

{kind=link}
Amazon OpenSearch Service is a totally managed service that reduces operational overhead, supplies enterprise-grade safety, excessive availability, and scalability, and lets you rapidly deploy real-time search, analytics, and generative AI purposes. OpenSearch itself is an open-source, distributed search and analytics suite that helps a variety of use instances, together with real-time monitoring, log analytics, and full-text search. OpenSearch Service presents zero-ETL integrations with different Amazon Internet Service (AWS) companies, enabling seamless information entry and evaluation with out the necessity for sustaining complicated information pipelines.
Zero-ETL refers to a set of integrations designed to attenuate or eradicate the necessity to construct conventional extract, rework, load (ETL) pipelines. Conventional ETL processes may be time-consuming and tough to develop, preserve, and scale. In distinction, zero-ETL integrations enable direct, point-to-point information motion and can even help querying throughout information silos with out bodily shifting the information.
On this submit, we discover varied zero-ETL integrations out there with OpenSearch Service that may enable you to speed up innovation and enhance operational effectivity. We cowl following kinds of integrations, their key options, structure, advantages, pricing, limitation and a few normal finest practices.
- Log and storage integrations
- Database integrations
The next diagram illustrates the zero-ETL integration structure in AWS, displaying how varied AWS companies feed information into OpenSearch Service and its related dashboards:
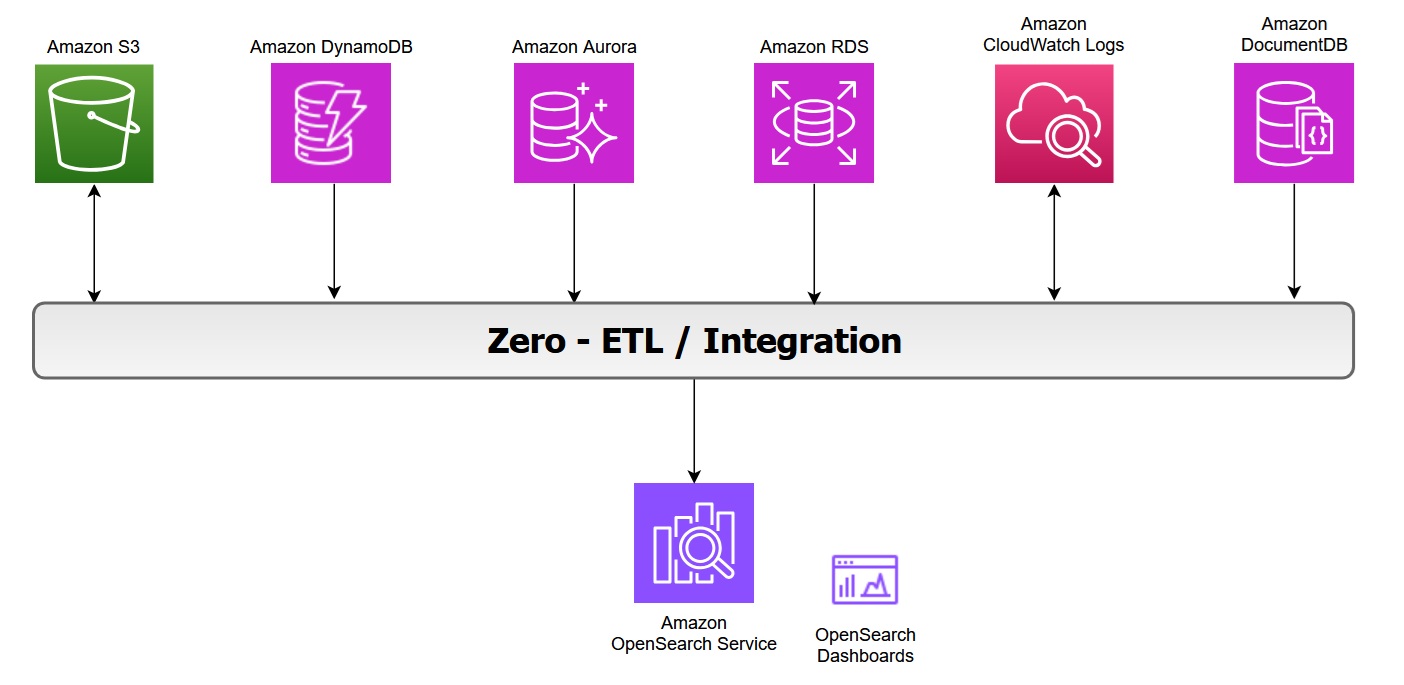
Zero-ETL integration with Amazon S3
Amazon OpenSearch Service direct queries with Amazon S3 supplies a zero-ETL integration to scale back the operational complexity of duplicating information or managing a number of analytics instruments by enabling you to immediately question their operational information, decreasing prices and time to motion.
Key options of this integration embody:
- In-place querying: You need to use wealthy analytics capabilities of OpenSearch Service SQL and PPL immediately on infrequently-queried information saved exterior of OpenSearch Service in Amazon S3.
- Selective information ingestion: You may select which information to deliver into OpenSearch Service for detailed evaluation, optimizing prices and rushing up queries with indexes like skipping or overlaying indexes.
The zero-ETL integration with Amazon S3 helps OpenSearch Service. For extra data on structure and have see the submit Modernize your information observability with Amazon OpenSearch Service zero-ETL integration with Amazon S3.
In log analytics use instances, we categorize operational log information into two sorts:
- Main information contains the newest and incessantly accessed logs used for real-time monitoring and evaluation.
- Secondary information consists of historic logs which might be accessed much less incessantly however retained for compliance or development evaluation.
You may offload occasionally queried information, reminiscent of archival or compliance information, to Amazon S3. With direct question, you’ll be able to analyze analytics from Amazon S3 with out information motion or duplication. Nevertheless, question efficiency in OpenSearch Service may decelerate while you’re accessing exterior information sources as a consequence of elements like community latency, information transformation, or massive information volumes. You may optimize your question efficiency by utilizing OpenSearch indexes, reminiscent of a skipping index, overlaying index, or materialized view.
Whereas Amazon S3 direct question integration with OpenSearch Service supplies on-demand entry to information saved in Amazon S3, you will need to keep in mind that OpenSearch’s alerting, monitoring, anomaly detection, and safety analytics capabilities can solely function on information that has been explicitly ingested into OpenSearch Service indices. These capabilities wouldn’t work with direct question with Amazon S3. Nevertheless, it should work if the information is listed with overlaying or materialized index.
Advantages
With direct queries with Amazon S3, you not must construct complicated ETL pipelines or incur the expense of duplicating information in each OpenSearch Service and Amazon S3 storage. You additionally save effort and time by not having to maneuver forwards and backwards between totally different instruments throughout your evaluation.
Pricing
OpenSearch Service individually expenses for the compute wanted to question your exterior information along with sustaining indexes in OpenSearch Service. Prices for Direct Question is predicated on the information quantity scanned, question execution time, question frequency and frequency with which the listed information in OpenSearch is saved up to date. For extra data, see Amazon OpenSearch Service Pricing.
Concerns
In case you might be utilizing OpenSearch service to question immediately information on Amazon S3, think about the limitations with Direct Question.
Finest practices
These are some normal and Amazon S3 suggestions for utilizing direct queries in OpenSearch Service. For extra data, see Suggestions for utilizing direct queries in Amazon OpenSearch Service.
- Use the
COALESCE SQLperform to deal with lacking columns and guarantee outcomes are returned. - Use limits in your queries to make sure you aren’t pulling an excessive amount of information again.
- For those who plan to investigate the identical dataset many occasions, create an listed view to completely ingest and index the information into OpenSearch Service and drop it when you have got accomplished the evaluation.
- Drop acceleration jobs and indexes once they’re not wanted.
- Ingest information into Amazon S3 utilizing partition codecs of 12 months, month, day, hour to hurry up queries.
- Whenever you construct skipping indexes, use Bloom filters for fields with excessive cardinality and min/max indexes for fields with massive worth ranges. Bloom filters are an area environment friendly probabilistic information construction that permits you to rapidly verify whether or not an merchandise is probably in a set. For prime-cardinality fields, think about using a value-based method to enhance question effectivity.
- Use Index State Administration to keep up storage for materialized views and overlaying indexes.
Zero-ETL integration with Amazon CloudWatch Logs
Amazon CloudWatch Logs serves as a centralized monitoring and storage resolution for log recordsdata generated throughout varied AWS companies. This unified logging service presents a extremely scalable platform the place all of your logging information converges into one manageable system. It supplies complete performance for log administration, together with real-time viewing, sample looking, field-based filtering, and safe archival capabilities. By presenting all logs chronologically in a unified stream, CloudWatch Logs eliminates the complexity of managing a number of log sources, reworking numerous logging information right into a coherent, time-ordered sequence of occasions.
The zero-ETL integration between Amazon CloudWatch and Amazon OpenSearch Service allows direct log evaluation and visualization whereas avoiding information redundancy, thereby decreasing each technical complexity and prices. Now you can leverage two extra question languages alongside the present CloudWatch Logs Insights QL when utilizing CloudWatch Logs, whereas as an OpenSearch person, you acquire the flexibility to question CloudWatch logs immediately.
Overview New Amazon CloudWatch and Amazon OpenSearch Service launch an built-in analytics expertise, to discover how the combination works between OpenSearch Service and Amazon CloudWatch Logs.
Advantages
- The improved CloudWatch Logs Insights console now incorporates OpenSearch PPL and SQL performance. Customers can carry out complicated log evaluation utilizing SQL JOIN operations and varied features (together with JSON, mathematical, datetime, and string operations). The PPL choice supplies extra information filtering and evaluation capabilities.
- The mixing presents ready-to-use dashboards for varied AWS companies like Amazon Digital Personal Cloud (VPC), AWS CloudTrail, and AWS Internet Software Firewall (WAF). These pre-configured visualizations allow fast insights into metrics reminiscent of circulate patterns, high customers, information switch volumes, and temporal evaluation, with out requiring guide dashboard configuration.
- Now you can analyze CloudWatch logs by OpenSearch UI Uncover and execute SQL and PPL queries. On the writing of this submit, the question execution is restricted to 50 log teams.
- The direct entry and evaluation of CloudWatch information inside OpenSearch Service removes the necessity for conventional ETL processes, eliminates separate information ingestion pipelines and avoids information duplication. This streamlined method considerably reduces each storage bills and operational complexity. It delivers a extra environment friendly information administration resolution that simplifies your complete workflow whereas sustaining cost-effectiveness.
Pricing
Whenever you use OpenSearch Service direct queries, you incur separate expenses for OpenSearch Service and the useful resource used to course of and retailer your information on Amazon CloudWatch Logs. As you run direct queries, you see expenses for OpenSearch Compute Items (OCUs) per hour, listed as DirectQuery OCU utilization kind in your invoice.
- For interactive queries, OpenSearch Service handles every question with a separate pre-warmed job, with out sustaining an prolonged session.
- For listed view queries, the listed information is saved in an OpenSearch Serverless assortment the place you might be charged for information listed (IndexingOCU), information searched (SearchOCU), and information saved in GB.
You could find a pricing instance on working an OpenSearch dashboard from both OpenSearch UI or CloudWatch Logs (pricing instance n°7).
For extra pricing data, see Amazon OpenSearch Service Direct Question pricing.
Concerns
Along with the OpenSearch Service “direct queries” normal limitations, if you’re direct querying information in CloudWatch Logs, the next limitations apply:
- The direct question integration with CloudWatch Logs is simply out there on OpenSearch Service collections and the OpenSearch person interface.
- OpenSearch Serverless collections have networked payload limitations of 100 MiB.
- CloudWatch Logs helps VPC Move Logs, CloudTrail, and AWS WAF dashboard integrations put in from the console.
Finest practices
Moreover the normal suggestions of OpenSearch Service direct querying, when utilizing OpenSearch Service to direct question information in CloudWatch Logs, the next is really helpful:
- Specify the log group names inside logGroupIdentifier in logGroups command to question a number of log teams in a single question, see Multi-log group features.
- Enclose sure fields in backticks to efficiently question them when utilizing SQL or PPL instructions. Backticks are wanted for fields with particular characters, reminiscent of `@SessionToken` or `LogGroup-A` (non-alphabetic and non-numeric). Consult with CloudWatch Logs Suggestions to see an instance.
Zero-ETL integration with Amazon DynamoDB
Amazon DynamoDB zero-ETL integration with OpenSearch Service allows you to carry out a search in your DynamoDB information by mechanically replicating and remodeling it with out customized code or infrastructure. This zero-ETL integration makes use of Amazon OpenSearch Ingestion to synchronize information between Amazon DynamoDB and OpenSearch Service cluster or OpenSearch Serverless assortment inside seconds of it being out there.
It makes use of DynamoDB export to Amazon S3 to create an preliminary snapshot to load into OpenSearch Service. After the snapshot has been loaded, the plugin makes use of DynamoDB Streams to duplicate any additional adjustments in close to actual time. Activate point-in-time restoration (PITR) for export and the DynamoDB Streams function for ongoing replication.
This function lets you seize item-level adjustments in your desk and push the adjustments to a stream. Each merchandise in tables is processed as an occasion in OpenSearch Ingestion and may be modified with processors. You may as well specify index mapping templates inside ingestion pipelines to make sure that your Amazon DynamoDB fields are mapped to the right fields in your OpenSearch indices.
To be taught extra, see DynamoDB zero-ETL integration with Amazon OpenSearch Service within the AWS documentation.
When configuring zero-ETL between DynamoDB and OpenSearch Service, think about the variations between the information fashions. You’ve the next choices with information format:
- Passthrough: Every merchandise in DynamoDB desk is immediately mapped to 1 doc in OpenSearch Index.
- Routing: A single DynamoDB desk mapped to a number of OpenSearch Service indices. In DynamoDB, it is not uncommon to retailer denormalized information in a single desk to optimize for entry patterns. For instance, a single DynamoDB desk containing each buyer profiles and order data may be routed to separate OpenSearch Service indices:
- Buyer attributes → ‘clients’ index
- Order attributes → ‘orders’ index
You may obtain this by utilizing the conditional routing function within the OpenSearch ingestion pipeline.
- Merge: In some use instances, it’s essential to mix information from a number of DynamoDB tables right into a single OpenSearch index. You need to use AWS Lambda integration with OpenSearch Ingestion to carry out lookups on different DynamoDB tables and merge information from a number of DynamoDB tables.
Pricing
There isn’t any extra price to make use of this function aside from the price of the present underlying elements, together with OpenSearch Ingestion expenses OpenSearch Compute Items (OCUs) which is used to duplicate information between Amazon DynamoDB and OpenSearch Service. Moreover, this function makes use of Amazon DynamoDB Streams for the change information seize (CDC), and also you incur the usual prices for Amazon DynamoDB Streams.
Concerns
Think about the next limitations while you arrange an OpenSearch Ingestion pipeline for DynamoDB:
- On the writing of this submit, the OpenSearch Ingestion integration with DynamoDB doesn’t help cross-Area and cross-account ingestion.
- An OpenSearch Ingestion pipeline helps just one DynamoDB desk as its supply.
Finest practices
For full data, see Finest practices for working with DynamoDB zero-ETL integration and OpenSearch Service
Integration with Amazon Aurora and Amazon RDS
Amazon RDS and Amazon Aurora integration with OpenSearch Service eliminates complicated information pipelines and allows close to real-time information synchronization between Amazon Aurora and Amazon RDS databases (together with RDS for MySQL and RDS for PostgreSQL) with superior search capabilities on transactional databases. You need to use an OpenSearch Ingestion pipeline with Amazon RDS or Amazon Aurora to export current information and stream adjustments (reminiscent of create, replace, and delete) to OpenSearch Service domains and collections. The OpenSearch Ingestion pipeline incorporates change information seize (CDC) infrastructure to supply a high-scale, low-latency method to repeatedly stream information from Amazon RDS or Amazon Aurora.
This automated course of retains your information constantly updated in OpenSearch Service, making it available for search and evaluation objective. The pipeline ensures information consistency by repeatedly polling or receiving adjustments from the Amazon Aurora cluster or Amazon RDS and updating the corresponding paperwork within the OpenSearch index. OpenSearch Ingestion helps end-to-end acknowledgement to make sure information sturdiness. An OpenSearch Ingestion pipeline additionally maps incoming occasion actions into corresponding bulk indexing actions to assist ingest paperwork. This retains information constant, so that each information change in Amazon RDS is reconciled with the corresponding doc adjustments in OpenSearch.
For particulars on the structure, consult with Integrating Amazon OpenSearch Ingestion with Amazon RDS and Amazon Aurora. To get began, consult with OpenSearch Ingestion pipeline with Amazon RDS or Utilizing an OpenSearch Ingestion pipeline with Amazon Aurora.
Pricing
There isn’t any extra cost for utilizing this function past the price of your current underlying assets, reminiscent of OpenSearch Service, OpenSearch Ingestion pipelines (OCUs), and Amazon RDS or Amazon Aurora. Further prices might embody storage used for enabling enhanced binlogs for MySQL and WAL logs for PostgreSQL for change information seize. You additionally incur storage prices for snapshot exports out of your database to Amazon S3 used for the preliminary information.
Concerns
Think about the next limitations while you arrange the combination for Amazon RDS or Amazon Aurora:
- Help each Aurora MySQL or RDS for MySQL (8.0 and above) and Aurora PostgreSQL or RDS for PostgreSQL (16 and above).
- Requires same-Area and same-account deployment, major keys for optimum synchronization, and presently has no information definition language (DDL) assertion help.
- The mixing solely helps one Aurora PostgreSQL database per pipeline.
- The present pipeline configuration can’t be up to date to ingest information from a unique database and/or a unique desk. To replace the database and/or desk identify of a pipeline, cease the pipeline and restart it with an up to date configuration or create a brand new pipeline.
- Make sure that the Amazon Aurora or Amazon RDS cluster has authentication enabled utilizing AWS Secrets and techniques Supervisor, which is the one supported authentication mechanism.
Finest practices
The next are some finest practices to comply with whereas organising the combination with OpenSearch Service:
- If a mapping template just isn’t laid out in OpenSearch, it mechanically assigns area sorts utilizing dynamic mapping based mostly on the primary doc obtained. Nevertheless, it’s at all times really helpful to outline area sorts explicitly by making a mapping template that fits your necessities.
- To keep up information consistency, the first and international keys of tables stay unchanged.
- You may configure the dead-letter queues (DLQ) in your OpenSearch Ingestion pipeline. For those who’ve configured the queue, OpenSearch Service sends all failed paperwork that may’t be ingested as a consequence of dynamic mapping failures to the queue.
- Monitor really helpful CloudWatch metrics to measure the efficiency of your ingestion pipeline.
Zero-ETL integration with Amazon DocumentDB
Amazon Doc DB is a totally managed database service constructed for JSON information administration at scale. It presents built-in textual content and vector search functionalities. By leveraging OpenSearch Service, you’ll be able to execute search analytics, together with options like fuzzy matching, synonym detection, cross-collection queries, and multilingual search capabilities on DocumentDB information.
The zero-ETL integration initiates the method with a full historic information extraction to OpenSearch utilizing an ingestion pipeline. After the preliminary information load is accomplished, the pipelines learn from Amazon DocumentDB change streams making certain close to real-time information consistency between the 2 methods. OpenSearch organizes the incoming information into indexes, with flexibility to both consolidate information from a DocumentDB assortment right into a single index or partition information throughout a number of indices. The ingestion pipelines synchronize all create, replace, and delete operations from the DocumentDB assortment, sustaining corresponding doc modifications in OpenSearch. This ensures each information methods stay synchronised.
The pipelines provide configurable routing choices, permitting information from a single assortment to be written to 1 index or conditionally path to a number of indexes. Customers can configure ingestion pipelines to stream information from Amazon DocumentDB to OpenSearch Service by three major modes specifically full load solely, streaming change occasions with out preliminary full load and full load adopted by change streams. You may as well monitor the state of ingestion pipelines within the OpenSearch service console. Moreover, you need to use Amazon Cloudwatch to supply real-time metrics and logs and organising alerts.
Pricing
There isn’t any extra cost for utilizing this function aside from the price of your current underlying assets, together with OpenSearch Service, OpenSearch Ingestion pipelines (OCUs), and Amazon DocumentDB. The mixing performs an preliminary full load of Amazon DocumentDB information and repeatedly streams ongoing adjustments to OpenSearch Service utilizing change streams. The change streams function is disabled by default and doesn’t incur any extra expenses till the function is enabled. Utilizing change streams on a DocumentDB cluster incurs extra learn and write enter/output (I/O), in addition to storage prices.
To be taught extra on pricing see the DocumentDB pricing web page.
Concerns
The next are the limitations for the DocumentDB to OpenSearch Service integration:
- Just one Amazon DocumentDB assortment because the supply per pipeline is supported.
- Cross-region and cross-account information ingestion just isn’t supported.
- Amazon DocumentDB elastic clusters are usually not supported, solely instance-based clusters are supported.
- AWS Secrets and techniques Supervisor is the one supported authentication mechanism.
- You may’t replace an current pipeline configuration to ingest information from a unique database and/or a unique assortment. To replace the database and/or assortment identify of a pipeline, create a brand new pipeline.
Finest practices
The next are some finest practices to comply with whereas organising the DocumentDB zero-ETL with OpenSearch Service:
- Configure dead-letter queues (DLQ) to deal with any failed doc ingestion.
- Configure AWS Secrets and techniques Supervisor and allow secrets and techniques rotation to supply the pipeline safe entry.
- For those who’re utilizing change streams in DocumentDB, it’s essential to increase the retention interval to as much as 7 days. This ensures you don’t lose any information adjustments through the ingestion course of.
To get began, see zero-ETL integration of Amazon DocumentDB with OpenSearch Service.
Advantages for Database Integrations
With zero-ETL integrations, you need to use the highly effective search and analytics options of OpenSearch Service immediately in your newest database information. These embody full-text search, fuzzy search, auto-complete, and vector seek for machine studying (ML) workloads—enabling clever, real-time experiences that improve your purposes and enhance person satisfaction. This integration makes use of change streams to automate the synchronisation of transactional information from Amazon Aurora, Amazon RDS, Amazon DynamoDB and Amazon DocumentDB to OpenSearch Service with out guide intervention. As soon as the information is offered in OpenSearch Service, you’ll be able to carry out real-time searches to rapidly retrieve related outcomes to your purposes.This eliminates the necessity for guide Extract-Remodel-Load (ETL) processes, reduces operational complexity, and accelerates time-to-insight for real-time dashboards, search, and analytics.
Conclusion
On this submit, you discovered that zero-ETL integrations characterize a big development in simplifying information analytics workflows and decreasing operational complexity. As you’ve explored all through this submit, these integrations provide a number of benefits reminiscent of elimination of complicated ETL pipelines and lowered infrastructure and operational prices by eradicating the necessity for intermediate storage and processing that improve developer productiveness.
It’s time to speed up your analytics journey with OpenSearch Service zero ETL – the place your information flows seamlessly, eliminating complicated pipelines and delivering real-time insights. Get began with Amazon OpenSearch Service or be taught extra about integrations with different companies and purposes within the AWS documentation.
Concerning the authors