

{kind=link}
Price Limiting vs. Quota Reservations: when to make use of every
You could have a single gpt-oss-20b deployment. Six groups wish to use it. Advertising is working batch summarization jobs at 3am. The fraud crew wants sub-second responses 24/7. An intern’s Jupyter pocket book is by chance hammering the endpoint in a good loop. And your GPU invoice is already eye-watering.
Sound acquainted? DataRobot offers you two instruments to unravel this: Price Limiting and Quota Reservations. This publish explains when to achieve for every, backed by an actual load check instance on a staging deployment.
Price Limits and Quota Reservations, in plain English
Price Limits – Accessible in DataRobot v11.4
Price limits units per-consumer caps throughout a number of dimensions: requests per minute, token depend per hour, concurrent requests, and enter sequence size. A default coverage applies to all customers, with per-entity exceptions accessible for particular overrides.

What it protects in opposition to: Any single client overconsuming — whether or not by excessive request quantity, giant inputs, or extreme concurrency.
Quota Reservations – accessible in DataRobot v11.9
Quota reservations outline the deployment’s complete potential throughput (worth per minute) and a utilization threshold that triggers enforcement. Inside that price range, particular entities might be allotted a reserved share — guaranteeing them a minimal slice of capability that different customers can’t take away.
What it protects in opposition to: Precedence hunger. With out reservations, a loud neighbor can eat the complete capability price range, leaving your crucial workloads with nothing.
How Price Limits and Quota Reservations work collectively (and aside)
Used alone, every instrument solves a particular downside:
- Price limiting alone caps complete throughput. Below saturation, all customers compete equally — first come, first served.
- Quota reservations alone assure minimal throughput for particular customers, no matter what others are doing.
Collectively, they offer you each management surfaces: a ceiling that protects the mannequin and assured flooring for the customers that matter most.
Load testing a multi-tenant deployment
To judge these options below stress, we load-tested a gpt-oss-20b deployment in our staging setting. The setup simulates an actual multi-tenant situation: 4 customers sharing one mannequin, every with completely different precedence ranges.
Instance configuration
| Setting | Worth |
|---|---|
| Mannequin | gpt-oss-20b (NVIDIA NIM) |
| Capability | 1000 RPM |
| Utilization Threshold – | 80% (enforcement begins at 800 RPM) |
| Shopper | Sort | Reserved Capacity | Efficient Assure |
|---|---|---|---|
| Manufacturing Agent A | Deployment | 30% | 300 RPM |
| Manufacturing Agent B | Deployment | 20% | 200 RPM |
| Manufacturing Agent C | Deployment | 30% | 300 RPM |
| Dev Person (unreserved) | Person | – | None — shares the 20% unreserved pool |
This left a 20% unreserved pool (200 RPM) for the dev person and any overflow.
Instance load profile
We ran six escalating eventualities over 17 minutes to look at behaviour at completely different saturation ranges:
| State of affairs | What Occurs | Mixed Load |
|---|---|---|
| Regular site visitors | All 4 customers at reasonable, throttled charges |
~600 RPM (under utilization threshold) |
| Slight overload | All 4 customers ramp as much as simply over capability |
~1,200 RPM (1.2× capability) |
| Heavy overload | All 4 customers hearth as quick as potential |
~7,200 RPM (7× capability) |
| Excessive overload | Most concurrent staff per client |
~12,000 RPM (12× capability) |
| Late joiner | Three brokers flood first, dev person joins 60s later |
~9,000 RPM |
| Reserved-only | Three brokers compete, dev person silent |
~7,200 RPM |
When to make use of Price Limiting alone
Price limiting by itself is the precise alternative when:
- All customers are equally essential. If no crew’s site visitors is extra crucial than one other’s, there’s no want for reservations. Equal competitors below saturation is honest sufficient.
- You simply want to guard the GPU. Your major concern is {that a} spike in site visitors doesn’t degrade mannequin latency or trigger OOM errors. You need a security valve, not a site visitors coverage.
- You could have a single client. If there’s just one utility hitting the deployment, reservations are meaningless — there’s nobody to order in opposition to.
What the instance confirmed
In the course of the regular site visitors situation (~600 RPM mixed, properly under the 800 RPM utilization threshold), the speed limiter was invisible and all 4 customers achieved 100% success charges with zero rejected requests.
| State of affairs | Mixed RPM | Success Price | 429s |
|---|---|---|---|
| Regular site visitors | ~600 | 100% | 0 |
Dimension your reservations based mostly on absolutely the minimal throughput every client requires throughout peak competition. That is by design, so that you’re not penalizing regular site visitors.
And it protects the mannequin even below excessive abuse. In the course of the excessive overload situation (20,000+ RPM in opposition to 1,000 RPM capability, which is a a 20× overload), the speed limiter rejected 95% of requests. However the mannequin itself stayed completely wholesome:
| NIM Metric | Below 20× Overload |
|---|---|
| GPU Utilization | 91–95% (steady) |
| E2E Latency | 1.25s → 2.09s (transient spike, then steady) |
| Time to First Token | 35ms (unchanged) |
| Inter-Token Latency | 18ms (unchanged) |
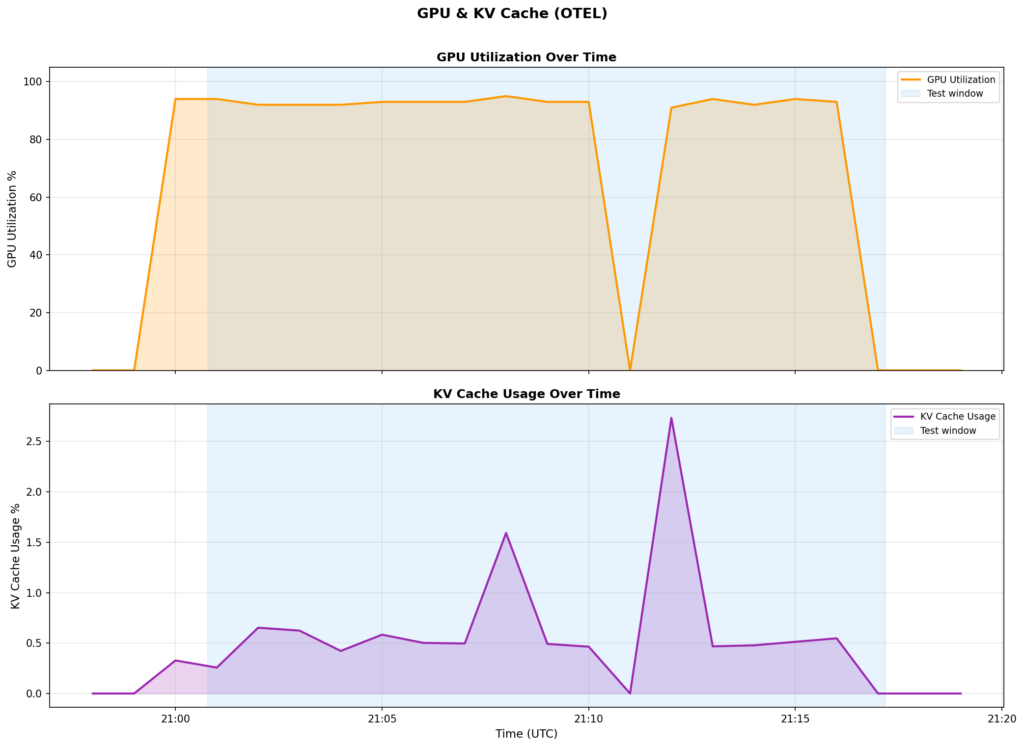
| KV Cache | <3% (not harassed) |
The speed limiter acted as a firewall between chaotic shopper demand and steady mannequin inference. With out it, these 20,000 requests per minute would have queued up contained in the NIM, latency would have ballooned, and the mannequin would have successfully turn into unusable for everybody.
Takeaway: In case your solely objective is “don’t let site visitors spikes kill the mannequin,” fee limiting alone is enough and zero-config past setting the capability quantity.
When so as to add Quota Reservations
Quota reservations turn into important when:
- Some customers are extra essential than others. Your fraud detection system can’t afford to be starved out by a batch analytics job. Your manufacturing agent wants assured throughput {that a} developer’s check harness can’t steal.
- You could have a multi-tenant deployment. A number of groups, functions, or downstream deployments share the identical mannequin. With out reservations, the loudest client wins.
- You need predictable SLAs. In the event you’ve promised a crew “your utility will get a minimum of 300 RPM,” reservations are the way you implement that promise on the infrastructure degree.
- You could have a mixture of interactive and batch workloads. Batch jobs are bursty and can fortunately eat all accessible capability. Reservations guarantee interactive workloads nonetheless get their share throughout batch spikes.
Tips on how to measurement reservations
Dimension your reservations based mostly on absolutely the minimal throughput every client requires throughout peak competition.
Guidelines of thumb:
- Don’t reserve 100%. Depart an unreserved pool (10–20%) for ad-hoc site visitors, new customers, and overflow. In the event you reserve the whole lot, any new utility will get zero throughput till you reconfigure.
- Dimension reservations to minimal wants, not peak wants. Reservations assure a flooring, not a ceiling. An entity with 30% reserved can nonetheless use greater than 30% when capability is offered.
- Match reservation measurement to enterprise criticality, not crew measurement. Your fraud detection system might need fewer requests than your analytics pipeline, nevertheless it wants assured entry extra.
In our instance, three manufacturing brokers acquired 30%/20%/30% reservations, leaving a 20% unreserved pool for the dev person. This meant the dev person might nonetheless use the deployment — they simply wouldn’t get assured entry throughout competition.
Do reservations work below actual load?
At slight overload (1.2× capability): The system degrades gracefully
In the course of the slight overload situation (~1,200 RPM in opposition to 1,000 RPM capability), all 4 customers achieved 100% success — the token bucket’s burst capability absorbed the slight overage. That is the “swish degradation” zone the place reservations aren’t but wanted, however the system is proving it will possibly deal with bursts.
At heavy-to-extreme overload (7–12× capability): reservations preserve a assured flooring
When all 4 customers fired as quick as potential (7,000–12,000 RPM in opposition to a 1,000 RPM capability), the system was overwhelmed. Right here’s what every client skilled throughout the complete check:
| Shopper | Reserved | Success Price | Profitable Requests |
|---|---|---|---|
| Manufacturing Agent A | 30% | 29.0% | 4,172 |
| Manufacturing Agent B | 20% | 30.2% | 4,332 |
| Manufacturing Agent C | 30% | 28.9% | 4,176 |
| Dev Person (unreserved) | – | 28.9% | 2,828 |
Why the success charges look related: At 12× overload, even a 300 RPM reservation is simply ~2.5% of what every client is making an attempt to ship (~3,000 RPM per client vs. a 300 RPM assure). The reservation works by making certain every client receives its assured 200–300 RPM. Nevertheless, as a result of 97% of complete site visitors is rejected throughout excessive overloads, the relative share variations compress.
The extra revealing metric is absolute throughput. Reserved customers accomplished 4,172–4,332 profitable requests. The unreserved dev person accomplished 2,828 — about 34% fewer. Even accounting for the dev person’s shorter energetic time, reserved customers persistently bought extra requests by throughout shared eventualities.
At saturation with a late joiner: reservations shield incumbents
Within the late joiner situation, the three manufacturing brokers had been already flooding the system when the dev person joined 60 seconds later. With all reserved capability spoken for, the dev person was confined to the 20% unreserved pool (~200 RPM). The manufacturing brokers continued drawing from their assured buckets, unaffected by the brand new arrival.
That is the situation that issues most in manufacturing. A batch job kicks off, or a brand new utility goes dwell, and out of the blue there’s extra demand than provide. With out reservations, the brand new load pushes everybody’s throughput down equally. With reservations, your crucial customers are shielded.
Reserved customers compete pretty amongst themselves
Within the reserved-only situation, the dev person went silent and solely the three manufacturing brokers competed. Their success charges had been almost similar (28.9%–30.2%) — the system divided throughput proportionally throughout their reservations.
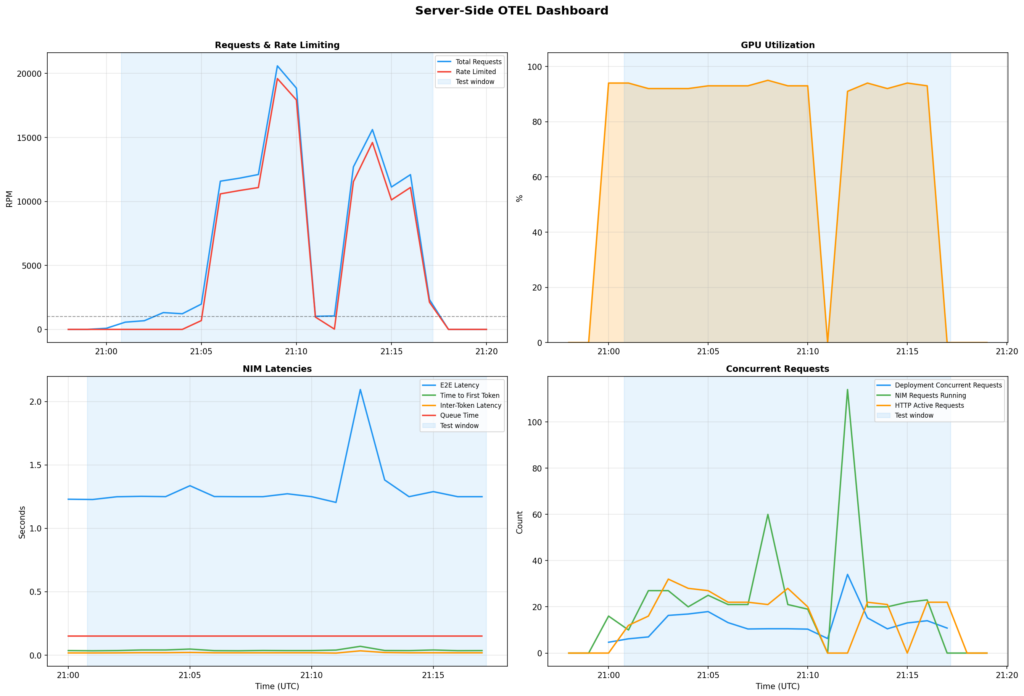
What the server sees: OTEL metrics inform the story
Shopper-side metrics (success charges, 429 counts) inform you what your customers skilled. Server-side OTEL metrics inform you what the platform skilled. Right here’s what our instance deployment seemed like from the within.
The speed limiter protects mannequin well being
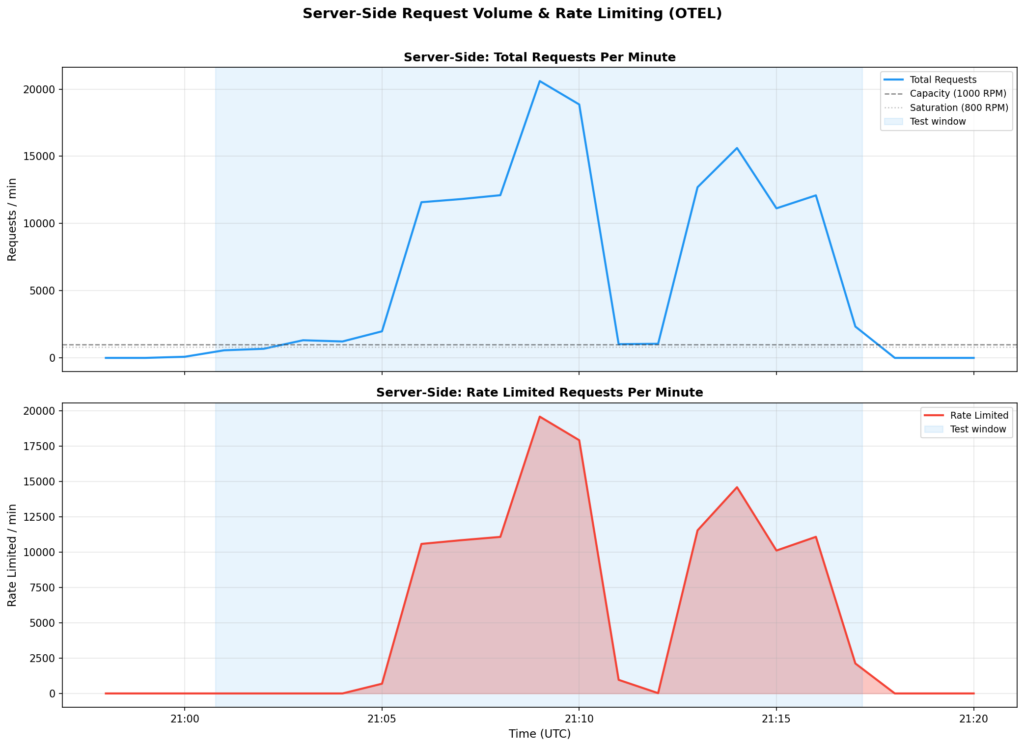
Throughout peak load (20,596 requests/minute hitting the endpoint), the NIM was serving solely the ~1,000 RPM that the speed limiter let by:
| What the endpoint noticed | What the NIM noticed |
|---|---|
| 20,596 requests/min | ~1,000 requests/min (served) |
| 19,603 rate-limited/min | 18–22 concurrent requests |
| — | 1.25s E2E latency (steady) |
| — | 91–95% GPU utilization (wholesome) |
With out fee limiting, these 20,000 RPM would have queued contained in the NIM. The GPU wouldn’t have gotten extra productive — it’s already at 91–95% — however latency would have spiraled as requests stacked up. As a substitute, the speed limiter rejected extra requests instantly (at 429-response speeds, not inference speeds), holding the mannequin responsive for the site visitors it did settle for.
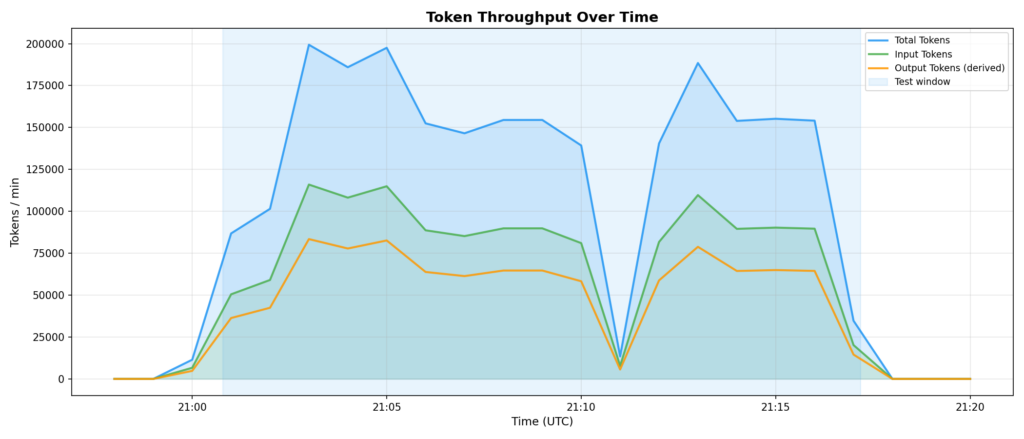
Token throughput follows profitable requests
Peak token throughput was ~199,350 tokens/min (complete), with ~115,939 enter and ~83,411 output. These numbers observe immediately with the speed limiter’s allowed throughput — not with the tried request quantity. One other method of seeing that the speed limiter is accurately shaping site visitors.
Deciding between Price Limits and Quota Reservations
Use this flowchart to resolve what to configure:
Step 1: Do you have got a shared deployment with a number of customers?
- No → Price limiting alone is enough. Set capability to guard the GPU and transfer on.
- Sure → Proceed to Step 2.
Step 2: Are all customers equally essential?
- Sure → Price limiting alone could also be sufficient. Below saturation, all customers compete equally — first come, first served. If that’s acceptable, cease right here.
- No → Proceed to Step 3.
Step 3: Do any customers want assured minimal throughput?
- Sure → Add quota reservations. Dimension them to the minimal RPM every crucial client wants throughout peak competition.
- No, however some customers should be deprioritized → Use per-entity exceptions as an alternative of reservations. Cap the noisy neighbors quite than guaranteeing the crucial ones.
Step 4: Configure the unreserved pool.
- Don’t reserve 100% of capability. Depart 10–20% unreserved for ad-hoc site visitors, overflow, and new functions that haven’t been assigned reservations but.
Sensible configuration suggestions
Begin with fee limiting solely. Monitor your deployment’s site visitors patterns for every week. Have a look at peak RPM, who’s sending what, and whether or not anybody is persistently overconsuming. Then add reservations the place the info tells you they’re wanted.
Set utilization threshold at 70–80%. This provides the token bucket burst room to soak up quick spikes with out triggering fee limiting on each minor fluctuation. In our instance, we used 80% and the system dealt with 1.2× capability gracefully earlier than enforcement kicked in.
Monitor with OTEL metrics. After configuring fee limiting, examine these server-side metrics to substantiate issues are working:
- deployment.requests vs deployment.requests.rate_limited — are you rejecting the correct quantity?
- nvidia_gpu_utilization — is the mannequin nonetheless saturated or did fee limiting create headroom?
- nvidia_vllm:e2e_request_latency_seconds — is latency steady below load?
- deployment.concurrent_requests — are requests queuing up or flowing easily?
Reservation sizing formulation:
Reserved RPM = Capability × Reserved %
Instance: 1000 RPM × 30% = 300 RPM assured
Don’t confuse this with a fee restrict. A 30% reservation means “you’ll all the time get a minimum of 300 RPM, even when the system is saturated.” The entity can nonetheless use extra when capability is offered.
Abstract
| Function | Protects Towards | Use When |
|---|---|---|
| Price Limiting | GPU overload, runaway customers, latency spikes | At all times — it’s your security internet |
| Quota Reservations | Precedence hunger, noisy neighbors, SLA violations | A number of customers with completely different significance ranges |
| Per-entity exceptions | A particular client overconsuming | You wish to cap a loud neighbor with out reserving capability for others |
When contemplating Price Limiting vs. Quota Reservations: use every instrument the place it suits. Layer them the place the issue calls for it.