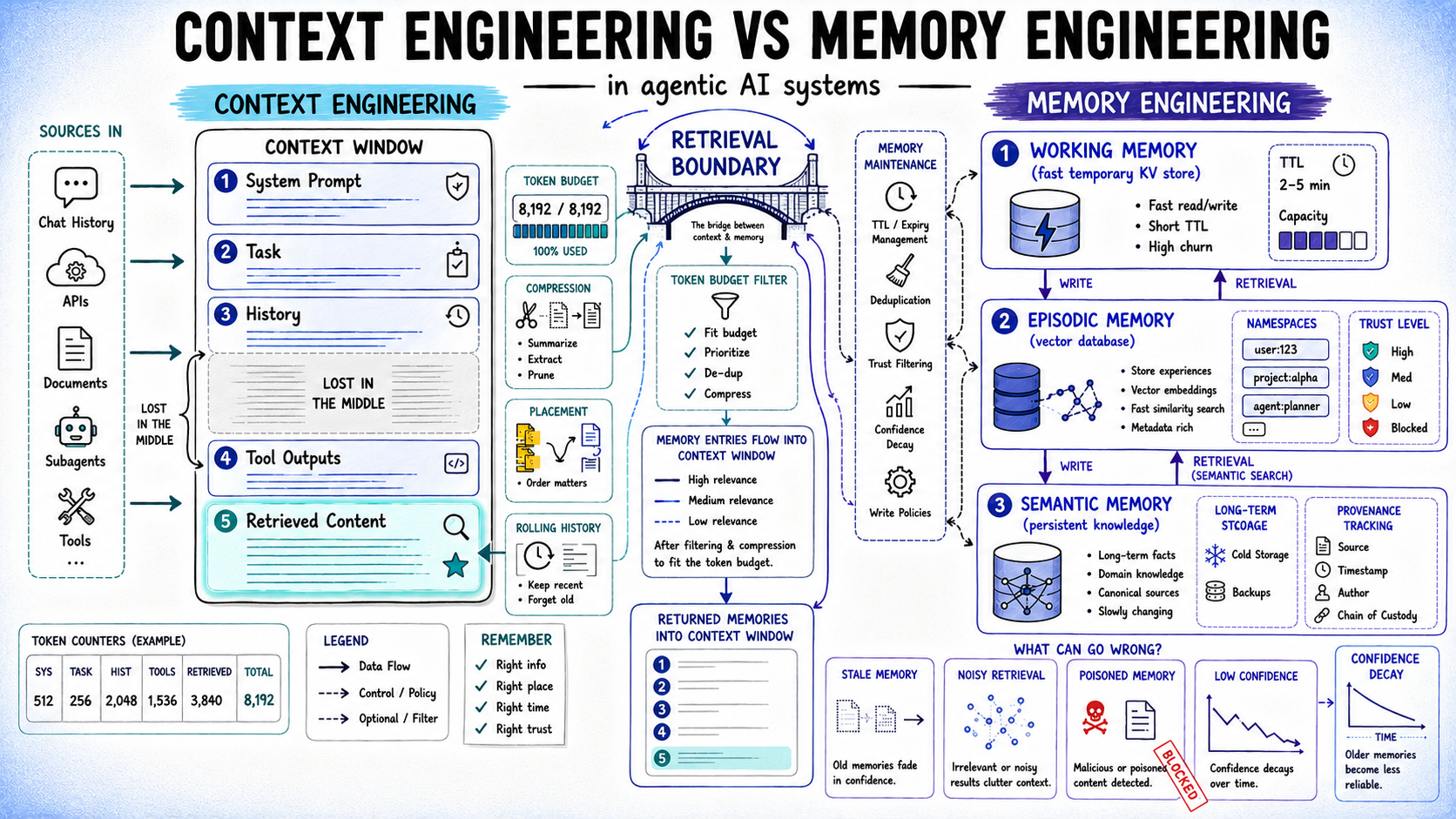
An Overview of Context and Reminiscence Engineering
Context engineering covers the design of a single inference name: what to incorporate, what to compress, the place to position issues, and what to discard. All the things in scope is ephemeral; when the decision ends, the window clears.
Reminiscence engineering focuses on what survives past a single interplay with a mannequin. It encompasses the methods and insurance policies answerable for writing, storing, retrieving, updating, and governing info in order that future interactions could make use of it. When an agent remembers info from a earlier session, coordinates with one other agent, or applies a person choice discovered days or perhaps weeks earlier, it’s counting on reminiscence engineering slightly than context engineering.
Whereas context engineering determines what info is on the market to the mannequin throughout a particular request, reminiscence engineering determines what info persists throughout requests and the way that info is maintained, retrieved, and trusted over time. Right here’s an summary:
| Side | Context Engineering | Reminiscence Engineering |
|---|---|---|
| Scope | One inference name | Throughout calls, periods, brokers |
| The place knowledge lives | Contained in the mannequin’s energetic window | Exterior shops: vector DB, Okay/V, relational |
| Major downside | What to incorporate and tips on how to organize it | What to persist, retrieve, and belief |
| Fails when | Window fills, placement is incorrect, noise overwhelms sign | Retrieval misses, staleness, poisoning, no write coverage |
| Engineering floor | Immediate construction, compression, token budgeting | Storage schema, retrieval technique, write and replace insurance policies |
| Lifespan of knowledge | Period of 1 LLM name | Will depend on the reminiscence kind |
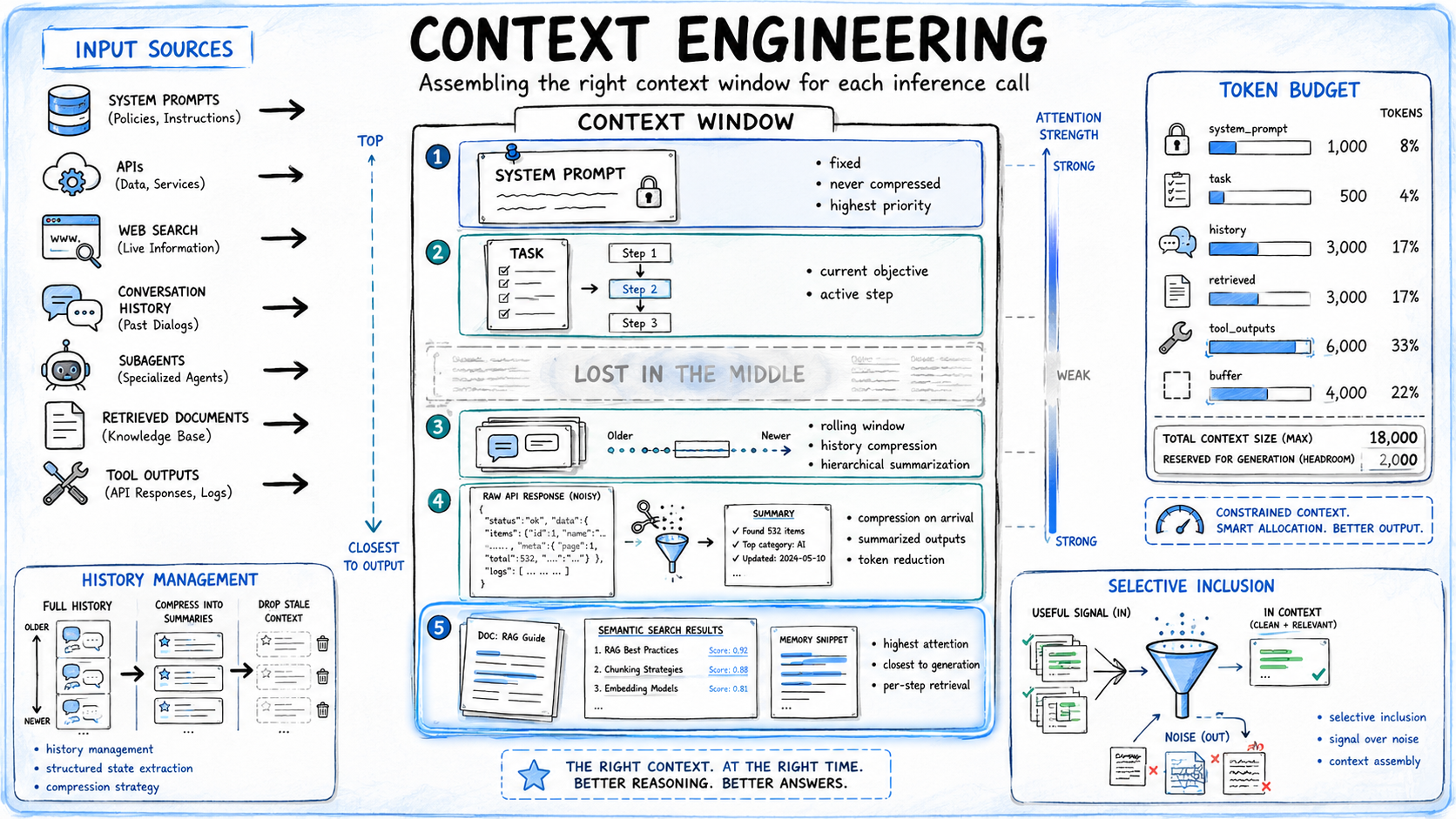
Context Engineering: Assembling the Optimum Context Window
For an agent working a multi-step workflow, each inference name assembles a context window from a number of sources: system immediate, activity description, dialog historical past, instrument outputs, retrieved paperwork, subagent summaries. Context engineering is the set of selections that decide what every part contributes, in what kind, and in what place.
Selective Inclusion
Not the whole lot out there ought to enter the context. A database question returning a whole bunch of rows, an online search returning 5 full articles, a code executor logging verbose output — all of those bloat the window and cut back reasoning high quality earlier than the token restrict is reached. The choice about what will get included verbatim, what will get compressed to key details, and what will get dropped is a design selection, not a default.
Structural Placement
The place info sits within the window impacts how reliably the mannequin makes use of it. Fashions attend extra strongly to content material at first and finish of lengthy contexts, with materials within the center receiving considerably much less weight. This is called the “misplaced within the center” impact.
Laborious constraints and task-critical directions belong on the prime of the window. Retrieved info that’s most related to the present activity must be positioned close to the top of the context window.
The present person question or activity ought to sometimes observe the retrieved info, positioning each the related context and the instant goal as shut as potential to the technology level. This association will increase the probability that the mannequin will successfully use the retrieved info when producing its response.
Context Engineering Overview
Compression on Arrival
Device outputs must be compressed after a name returns, not after the window fills. A uncooked API response carrying 3,000 tokens, of which the agent wants solely 150, must be summarized earlier than it enters context for the following step. Ready till the window is full after which scrambling to truncate is reactive administration of an issue that compression on the supply prevents.
Dialog Historical past Administration
Dialog historical past grows sooner than some other context part. For long-running brokers, carrying the total historical past into each name makes each subsequent inference dearer and fewer dependable. A compression technique — rolling window, hierarchical summarization, or structured state extraction — must be utilized at outlined intervals, not when the window overflows.
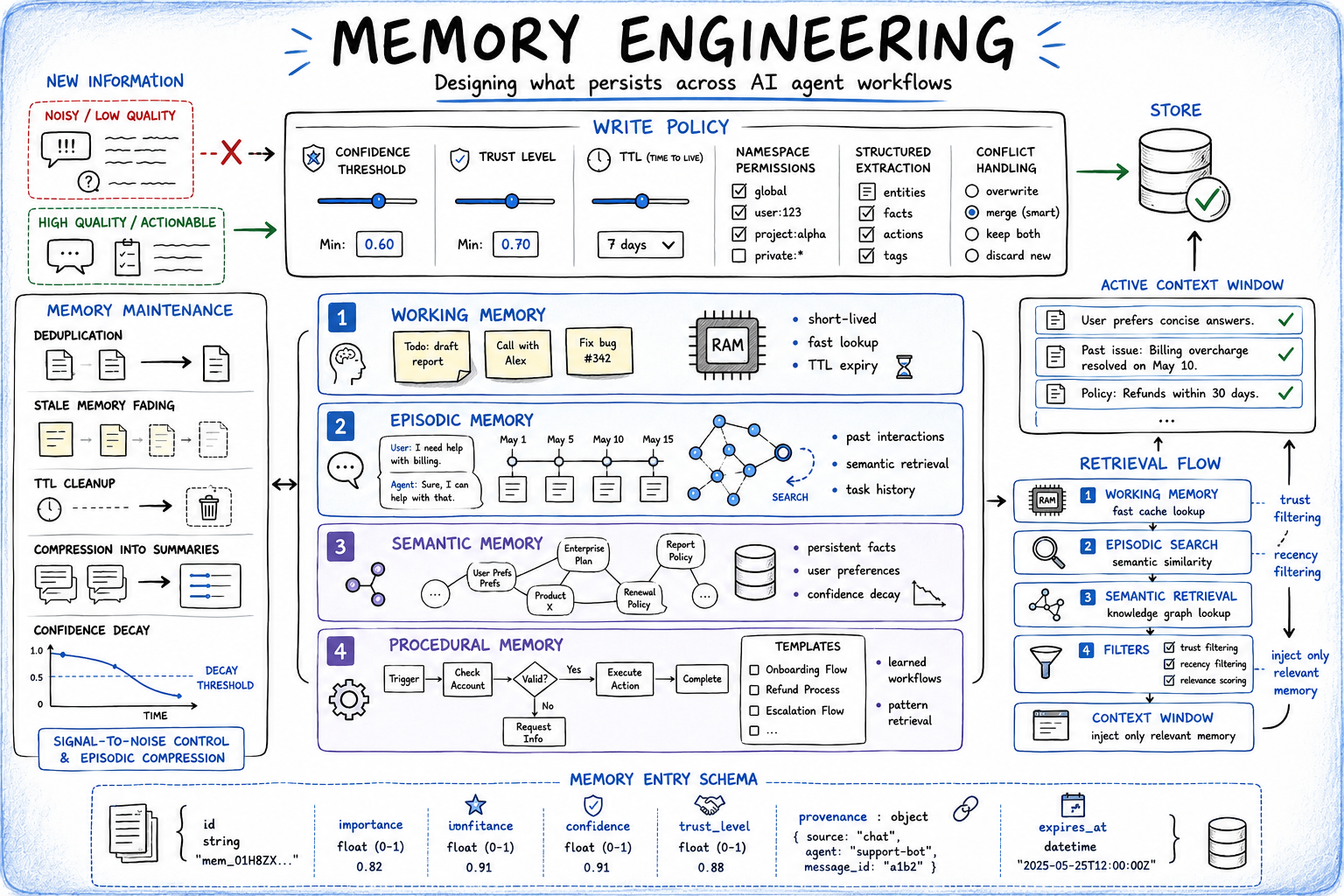
Reminiscence Engineering: Designing Persistent AI Reminiscence Techniques
As soon as an inference name completes, reminiscence engineering determines what deserves to persist and below what situations it will get used once more. This covers 4 distinct issues: what to put in writing, the place to retailer it, tips on how to retrieve it, and tips on how to hold it correct over time.
Write Coverage Design
Write coverage design is likely one of the most ignored points of reminiscence engineering, but it has a disproportionate impression on reminiscence high quality over time. Whereas retrieval methods usually obtain probably the most consideration, retrieval high quality is in the end constrained by what enters the reminiscence retailer within the first place.
A well-defined write coverage specifies:
- What occasions set off a write to reminiscence
- Which info is eligible for storage
- The format during which info is saved, akin to uncooked textual content, structured data, extracted details, or summaries
- The boldness or validation necessities for accepting new entries
- Which brokers, instruments, or system parts are permitted to put in writing to particular reminiscence namespaces
- How updates, corrections, and conflicting info are dealt with
- Retention guidelines, expiration insurance policies, and time-to-live (TTL) necessities for various reminiscence varieties
With out express write insurance policies, methods usually default to storing an excessive amount of info, assigning equal belief to all entries, and retaining knowledge indefinitely. Over time, low-value and outdated recollections accumulate, signal-to-noise ratios decline, and retrieval high quality degrades. The result’s a reminiscence system that grows repeatedly whereas turning into progressively much less helpful.
Storage Layer Choice
Completely different reminiscence varieties serve completely different functions and require completely different storage backends. The selection of backend additionally constrains which retrieval methods can be found.
| Reminiscence Sort | What It Shops | Storage Backend | Retrieval Technique |
|---|---|---|---|
| Working | Energetic activity state, intermediate outcomes | In-memory or short-lived Okay/V (Redis) | Direct key lookup |
| Episodic | Previous interactions, activity runs, choices | Vector retailer (Pinecone, Weaviate, Chroma) | Semantic similarity search |
| Semantic | Persistent details, person preferences, area data | Vector retailer + Okay/V hybrid | Semantic search or actual key |
| Procedural | Discovered workflows, profitable motion patterns | Structured retailer or immediate injection | Sample match, direct retrieval |
OpenAI’s context personalization cookbook makes a helpful distinction between retrieval-based reminiscence and state-based reminiscence to be used circumstances requiring continuity. Retrieval-based reminiscence treats previous interactions as loosely associated paperwork and is brittle to phrasing variation and conflicting updates. Structured state extraction — writing typed, validated details slightly than embedding uncooked dialog chunks — produces extra constant outcomes for details that must be utilized reliably throughout periods.
Reminiscence Engineering Overview
Retrieval Technique
Studying from reminiscence shouldn’t be a single operation. A well-designed retrieval layer checks working reminiscence first (quick, low-cost, actual key lookup), falls again to semantic search in episodic or semantic reminiscence when nothing related surfaces, applies metadata filters for recency and belief stage earlier than returning outcomes, and injects solely what the present step wants.
Reminiscence Upkeep
A retailer with no upkeep coverage degrades over time. The entries accumulate, stale details compete with present ones, and retrieval high quality falls as signal-to-noise ratio drops. The next upkeep routines matter in apply: confidence decay on risky details, deduplication of semantically comparable entries, TTL-based expiry on working reminiscence and time-sensitive knowledge, and periodic compression of previous episodic data into session-level summaries.
A MemoryEntry schema that encodes these issues straight makes write and upkeep logic simpler to motive about:
|
class MemoryEntry(BaseModel): content material: str memory_type: str # working | episodic | semantic | procedural significance: float # 0.0–1.0, gates long-term storage confidence: float # decays over time for risky details trust_level: float # 1.0 inside system, 0.5 person enter, 0.0 exterior created_at: datetime expires_at: datetime | None provenance: dict # agent_id, tool_name, session_id, input_hash
def should_write_to_long_term(entry: MemoryEntry) -> bool: return ( entry.significance >= 0.6 and entry.confidence >= 0.7 and entry.trust_level >= 0.5 ) |
AI Agent Reminiscence Design Information – Working, Lengthy-Time period, and Procedural Reminiscence with Forgetting and Staleness Administration and 7 Steps to Mastering Reminiscence in Agentic AI Techniques are helpful overviews of agent reminiscence design.
The Retrieval Boundary: Connecting Reminiscence and Context Engineering
Reminiscence engineering and context engineering are sometimes mentioned as separate disciplines, however in apply they’re deeply interconnected. Each exist to unravel the identical basic downside: guaranteeing {that a} mannequin has entry to the proper info on the proper time.
At a excessive stage:
- Reminiscence engineering focuses on persistence: what info must be saved, up to date, retained, or forgotten over time.
- Context engineering focuses on utilization: what info ought to enter the energetic context window for a particular activity and the way it must be organized.
- Retrieval is the boundary the place these two disciplines meet.
Reminiscence methods produce candidate info. Context meeting then decides:
- Whether or not that info ought to enter the immediate
- How a lot of it must be included
- The place it must be positioned inside the context window
Managing this boundary effectively is what transforms a group of reminiscence parts right into a coherent agent system.
Failure Mode #1: Retrieval And not using a Context Price range
One of the frequent failures happens when retrieval is handled independently from context meeting.
A reminiscence search returns a set of related entries, and the context assembler injects all of them into the immediate. As extra recollections are added, the context window progressively fills with retrieved content material, leaving much less room for directions, instrument outputs, reasoning traces, and task-specific info.
The ensuing signs are sometimes deceptive:
- Retrieval high quality seems excessive
- Related recollections are efficiently discovered
- System efficiency nonetheless degrades
In lots of circumstances, the reminiscence system has achieved its job accurately. The failure happens as a result of context meeting lacks a budgeting mechanism.
A greater strategy is retrieval-aware context meeting. As an alternative of retrieving first and budgeting later, the context layer allocates a token funds earlier than retrieval begins. The retrieval layer then returns solely the highest-value recollections that match inside that funds.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
async def retrieve_for_step( self, step: AgentStep, max_tokens: int ) -> str: candidates = await self.reminiscence.search( question=step.retrieval_query, max_results=10, filters={ “trust_level”: {“gte”: 0.5}, “expires_at”: {“gt”: datetime.now()} } )
chosen = [] used = 0
for entry in sorted( candidates, key=lambda e: e.relevance_score, reverse=True ): value = self.token_count(entry.content material)
if used + value > max_tokens: break
chosen.append(entry.content material) used += value
return “nn”.be a part of(chosen) |
The important thing thought is easy: retrieval should function inside context constraints, not assume limitless area downstream.
Failure Mode #2: Poor Placement of Retrieved Info
Retrieval high quality alone shouldn’t be adequate. Even extremely related recollections can fail if they’re positioned incorrectly contained in the context window.
A standard subject is treating retrieval purely as a search downside whereas ignoring placement. Retrieved recollections are appended wherever they arrive, with out contemplating their function within the present reasoning step.
This turns into extra impactful in lengthy contexts. Consideration shouldn’t be uniformly distributed throughout the immediate. Info positioned deep inside a protracted context can obtain considerably much less affect than info positioned close to the start or finish. This results in a delicate failure mode:
- The right info is retrieved
- The data is inserted into context
- The mannequin behaves as whether it is lacking
The retrieval succeeded however the placement failed. Context meeting ought to subsequently optimize each:
- Choice: what enters the context window
- Placement: the place it seems inside the context window
Retrieved info that should affect the present step must be positioned close to the energetic reasoning area slightly than appended arbitrarily.
Retrieval as a Step in Context Building
Retrieval is step one in turning saved reminiscence into usable context. The aim shouldn’t be solely to retrieve related info, however to make sure it’s the proper info for the present step, in the correct amount to suit inside the context funds, and positioned in the proper location the place the mannequin can successfully use it.
When reminiscence engineering and context engineering are handled as a single retrieval-to-context pipeline, slightly than remoted parts, agent methods turn out to be extra dependable, environment friendly, and scalable.
Context Engineering – LLM Reminiscence and Retrieval for AI Brokers by Weaviate is a good reference.
Abstract
Context and reminiscence engineering are two layers of a single system that controls what the mannequin is aware of, when it is aware of it, and the way that data is used.
Context engineering operates at inference time, shaping the energetic info window. Reminiscence engineering operates throughout time, shaping what info persists and the way it may be retrieved later.
| Dimension | Context Engineering | Reminiscence Engineering |
|---|---|---|
| Core query | What ought to the mannequin see proper now, and the way? | What ought to the system retain, and for the way lengthy? |
| Major artifact | Assembled context window per inference name | Continued reminiscence entries throughout calls and periods |
| Token administration | Price range allocation per window part | Storage value per entry kind; retrieval value per question |
| Compression | Device outputs summarized earlier than injection; historical past rolled or extracted | Outdated episodic data compressed; stale details decayed or pruned |
| Freshness | Rolling historical past window; stale turns dropped | TTL on risky details; confidence decay over time |
| Belief | Supply hierarchy governs meeting order | Provenance tracked per entry; low-trust content material sanitized earlier than write |
| Multi-agent | Every agent assembles its personal window independently | Scoped namespaces per agent; shared namespace for cross-agent details |
| Failure mode | Overflow, consideration degradation, noisy meeting | Poisoning, staleness, retrieval miss, unbounded development |
| Upkeep | Proactive compression at outlined intervals | TTL expiry, deduplication, confidence decay, episodic archiving |
| The place they meet | Retrieved reminiscence enters context: funds and placement govern how | Context meeting requests retrieval inside a token funds constraint |
To sum up, an agentic system solely works when each layers are aligned: reminiscence determines what is on the market, and context determines what turns into actionable.