

{kind=link}
Widespread streaming knowledge enrichment patterns in Amazon Managed Service for Apache FlinkStream knowledge processing lets you act on knowledge in actual time. Actual-time knowledge analytics may help you could have on-time and optimized responses whereas bettering total buyer expertise.
Apache Flink is a distributed computation framework that permits for stateful real-time knowledge processing. It offers a single set of APIs for constructing batch and streaming jobs, making it simple for builders to work with bounded and unbounded knowledge. Apache Flink offers completely different ranges of abstraction to cowl a wide range of occasion processing use circumstances.
Amazon Managed Service for Apache Flink (Amazon MSF) is an AWS service that gives a serverless infrastructure for operating Apache Flink functions. This makes it simple for builders to construct extremely obtainable, fault tolerant, and scalable Apache Flink functions without having to grow to be an skilled in constructing, configuring, and sustaining Apache Flink clusters on AWS.
Knowledge streaming workloads usually require knowledge within the stream to be enriched by way of exterior sources (comparable to databases or different knowledge streams). For instance, assume you might be receiving coordinates knowledge from a GPS system and want to grasp how these coordinates map with bodily geographic areas; it is advisable enrich it with geolocation knowledge. You need to use a number of approaches to counterpoint your real-time knowledge in Amazon MSF in your use case and Apache Flink abstraction degree. Every technique has completely different results on the throughput, community visitors, and CPU (or reminiscence) utilization. On this publish, we cowl these approaches and focus on their advantages and disadvantages.
Knowledge enrichment patterns
Knowledge enrichment is a course of that appends extra context and enhances the collected knowledge. The extra knowledge usually is collected from a wide range of sources. The format and the frequency of the information updates might vary from as soon as in a month to many instances in a second. The next desk reveals just a few examples of various sources, codecs, and replace frequency.
| Knowledge | Format | Replace Frequency |
| IP handle ranges by nation | CSV | As soon as a month |
| Firm group chart | JSON | Twice a yr |
| Machine names by ID | CSV | As soon as a day |
| Worker data | Desk (Relational database) | A number of instances a day |
| Buyer data | Desk (Non-relational database) | A number of instances an hour |
| Buyer orders | Desk (Relational database) | Many instances a second |
Based mostly on the use case, your knowledge enrichment utility might have completely different necessities by way of latency, throughput, or different elements. The rest of the publish dives deeper into completely different patterns of information enrichment in Amazon MSF, that are listed within the following desk with their key traits. You’ll be able to select the very best sample primarily based on the trade-off of those traits.
| Enrichment Sample | Latency | Throughput | Accuracy if Reference Knowledge Adjustments | Reminiscence Utilization | Complexity |
| Pre-load reference knowledge in Apache Flink Process Supervisor reminiscence | Low | Excessive | Low | Excessive | Low |
| Partitioned pre-loading of reference knowledge in Apache Flink state | Low | Excessive | Low | Low | Low |
| Periodic Partitioned pre-loading of reference knowledge in Apache Flink state | Low | Excessive | Medium | Low | Medium |
| Per-record asynchronous lookup with unordered map | Medium | Medium | Excessive | Low | Low |
| Per-record asynchronous lookup from an exterior cache system | Low or Medium (Relying on Cache storage and implementation) | Medium | Excessive | Low | Medium |
| Enriching streams utilizing the Desk API | Low | Excessive | Excessive | Low – Medium (relying on the chosen be a part of operator) | Low |
Enrich streaming knowledge by pre-loading the reference knowledge
When the reference knowledge is small in measurement and static in nature (for instance, nation knowledge together with nation code and nation title), it’s advisable to counterpoint your streaming knowledge by pre-loading the reference knowledge, which you are able to do in a number of methods.
To see the code implementation for pre-loading reference knowledge in numerous methods, confer with the GitHub repo. Observe the directions within the GitHub repository to run the code and perceive the information mannequin.
Pre-loading of reference knowledge in Apache Flink Process Supervisor reminiscence
The only and likewise quickest enrichment technique is to load the enrichment knowledge into every of the Apache Flink process managers’ on-heap reminiscence. To implement this technique, you create a brand new class by extending the RichFlatMapFunction summary class. You outline a world static variable in your class definition. The variable might be of any kind, the one limitation is that it ought to prolong java.io.Serializable; for instance, java.util.HashMap. Inside the open() technique, you outline a logic that hundreds the static knowledge into your outlined variable. The open() technique is at all times referred to as first, through the initialization of every process in Apache Flink’s process managers, which makes positive the entire reference knowledge is loaded earlier than the processing begins. You implement your processing logic by overriding the processElement() technique. You implement your processing logic and entry the reference knowledge by its key from the outlined world variable.
The next structure diagram reveals the total reference knowledge load in every process slot of the duty supervisor:
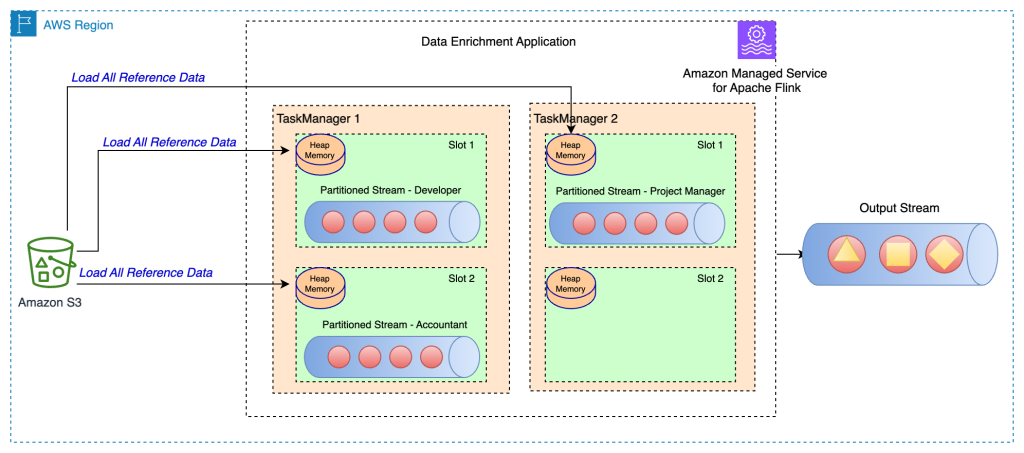
This technique has the next advantages:
- Simple to implement
- Low latency
- Can assist excessive throughput
Nonetheless, it has the next disadvantages:
- If the reference knowledge is giant in measurement, the Apache Flink process supervisor might run out of reminiscence.
- Reference knowledge can grow to be stale over a time period.
- A number of copies of the identical reference knowledge are loaded in every process slot of the duty supervisor.
- Reference knowledge ought to be small to slot in the reminiscence allotted to a single process slot. In Amazon MSF, every Kinesis Processing Unit (KPU) has 4 GB of reminiscence, out of which 3 GB can be utilized for heap reminiscence. If
ParallelismPerKPUin Amazon MSF is ready to 1, one process slot runs in every process supervisor, and the duty slot can use the entire 3 GB of heap reminiscence. IfParallelismPerKPUis ready to a price larger than 1, the three GB of heap reminiscence is distributed throughout a number of process slots within the process supervisor. In case you’re deploying Apache Flink in Amazon EMR or in a self-managed mode, you possibly can tunetaskmanager.reminiscence.process.heap.measurementto extend the heap reminiscence of a process supervisor.
Partitioned pre-loading of reference knowledge in Apache Flink State
On this strategy, the reference knowledge is loaded and stored within the Apache Flink state retailer firstly of the Apache Flink utility. To optimize the reminiscence utilization, first the primary knowledge stream is split by a specified discipline by way of the keyBy() operator throughout all process slots. Moreover, solely the portion of the reference knowledge that corresponds to every process slot is loaded within the state retailer.That is achieved in Apache Flink by creating the category PartitionPreLoadEnrichmentData, extending the RichFlatMapFunction summary class. Inside the open technique, you override the ValueStateDescriptor technique to create a state deal with. Within the referenced instance, the descriptor is known as locationRefData, the state key kind is String, and the worth kind is Location. On this code, we use ValueState in comparison with MapState as a result of we solely maintain the placement reference knowledge for a selected key. For instance, after we question Amazon S3 to get the placement reference knowledge, we question for the particular position and get a selected location as a price.
In Apache Flink, ValueState is used to carry a particular worth for a key, whereas MapState is used to carry a mixture of key-value pairs. This system is helpful when you could have a big static dataset that’s tough to slot in reminiscence as an entire for every partition.
The next structure diagram reveals the load of reference knowledge for the particular key for every partition of the stream.
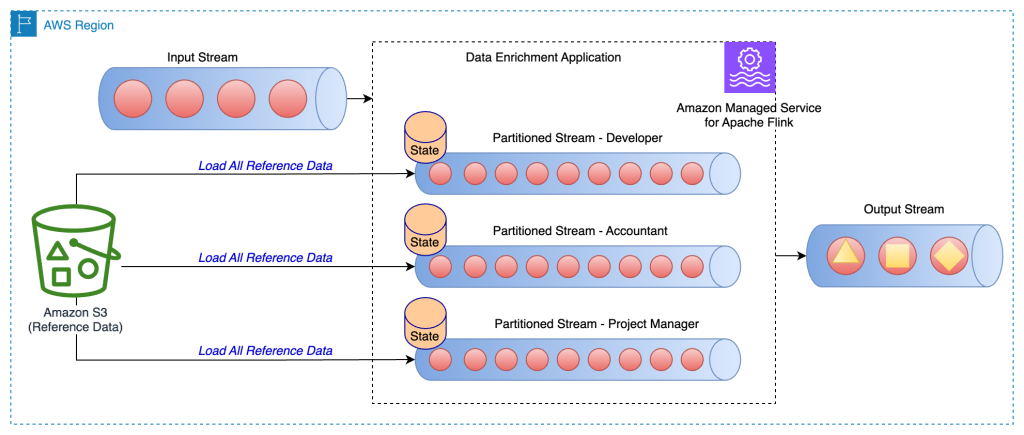
For instance, our reference knowledge within the pattern GitHub code has roles that are mapped to every constructing. As a result of the stream is partitioned by roles, solely the particular constructing data per position is required to be loaded for every partition because the reference knowledge.This technique has the next advantages:
- Low latency.
- Can assist excessive throughput.
- Reference knowledge for particular partition is loaded within the keyed state.
- In Amazon MSF, the default state retailer configured is RocksDB. RocksDB can make the most of a good portion of 1 GB of managed reminiscence and 50 GB of disk area supplied by every KPU. This offers sufficient room for the reference knowledge to develop.
Nonetheless, it has the next disadvantages:
- Reference knowledge can grow to be stale over a time period
Periodic partitioned pre-loading of reference knowledge in Apache Flink State
This strategy is a fine-tune of the earlier method, the place every partitioned reference knowledge is reloaded on a periodic foundation to refresh the reference knowledge. That is helpful in case your reference knowledge modifications often.
The next structure diagram reveals the periodic load of reference knowledge for the particular key for every partition of the stream:
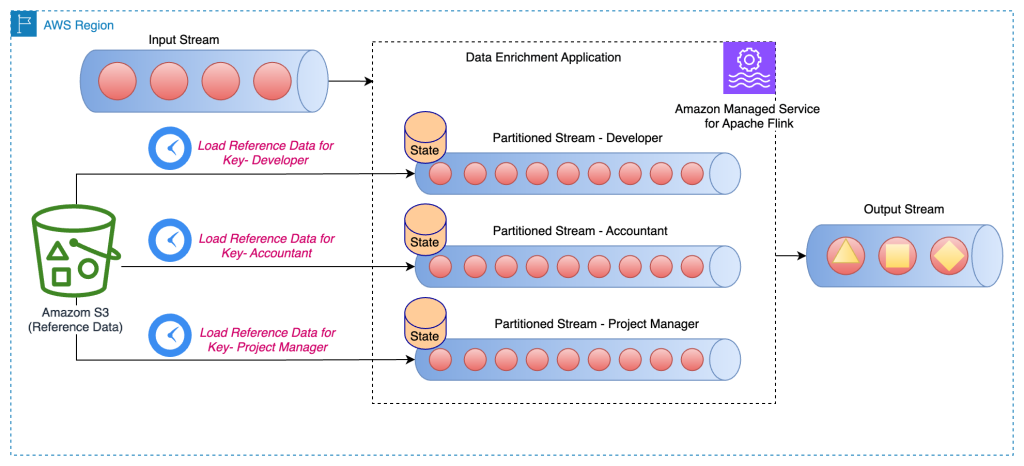
On this strategy, the category PeriodicPerPartitionLoadEnrichmentData is created, extending the KeyedProcessFunction class. Much like the earlier sample, within the context of the GitHub instance, ValueState is advisable right here as a result of every partition solely hundreds a single worth for the important thing. In the identical method as talked about earlier, within the open technique, you outline the ValueStateDescriptor to deal with the worth state and outline a runtime context to entry the state.
Inside the processElement technique, load the worth state and fix the reference knowledge (within the referenced GitHub instance, we connected buildingNo to the shopper knowledge). Additionally register a timer service to be invoked when the processing time passes the given time. Within the pattern code, the timer service is scheduled to be invoked periodically (for instance, each 60 seconds). Within the onTimer technique, replace the state by making a name to reload the reference knowledge for the particular position.
This technique has the next advantages:
- Low latency.
- Can assist excessive throughput.
- Reference knowledge for particular partitions is loaded within the keyed state.
- Reference knowledge is refreshed periodically.
- In Amazon MSF, the default state retailer configured is RocksDB. Additionally, 50 GB of disk area supplied by every KPU. This offers sufficient room for the reference knowledge to develop.
Nonetheless, it has the next disadvantages:
- If the reference knowledge modifications steadily, the appliance nonetheless has stale knowledge relying on how steadily the state is reloaded
- The applying can face load spikes throughout reload of reference knowledge
Enrich streaming knowledge utilizing per-record lookup
Though pre-loading of reference knowledge offers low latency and excessive throughput, it is probably not appropriate for sure sorts of workloads, comparable to the next:
- Reference knowledge updates with excessive frequency
- Apache Flink must make an exterior name to compute the enterprise logic
- Accuracy of the output is essential and the appliance shouldn’t use stale knowledge
Usually, for a lot of these use circumstances, builders trade-off excessive throughput and low latency for knowledge accuracy. On this part, you find out about just a few of frequent implementations for per-record knowledge enrichment and their advantages and drawbacks.
Per-record asynchronous lookup with unordered map
In a synchronous per-record lookup implementation, the Apache Flink utility has to attend till it receives the response after sending each request. This causes the processor to remain idle for a major interval of processing time. As a substitute, the appliance can ship a request for different components within the stream whereas it waits for the response for the primary factor. This fashion, the wait time is amortized throughout a number of requests and due to this fact it will increase the method throughput. Apache Flink offers asynchronous I/O for exterior knowledge entry. Whereas utilizing this sample, it’s important to determine between unorderedWait (the place it emits the consequence to the following operator as quickly because the response is obtained, disregarding the order of the factor on the stream) and orderedWait (the place it waits till all inflight I/O operations full, then sends the outcomes to the following operator in the identical order as unique components had been positioned on the stream). Normally, when downstream shoppers disregard the order of the weather within the stream, unorderedWait offers higher throughput and fewer idle time. Go to Enrich your knowledge stream asynchronously utilizing Managed Service for Apache Flink to study extra about this sample.
The next structure diagram reveals how an Apache Flink utility on Amazon MSF does asynchronous calls to an exterior database engine (for instance Amazon DynamoDB) for each occasion in the primary stream:
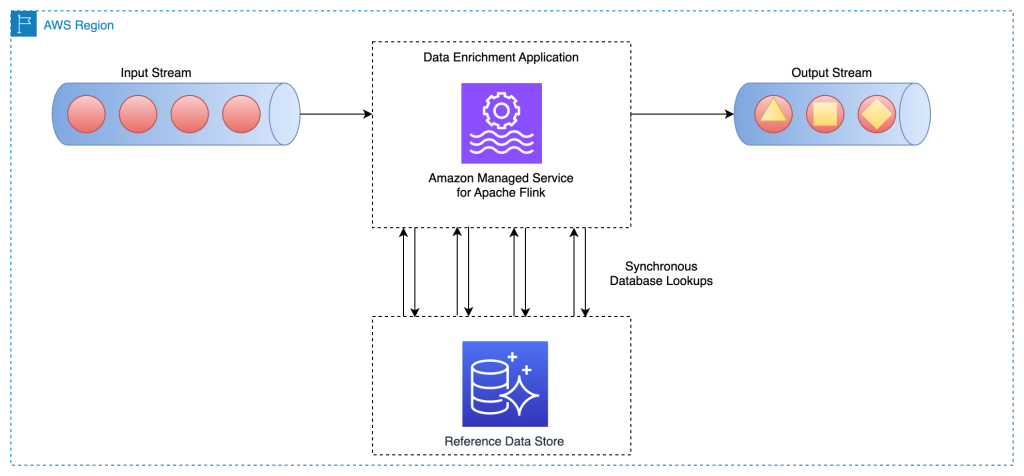
This technique has the next advantages:
- Nonetheless fairly easy and simple to implement
- Reads probably the most up-to-date reference knowledge
Nonetheless, it has the next disadvantages:
- It generates a heavy learn load for the exterior system (for instance, a database engine or an exterior API) that hosts the reference knowledge
- Total, it may not be appropriate for techniques that require excessive throughput with low latency
Per-record asynchronous lookup from an exterior cache system
A strategy to improve the earlier sample is to make use of a cache system to boost the learn time for each lookup I/O name. You need to use Amazon ElastiCache for caching, which accelerates utility and database efficiency, or as a major knowledge retailer to be used circumstances that don’t require sturdiness like session shops, gaming leaderboards, streaming, and analytics. ElastiCache is suitable with Redis and Memcached.
For this sample to work, you could implement a caching sample for populating knowledge within the cache storage. You’ll be able to select between a proactive or reactive strategy relying your utility aims and latency necessities. For extra data, confer with Caching patterns.
The next structure diagram reveals how an Apache Flink utility calls to learn the reference knowledge from an exterior cache storage (for instance, Amazon ElastiCache for Redis). Knowledge modifications have to be replicated from the primary database (for instance, Amazon Aurora) to the cache storage by implementing one of many caching patterns.
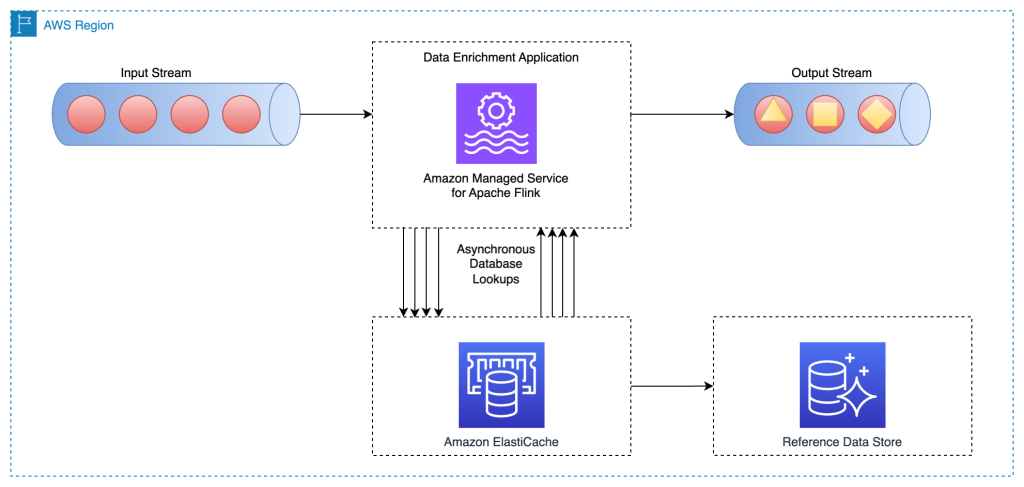
Implementation for this knowledge enrichment sample is much like the per-record asynchronous lookup sample; the one distinction is that the Apache Flink utility makes a connection to the cache storage, as a substitute of connecting to the first database.
This technique has the next advantages:
- Higher throughput as a result of caching can speed up utility and database efficiency
- Protects the first knowledge supply from the learn visitors created by the stream processing utility
- Can present decrease learn latency for each lookup name
- Total, may not be appropriate for medium to excessive throughput techniques that wish to enhance knowledge freshness
Nonetheless, it has the next disadvantages:
- Extra complexity of implementing a cache sample for populating and syncing the information between the first database and the cache storage
- There’s a probability for the Apache Flink stream processing utility to learn stale reference knowledge relying on what caching sample is carried out
- Relying on the chosen cache sample (proactive or reactive), the response time for every enrichment I/O might differ, due to this fact the general processing time of the stream might be unpredictable
Alternatively, you possibly can keep away from these complexities through the use of the Apache Flink JDBC connector for Flink SQL APIs. We focus on enrichment stream knowledge by way of Flink SQL APIs in additional element later on this publish.
Enrich stream knowledge by way of one other stream
On this sample, the information in the primary stream is enriched with the reference knowledge in one other knowledge stream. This sample is nice to be used circumstances during which the reference knowledge is up to date steadily and it’s attainable to carry out change knowledge seize (CDC) and publish the occasions to a knowledge streaming service comparable to Apache Kafka or Amazon Kinesis Knowledge Streams. This sample is helpful within the following use circumstances, for instance:
- Buyer buy orders are printed to a Kinesis knowledge stream, after which be a part of with buyer billing data in a DynamoDB stream
- Knowledge occasions captured from IoT gadgets ought to enrich with reference knowledge in a desk in Amazon Relational Database Service (Amazon RDS)
- Community log occasions ought to enrich with the machine title on the supply (and the vacation spot) IP addresses
The next structure diagram reveals how an Apache Flink utility on Amazon MSF joins knowledge in the primary stream with the CDC knowledge in a DynamoDB stream.
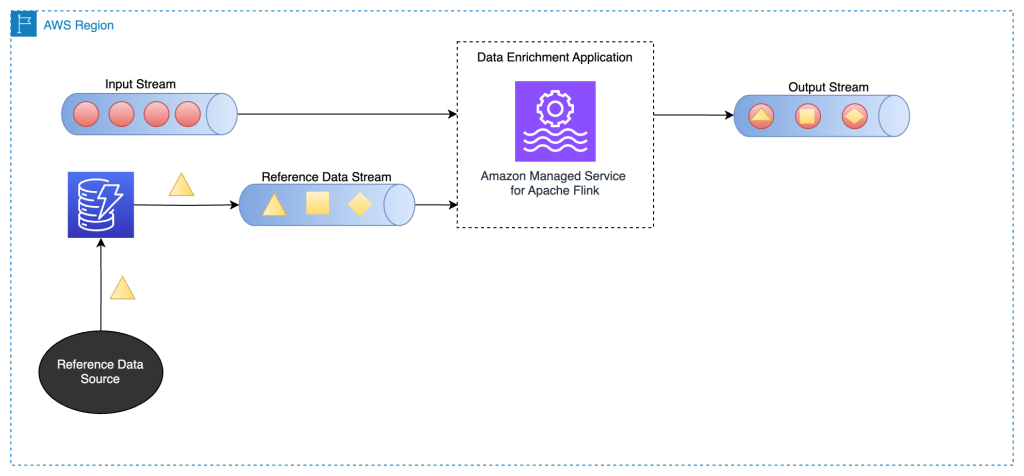
To counterpoint streaming knowledge from one other stream, we use a typical stream to stream be a part of patterns, which we clarify within the following sections.
Enrich streams utilizing the Desk API
Apache Flink Desk APIs present larger abstraction for working with knowledge occasions. With Desk APIs, you possibly can outline your knowledge stream as a desk and fix the information schema to it.
On this sample, you outline tables for every knowledge stream after which be a part of these tables to realize the information enrichment targets. Apache Flink Desk APIs assist several types of be a part of situations, like interior be a part of and outer be a part of. Nonetheless, you wish to keep away from these should you’re coping with unbounded streams as a result of these are useful resource intensive. To restrict the useful resource utilization and run joins successfully, it is best to use both interval or temporal joins. An interval be a part of requires one equi-join predicate and a be a part of situation that bounds the time on either side. To higher perceive the right way to implement an interval be a part of, confer with Get began with Amazon Managed Service for Apache Flink (Desk API).
In comparison with interval joins, temporal desk joins don’t work with a time interval inside which completely different variations of a report are stored. Information from the primary stream are at all times joined with the corresponding model of the reference knowledge on the time specified by the watermark. Due to this fact, fewer variations of the reference knowledge stay within the state. Notice that the reference knowledge might or might not have a time factor related to it. If it doesn’t, you could want so as to add a processing time factor for the be a part of with the time-based stream.
Within the following instance code snippet, the update_time column is added to the currency_rates reference desk from the change knowledge seize metadata comparable to Debezium. Moreover, it’s used to outline a watermark technique for the desk.
CREATE TABLE currency_rates (
foreign money STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3) METADATA FROM `values.supply.timestamp` VIRTUAL,
WATERMARK FOR update_time AS update_time,
PRIMARY KEY(foreign money) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'worth.format' = 'debezium-json',
/* ... */
);
This technique has the next advantages:
- Simple to implement
- Low latency
- Can assist excessive throughput when reference knowledge is an information stream
SQL APIs present larger abstractions over how the information is processed. For extra complicated logic round how the be a part of operator ought to course of, we suggest you at all times begin with SQL APIs first and use DataStream APIs if you really want to.
Conclusion
On this publish, we demonstrated completely different knowledge enrichment patterns in Amazon MSF. You need to use these patterns and discover the one which addresses your wants and shortly develop a stream processing utility.
For additional studying on Amazon MSF, go to the official product web page.
Concerning the Authors