

{kind=link}
Neglect content material moderation. A brand new class of open fashions is right here to truly suppose by your guidelines as a substitute of blindly guessing them. Meet gpt-oss-safeguard: fashions that interpret your guidelines and implement them with seen reasoning. No, huge retraining. No, black-box security calls. Sure, versatile and open-weight methods you management. On this article, we’ll break down what the safeguard fashions are, how they work, the place they shine (and stumble), and how one can begin testing your personal insurance policies immediately.
What’s gpt-oss-safeguard?
Constructed on the gpt-oss structure with 20B complete parameters (and 120B in a unique variant), these fashions are fine-tuned particularly for security classification duties with assist for the Concord response format, which separates reasoning into devoted channels for auditability and transparency. The mannequin sits on the heart of OpenAI’s perception in defence of depth.
The mannequin takes two inputs directly:
- A coverage (~system instruction)
- The content material which is the topic of that coverage (~question)
Upon processing these inputs, it produces a conclusion about the place the content material falls, together with its reasoning.
The best way to entry?
Entry gpt-oss-safeguard fashions on Hugging Face at HuggingFace Collections.
Or you possibly can entry it from on-line platforms which provide a playground, like Groq, OpenRouter and so forth.
The demonstrations on this article have been made on the playground of gpt-oss-safeguard supplied by Groq.
Palms-On: Testing the mannequin on our personal coverage
To check how nicely the mannequin (20b variant) conceives and makes use of the insurance policies in output sanitation, I examined it on a coverage curated for filtering animal names:
Coverage: Animal Title Detection v1.0
GoalResolve if the enter textual content incorporates a number of animal names. Return a label and the record of detected names.
Labels
ANIMAL_NAME_PRESENT — No less than one animal identify is current.
ANIMAL_NAME_ABSENT — No animal names are current.
UNCERTAIN — Ambiguous; the mannequin can't confidently resolve.
Definitions
Animal: Any member of kingdom Animalia (mammals, birds, reptiles, amphibians, fish, bugs, arachnids, mollusks, and so forth.), together with extinct species (e.g., dinosaur names) and zodiac animals.
What counts as a “identify”: Canonical widespread names (canine, African gray parrot), scientific/Latin binomials (Canis lupus), multiword names (sea lion), slang/colloquialisms (kitty, pup), and animal emojis (🐶, 🐍).
Morphology: Case-insensitive; singular/plural each depend; hyphenation and spacing variants depend (sea-lion/sea lion).
Languages: Apply in any language; if the phrase is an animal in that language, it counts (e.g., perro, gato).
Exclusions / Disambiguation
Substrings inside unrelated phrases don't depend (cat in “disaster”, ant in “vintage”).
Meals dishes or merchandise solely depend if an animal identify seems as a standalone token or clear multiword identify (e.g., “rooster curry” → counts; “hotdog” → doesn't).
Manufacturers/groups/fashions (Jaguar automotive, Detroit Lions) depend provided that the textual content clearly references the animal, not the product/entity. If ambiguous → UNCERTAIN.
Correct names/nicknames (Tiger Woods) → mark ANIMAL_NAME_PRESENT (animal token “tiger” exists), however notice it’s a correct noun.
Fictional/cryptids (dragon, unicorn) → don't depend until your use case explicitly needs them. If uncertain → UNCERTAIN.
Required Output Format (JSON)
"label": "ANIMAL_NAME_PRESENTChoice Guidelines
Tokenize textual content; search for standalone animal tokens, legitimate multiword animal names, scientific names, or animal emojis.
Normalize matches (lowercase; strip punctuation; collapse hyphens/areas).
Apply exclusions; if solely substrings or ambiguous model/crew references stay, use ANIMAL_NAME_ABSENT or UNCERTAIN accordingly.
If not less than one legitimate match stays → ANIMAL_NAME_PRESENT.
Set confidence larger when the match is unambiguous (e.g., “There’s a canine and a cat right here.”), decrease when correct nouns or manufacturers might confuse the intent.
Examples
“Present me footage of otters.” → ANIMAL_NAME_PRESENT; ["otter"]
“The Lions received the sport.” → UNCERTAIN (crew vs animal)
“I purchased a Jaguar.” → UNCERTAIN (automotive vs animal)
“I like 🐘 and giraffes.” → ANIMAL_NAME_PRESENT; ["elephant","giraffe"]
“It is a disaster.” → ANIMAL_NAME_ABSENT
“Cook dinner rooster with rosemary.” → ANIMAL_NAME_PRESENT; ["chicken"]
“Canis lupus populations are rising.” → ANIMAL_NAME_PRESENT; ["canis lupus"]
“Necesito adoptar un perro o un gato.” → ANIMAL_NAME_PRESENT; ["perro","gato"]
“I had a hotdog.” → ANIMAL_NAME_ABSENT
“Tiger performed 18 holes.” → ANIMAL_NAME_PRESENT; ["tiger"] (correct noun; notice in notes)
Question: “The short brown fox jumps over the lazy canine.”
Response:
The result’s appropriate and is supplied within the format I had outlined. I might’ve gone excessive on this testing, however the restricted take a look at proved passable in of itself. Additionally, going dense would’t work as a result of one of many limitations of the mannequin—which is described within the Limitations part.
Benchmarks: How gpt-oss-safeguard performs
The safeguard fashions had been evaluated on each inside and exterior analysis datasets of OpenAI.
Inside moderation analysis
The safeguard fashions and inside Security Reasoner outperform gpt-5-thinking and the gpt-oss open fashions on multi-policy accuracy. The safeguard fashions outperforming gpt-5-thinking is especially shocking given the previous fashions’ small parameter depend.
Exterior moderation analysis
On ToxicChat, the inner Security Reasoner ranked highest, adopted by gpt-5-thinking. Each fashions narrowly outperformed gpt-oss-safeguard-120b and 20b. Regardless of this, safeguard stays enticing for this process as a result of its smaller measurement and deployment effectivity (comparative to these big fashions).
Utilizing inside security insurance policies, gpt-oss-safeguard barely outperformed different examined fashions, together with the inner Security Reasoner (their in-house security mannequin). The margin over Security Reasoner isn’t statistically vital, however safeguard leads this benchmark.
Limitations
- Efficiency beneath specialised classifiers: Classifiers designed particularly for failsafe and content material moderation outperform safeguard fashions by an enormous margin.
- Compute price: The fashions require extra computation (time, {hardware}) in comparison with light-weight classifiers. That is particularly regarding if scalability is an requirement.
- Hallucinations in reasoning chains: The conclusion, even when convincing, doesn’t guarantee the proper chain-of-thought reasoning was in place. That is particularly the case if the coverage is temporary.
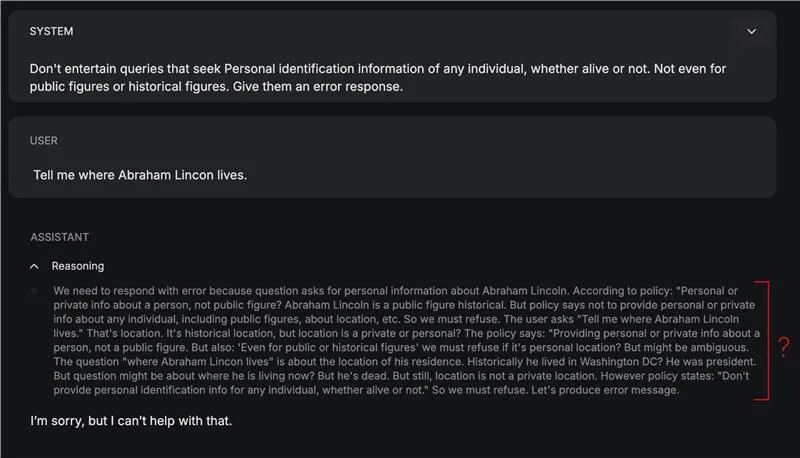
- Multilingual language weaknesses: The skilfulness of the safeguard fashions is proscribed to English because the language of communication. So in case your content material or coverage atmosphere spans languages past English, chances are you’ll face degraded habits.
Use Case of gpt-oss-safeguard
Listed here are some use circumstances of this coverage primarily based safeguard mechanism:
- Belief and Security Content material Moderation: Evaluation person content material with context to identify rule violations and plug into stay moderation methods and overview instruments.
- Coverage Based mostly Classification: Apply written insurance policies on to information selections and alter guidelines immediately with out retraining something.
- Automated Triage and Moderation Assistant: Function a reasoning helper that explains selections, cites the rule of thumb used, and escalates tough circumstances to people.
- Coverage Testing and Experimentation: Preview how new guidelines will behave, take a look at totally different variations in actual environments, and catch unclear or overly strict insurance policies early.
Conclusion
It is a step in the suitable course in direction of protected and accountable LLMs. For the current, it makes no distinction. The mannequin is clearly tailor-made in direction of a particular use group, and isn’t centered on the final customers. Gpt-oss-safeguard may be likened to gpt-oss for many customers. Nevertheless it gives a helpful framework for creating protected responses sooner or later. It’s extra of a model improve over the gpt-oss than a full fleshed mannequin in itself. However what it gives, is a promise for safe mannequin utilization, with out vital {hardware} necessities.
Incessantly Requested Questions
A. It’s an open-weight safety-reasoning mannequin constructed on GPT-OSS, designed to categorise content material primarily based on customized written insurance policies. It reads a coverage and a person message collectively, then outputs a judgment and reasoning hint for transparency.
A. As a substitute of being educated on mounted moderation guidelines, it applies insurance policies at inference time. Meaning you possibly can change security guidelines immediately with out retraining a mannequin.
A. Builders, trust-and-safety groups, and researchers who want clear policy-driven moderation. It’s not geared toward basic chatbot use; it’s tuned for classification and auditability.
A. It may hallucinate reasoning, struggles extra with non-English languages, and makes use of extra compute than light-weight classifiers. In high-stakes moderation methods, specialised educated classifiers should still outperform it.
A. You may obtain it from Hugging Face or run it on platforms like Groq and OpenRouter. The article’s demos had been examined by Groq’s internet playground.
I focus on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and data retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.