

{kind=link}
Amazon SageMaker Unified Studio introduces assist for working interactive Apache Spark classes along with your company identities by way of trusted id propagation. These Spark interactive classes can be found utilizing Amazon EMR, Amazon EMR Serverless, and AWS Glue. Enterprises with their workforce company id supplier (IdP) built-in with AWS IAM Id Heart can now use their IAM Id Heart person and group id seamlessly with SageMaker Unified Studio to entry AWS Glue Knowledge Catalog databases and tables.
Directors of AWS providers can use trusted id propagation in IAM Id Heart to grant permissions primarily based on person attributes, akin to person ID or group associations. With trusted id propagation, id context is added to an IAM function to establish the person requesting entry to AWS assets and is additional propagated to different AWS providers when requests are made. Till now, Spark classes in SageMaker Unified Studio used the venture IAM function for managing knowledge entry permissions for all members of the venture. This offered fine-grained entry management on the venture IAM function stage and never on the person stage. Now, with the trusted id propagation enabled within the SageMaker Unified Studio area, the information entry could be fine-grained on the person or group stage.
The trusted id propagation assist for Spark interactive classes makes the SageMaker Unified Studio a holistic providing for enterprise knowledge customers. Enabling trusted id propagation in SageMaker Unified Studio saves time by avoiding the repeated permission grants to new venture IAM roles and enhances safety auditing with the IAM Id Heart person or group ID within the AWS CloudTrail logs.
The next are a number of the use instances for trusted id propagation in Spark classes for SageMaker Unified Studio:
- Single sign-on expertise with AWS analytics – For purchasers utilizing enterprise knowledge mesh constructed utilizing AWS Lake Formation, single sign-on expertise with trusted id propagation is out there for Spark functions by way of EMR Studio hooked up with Amazon EMR on EC2 and SQL expertise by way of Amazon Athena question editor inside EMR Studio. With the addition of EMR Serverless, Amazon EMR on EC2, and AWS Glue for Spark classes with trusted id propagation enabled in SageMaker Unified Studio, the one sign-on expertise is expanded to supply simpler choices for the information scientists and builders.
- Nice-grained entry management primarily based on person id or group membership– Use a single venture inside the SageMaker Unified Studio area throughout a number of knowledge scientists, with the fine-grained permissions of AWS Lake Formation. When a knowledge scientist accesses the AWS Glue Knowledge Catalog desk, the session is now enabled by their IAM Id Heart person or group permissions. Additional, every can use their most popular instrument, akin to EMR Serverless, AWS Glue, or Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2), for the Spark classes inside SageMaker Unified Studio.
- Remoted person classes – The Spark interactive classes in SageMaker Unified Studio are securely remoted for every IAM Id Heart person. With safe classes, knowledge groups can focus extra on enterprise knowledge exploration and sooner improvement cycles, moderately than constructing guardrails.
- Auditing and reporting – Prospects in regulated industries want strict compliance studies displaying fine-grained particulars of their knowledge entry. CloudTrail logs present the
additionalContextarea with the small print of IAM Id Heart person ID or group ID and the analytics engine that accessed the Knowledge Catalog tables from SageMaker Unified Studio. - Develop and scale with unified governance mannequin – Prospects who’re already utilizing Amazon Redshift, Amazon QuickSight and AWS Lake Formation permissions built-in with IAM Id Heart can now broaden their ML and knowledge analytics platform to incorporate Spark classes with EMR Serverless and AWS Glue choices in SageMaker Unified Studio. They don’t have to take care of IAM role-based coverage permissions. Trusted id propagation for Spark classes in SageMaker Unified Studio scales the present permissions mechanism to a wider group of knowledge scientists and builders.
On this put up, we offer step-by-step directions to arrange Amazon EMR on EC2, EMR Serverless, and AWS Glue inside SageMaker Unified Studio, enabled with trusted id propagation. We use the setup as an example how completely different IAM Id Heart customers can run their Spark classes, utilizing every compute setup, inside the identical venture in SageMaker Unified Studio. We present how every person will see solely tables or a part of tables that they’re granted entry to in Lake Formation.
Answer overview
A monetary providers firm processes knowledge from thousands and thousands of retail banking transactions per day, pooled into their centralized knowledge lake and accessed by conventional company identities. Their machine studying (ML) platform crew wish to allow hundreds of their knowledge scientists, working throughout completely different groups, with the suitable dataset and instruments in a safe, scalable and auditable trend. The platform crew chooses to make use of SageMaker Unified Studio, combine their IdP with IAM Id Heart, and handle entry for his or her knowledge scientists on the information lake tables utilizing fine-grained Lake Formation permissions.
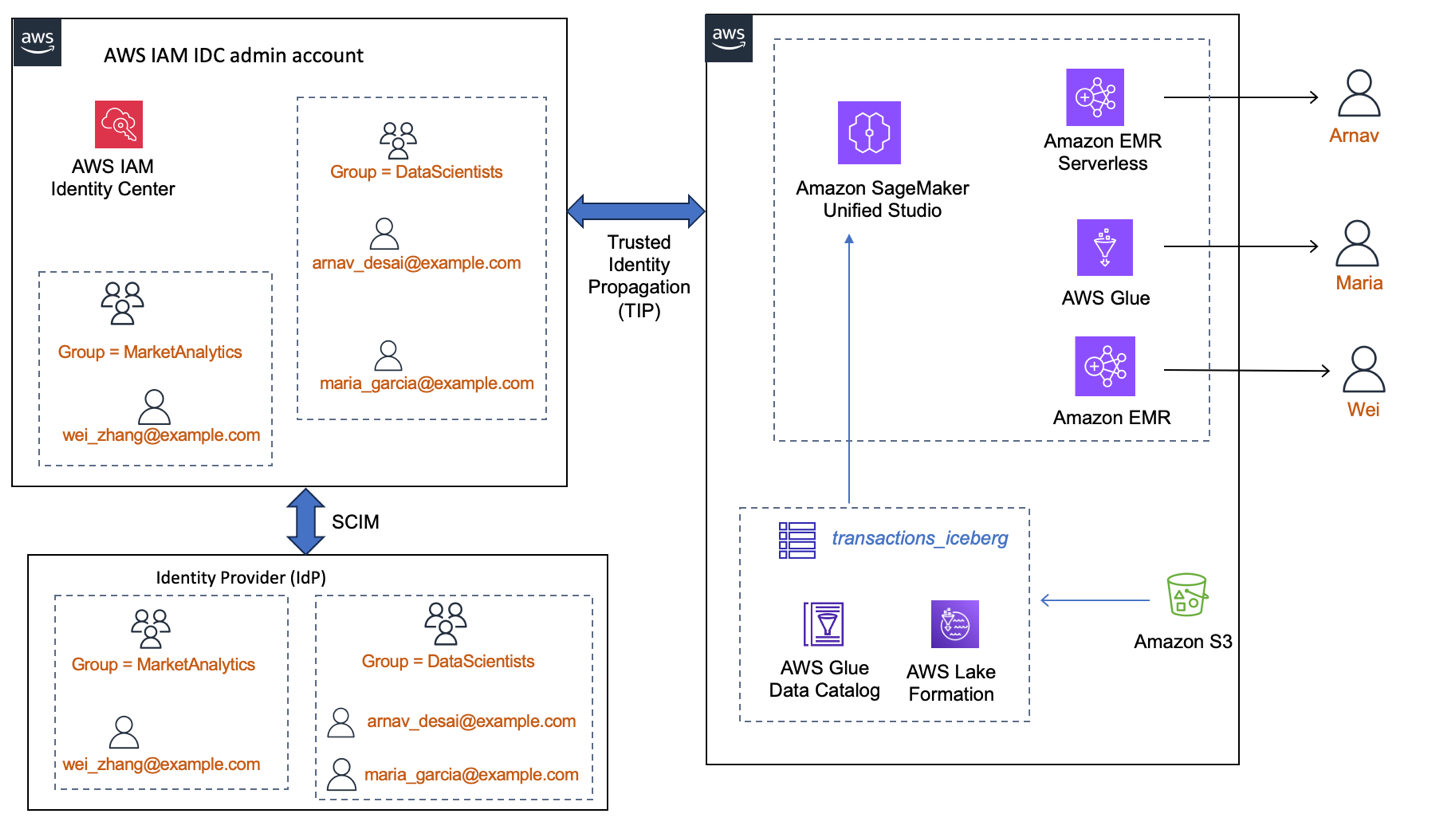
In our pattern implementation, we present how you can allow three completely different knowledge scientists—Arnav, Maria, and Wei—belonging to 2 completely different groups, to entry the identical datasets, however with completely different ranges of entry. We use Lake Formation tags to grant column restricted entry and have the three knowledge scientists run their Spark classes inside the identical SageMaker Unified Studio venture. When the person customers sign up to the SageMaker Unified Studio venture, their IDC person or group id context is added to the SageMaker Unified Studio venture execution function, and their fine-grained permissions from Lake Formation on the catalog tables are efficient. We present how their knowledge exploration is remoted and distinctive.
The next diagram reveals an occasion of how an enterprise workforce IdP, built-in with IAM Id Heart, would make the customers and teams obtainable to be used by AWS providers. Right here, Lake Formation and SageMaker Unified Studio area are built-in with IAM Id Heart and trusted id propagation is enabled. On this setup, (a) knowledge permissions are granted to the IDC person or group identities instantly as a substitute of IAM roles (b) the person id context is out there end-to-end (c) knowledge entry management is centralized in Lake Formation irrespective of which analytics service the person makes use of.
Stipulations
Working with IAM Id Heart and the AWS providers that combine with IAM Id Heart requires a number of steps. On this put up we use one AWS account with IAM Id Heart enabled and a SageMaker Unified Studio area created. We advocate that you just use a check account to observe alongside the weblog.
You want the next conditions:
Create a venture in SageMaker Unified Studio
Now that DataScientists and MarketAnalytics teams are granted entry to the area, IAM Id Heart customers belonging to these two teams can sign up to the SageMaker Unified Studio portal for the subsequent steps. Observe these steps:
- Check in to the SageMaker Unified Studio portal as single sign-on person Arnav.
- Create a venture
blogproject_tip_enabledbeneath the area, as proven within the following screenshot. For particulars, observe the directions in Create a venture. - Choose All capabilities for Undertaking profile, as proven within the following screenshot. Go away the opposite parameters to default values.
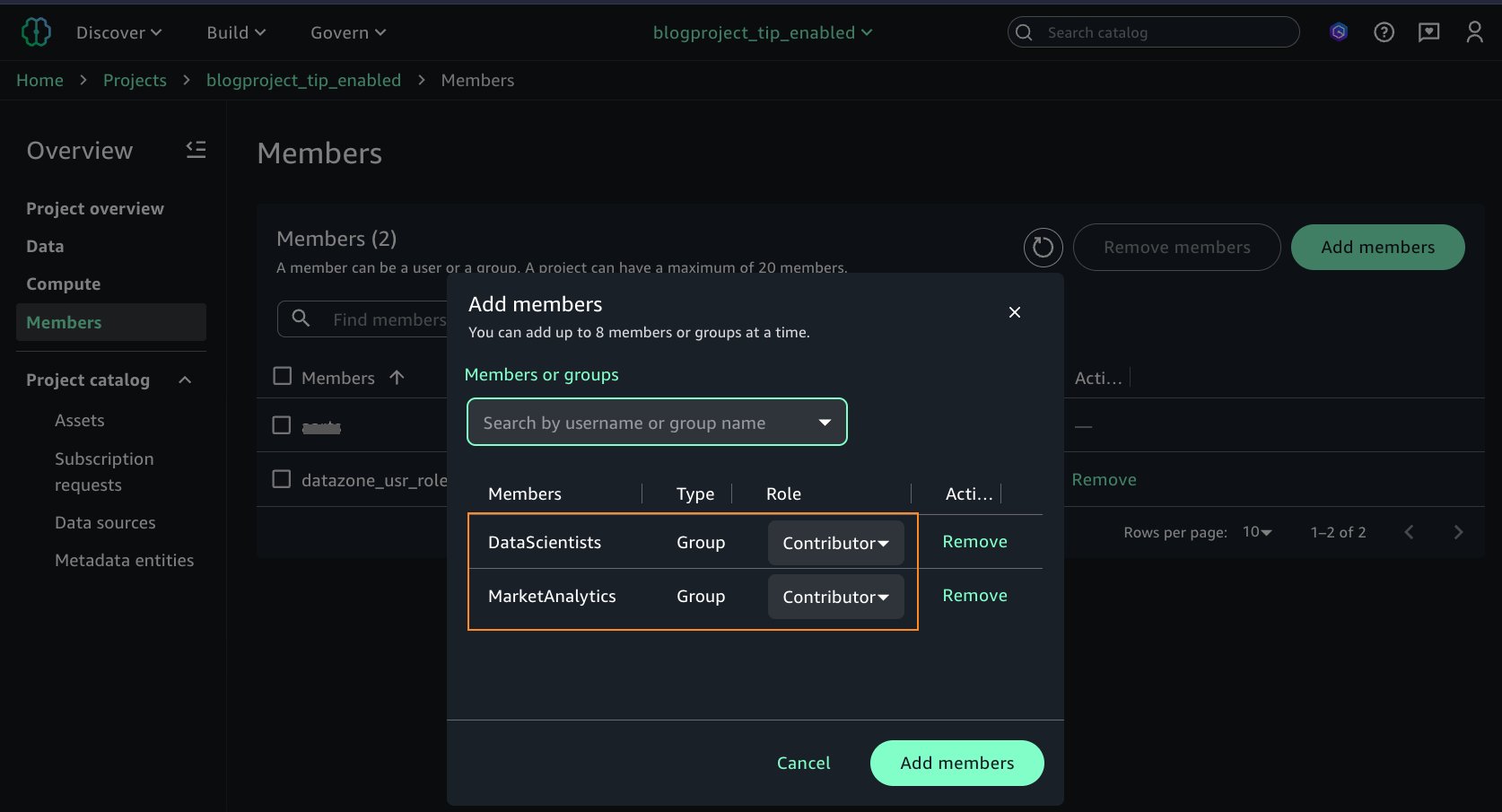
Arnav wish to collaborate with different crew members. After creating the venture, he grants entry on the venture to extra IAM Id Heart teams. He provides the 2 IAM Id Heart teams, DataScientists and MarketAnalytics, as Members of sort Contributor to the venture, as proven within the following screenshot.
To date, you’ve arrange IAM Id Heart, created customers and teams, created a SageMaker Unified Studio area and venture, and added the IAM Id Heart teams as customers to the area and the venture. In the remainder of the sections, we arrange the three sorts of computes for Spark interactive session and enter a question on the Lake Formation managed tables as particular person IAM Id Heart customers Arnav, Maria, and Wei.
Arrange EMR Serverless
On this part, we arrange an EMR Serverless compute and run a Spark interactive session as Arnav.
- Check in to the SageMaker Unified Studio area as the one sign-on person Arnav. Discuss with the area’s element web page to get the URL.
- After signing in as Arnav, choose the venture
blogproject_tip_enabled. From the left navigation pane, select Compute. On the Knowledge processing tab, select Add compute.
- Beneath Add compute, select Create new compute assets, as proven within the following screenshot.
- Select EMR Serverless.
- Beneath Launch label, select minimal model 7.8.0 and select Nice-grained.
- After the EMR Serverless compute is in Created standing, on the Actions dropdown record, select Open JupyterLab IDE. It will open a Jupyter Pocket book session.
- When the Jupyter pocket book opens, you will notice a banner to replace the SageMaker Distribution picture to model 2.9. Observe the directions in Modifying an area and replace the house to make use of model 2.9. Save the house and restart after replace.
- Open the house after it finishes updating. It will open the Jupyter pocket book.
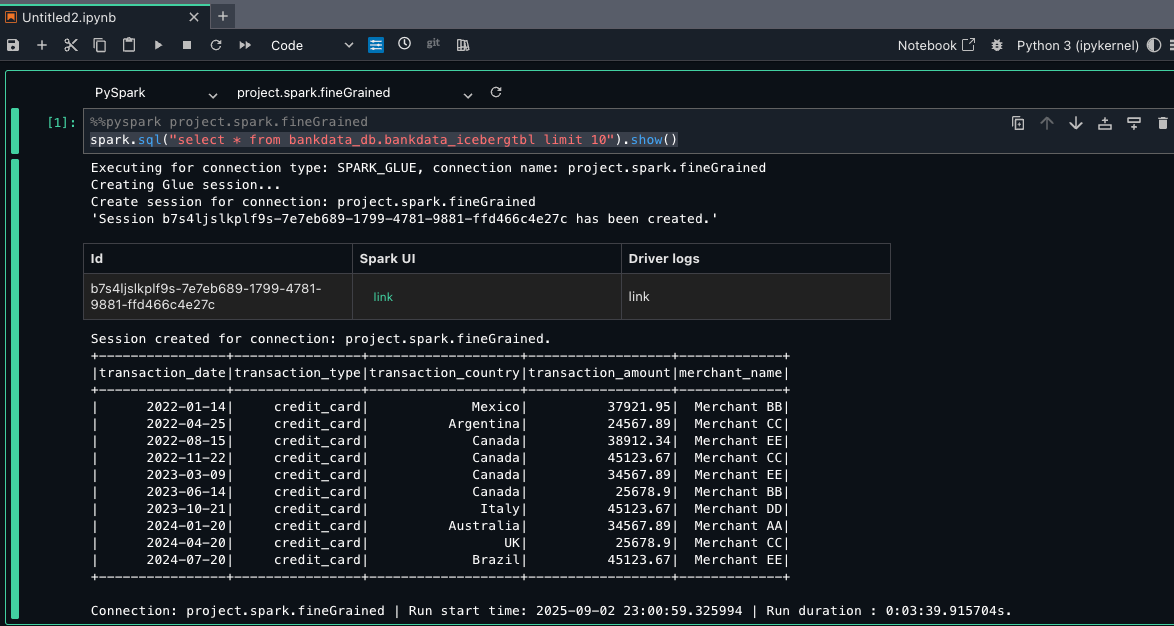
Now, your surroundings is prepared, and you may run Spark queries and check your entry to the deskbankdata_icebergtbl. - On the Launcher window, beneath Pocket book, select Python 3(ipykernel).
- On the highest a part of the pocket book cell, select PySpark from the kernel dropdown record and emr-s.blog_tipspark_emrserverless from the Compute dropdown record.
- Run the next question:
As a result of Arnav is a part of the DataScientists group, he ought to see all columns of the desk, as proven within the following screenshot.
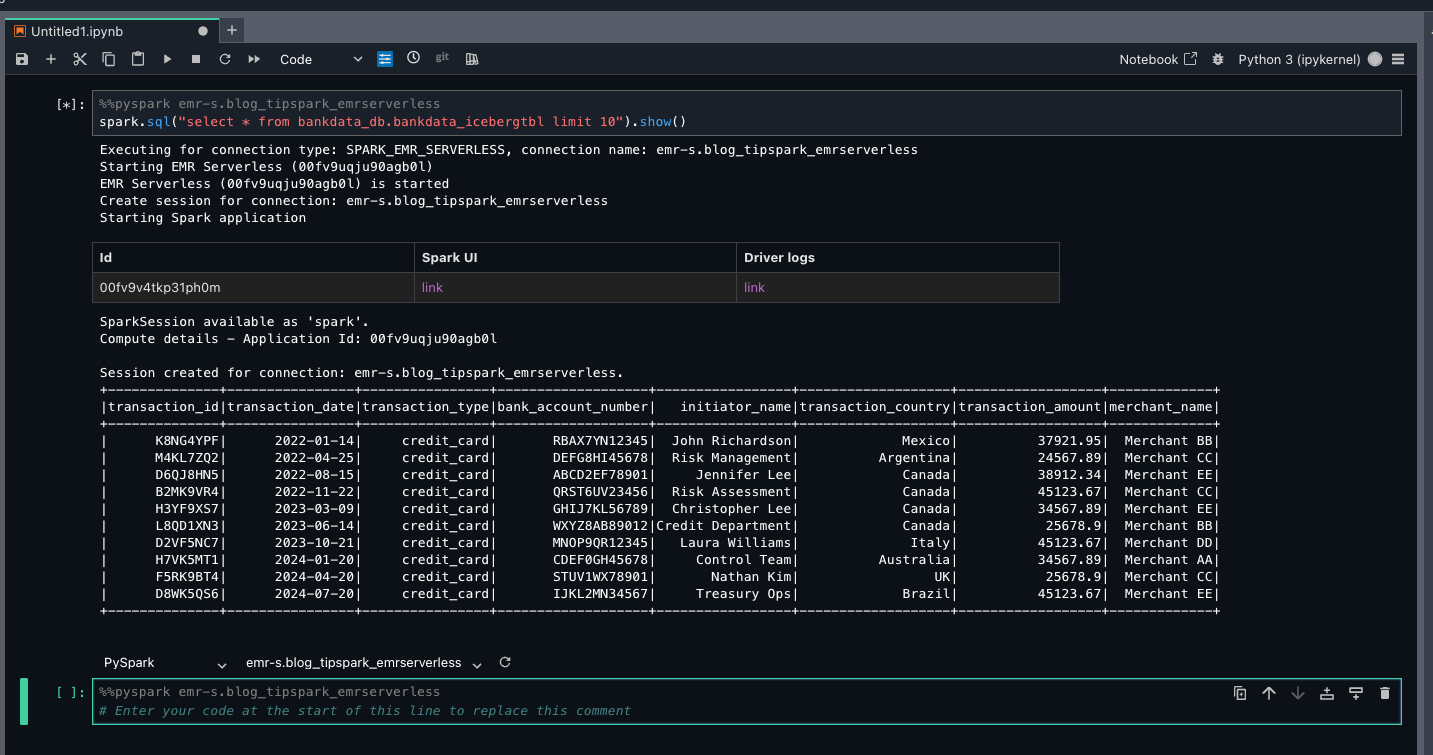
This verifies LF-Tags primarily based entry for Arnav on the bankdata_db.bankdata_icebergtbl utilizing a Spark session in EMR Serverless compute.
Arrange AWS Glue 5.0
On this part, we arrange AWS Glue compute and run a Spark interactive session as Maria.
- Check in to the SageMaker Unified Studio area as the one sign-on person Maria.
- Select the venture
blogproject_tip_enabled. From the left navigation pane, select Compute. On Knowledge processing tab, you need to see two computes created by default in Lively standing (venture.spark.compatibility and venture.spark.fineGrained) with Sort Glue ETL. For added particulars on these compute sorts, seek advice from AWS Glue ETL in Amazon SageMaker Unified Studio. - Choose the venture.spark.fineGrained and launch the Jupyter pocket book with the PySpark kernel.
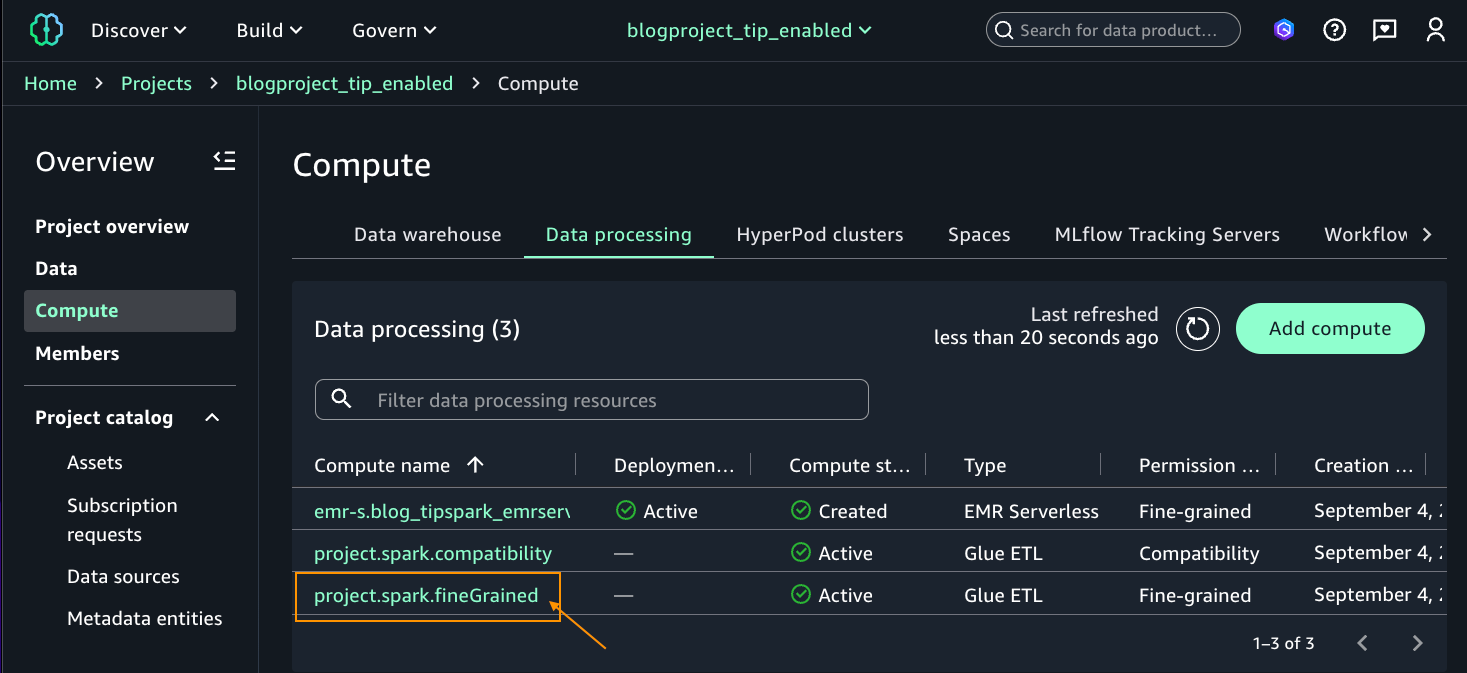
- For the pocket book cell, select pySpark for kernel and venture.spark.fineGrained for compute. Enter the next question:
As a result of Maria is a part of the DataScientists group, she ought to see all columns of the desk, as proven within the following screenshot.
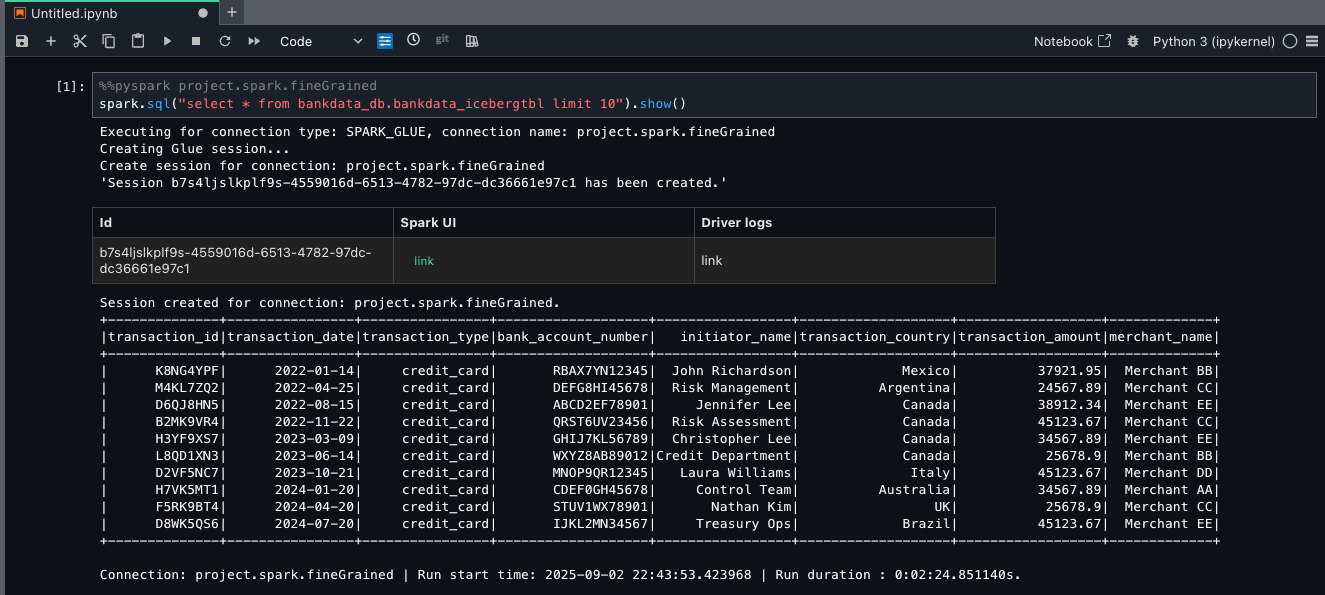
This verifies LF-Tags primarily based entry to Maria on the bankdata_db.bankdata_icebergtbl utilizing Spark session in AWS Glue fine-grained entry management (FGAC) compute.
To confirm what entry Wei has utilizing EMR Serverless and AWS Glue, you’ll be able to signal out and sign up as person Wei. Enter the Spark SELECT queries on the identical desk. Wei shouldn’t see the three personally identifiable info (PII) columns transaction_id, bank_account_number, and initiator_name, which have been tagged as transactions=secured.
The next screenshot reveals the identical desk for Wei utilizing EMR Serverless.
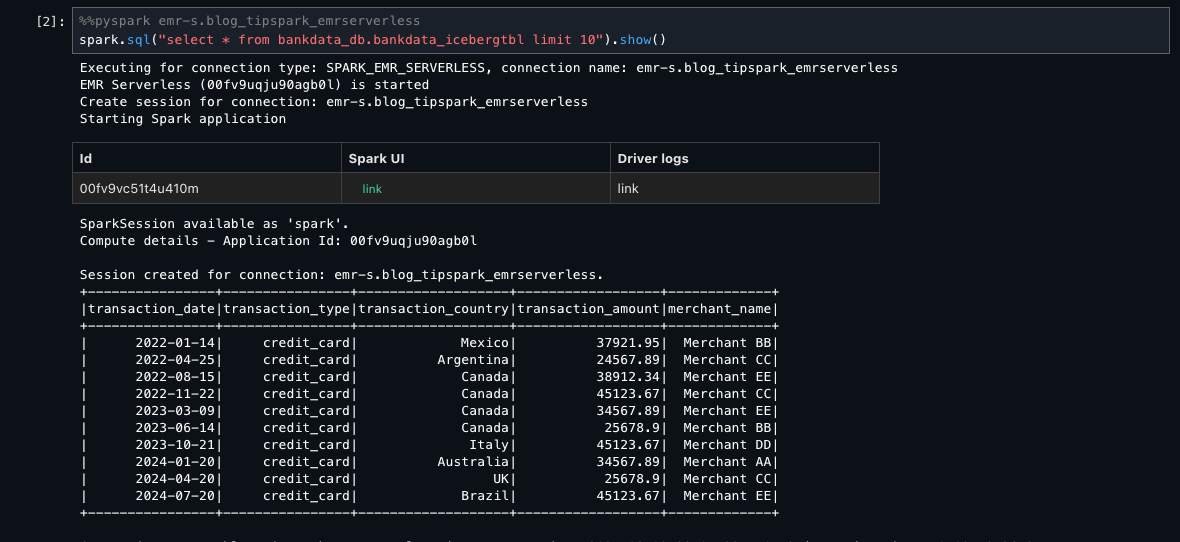
The next screenshot reveals the identical desk for Wei utilizing AWS Glue FGAC mode.
Arrange Amazon EMR on EC2
On this part, we arrange an Amazon EMR on EC2 compute and run a Spark interactive session as Wei.
- Check in to the SageMaker Unified Studio area as the one sign-on person Wei.
- Create Amazon EMR on EC2 compute utilizing the steps for EMR Serverless in Setup EMR serverless however select EMR on EC2 cluster as a substitute of EMR Serverless. For the EMR configuration, select the MemoryOptimized or GeneralPurpose configuration, relying on which one you selected to add your PEM certificates to within the venture profiles blueprint within the Stipulations part. Select an Amazon EMR launch label higher than or equal to 7.8.0.
- After the cluster is provisioned, find the occasion profile function title within the compute particulars web page, as proven within the following screenshot.
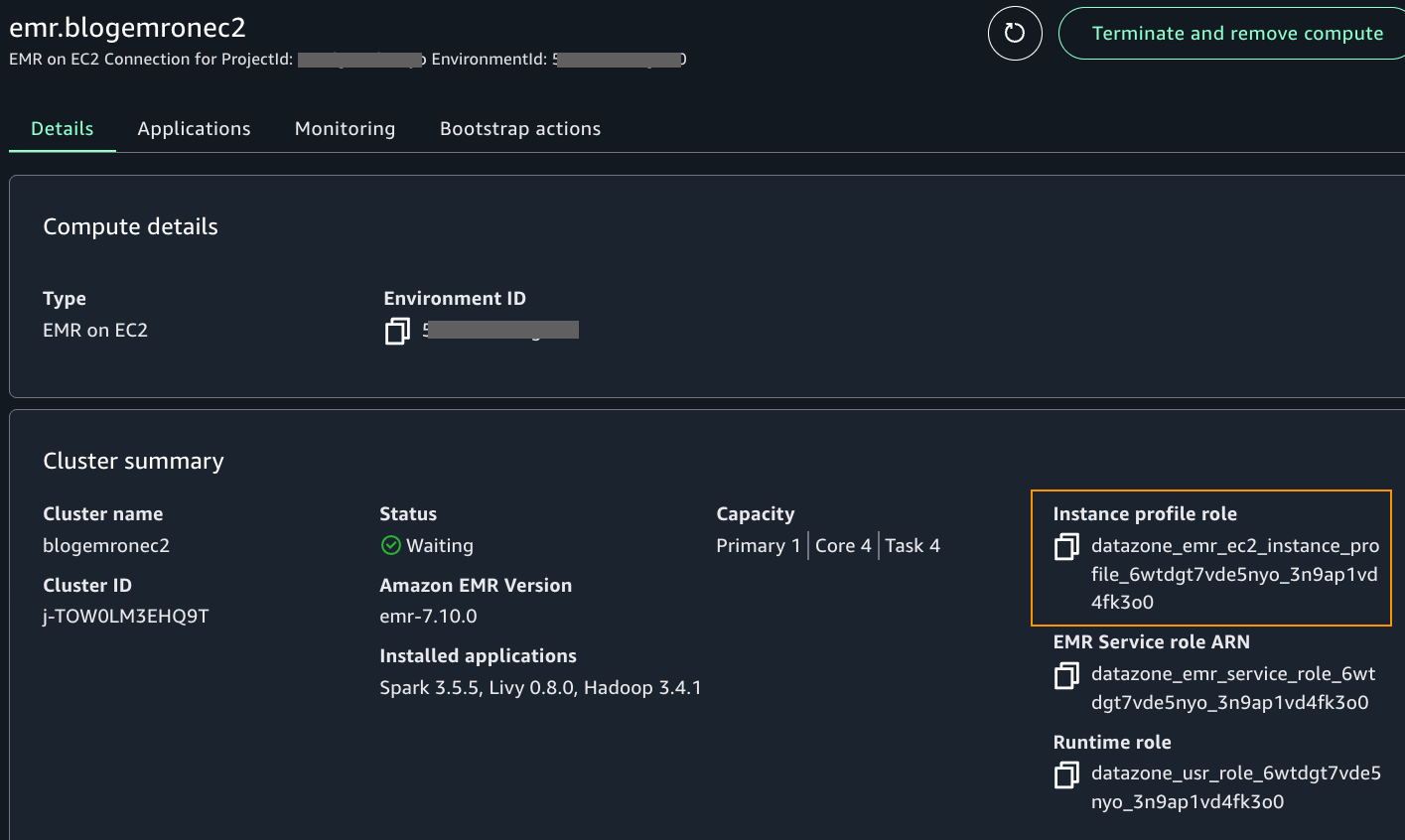
- As an admin person who can edit IAM insurance policies in your account, add the next inline coverage to the occasion profile function. A handbook intervention exterior SageMaker Unified Studio is required at the moment to carry out this step. This will likely be addressed sooner or later.
- After updating the function’s coverage, you need to use the Amazon EMR on EC2 connection to provoke an interactive Spark session. Much like the way you launched a pocket book as Arnav and Maria, do the identical steps to launch the pocket book as person Wei.
- On the Construct tab, select JupyterNotebook from the venture dwelling web page. Select Python3(ipykernel) to launch the pocket book. Select Configure house to replace to model 2.9. Refresh the pocket book browser.
- Contained in the pocket book, on high of the cell, select PySpark for kernel and emr.blog_tip_emronec2 that you just launched for the compute.
- Enter a choose question on the desk as follows:
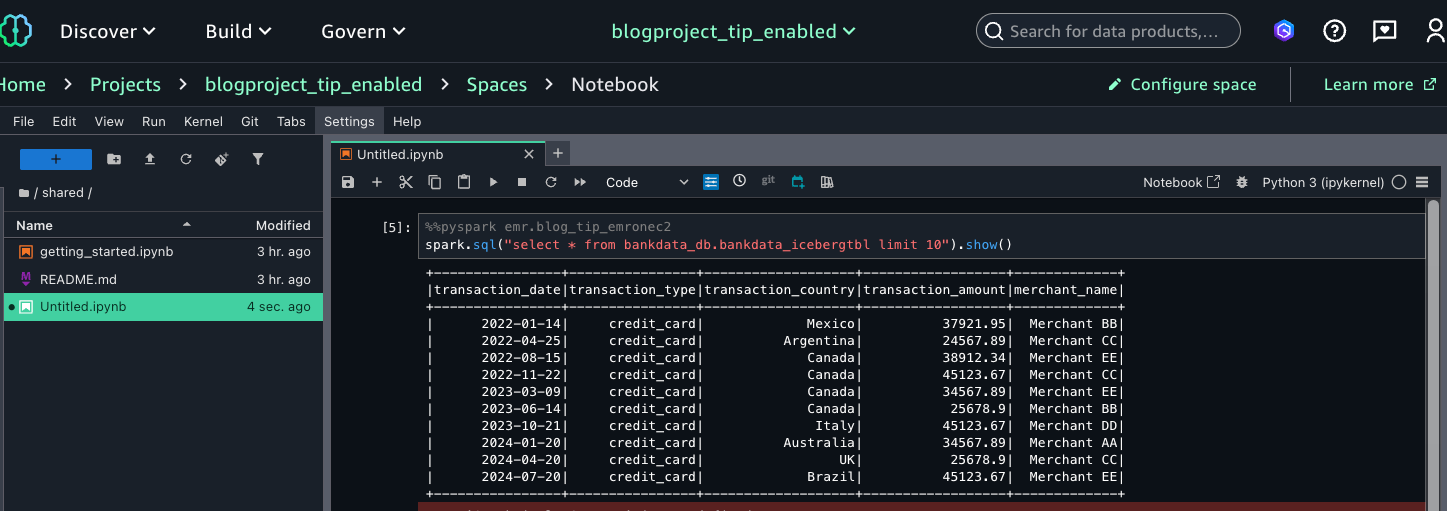
This verifies that Wei, as a part of the MarketAnalytics group, sees all columns of the desk with LF-Tags transactions=accessible however doesn’t have entry to the three columns that have been overwritten with LF-Tags transactions=secured (transaction_id, bank_account_number, and initiator_name).
You’ll be able to hint the person entry of the desk within the CloudTrail logs for EventName=GetDataAccess. Within the related CloudTrail log proven under, we discover that the UserID for Wei is offered beneath additionalEventData area, whereas requestParameters has the tableARN.
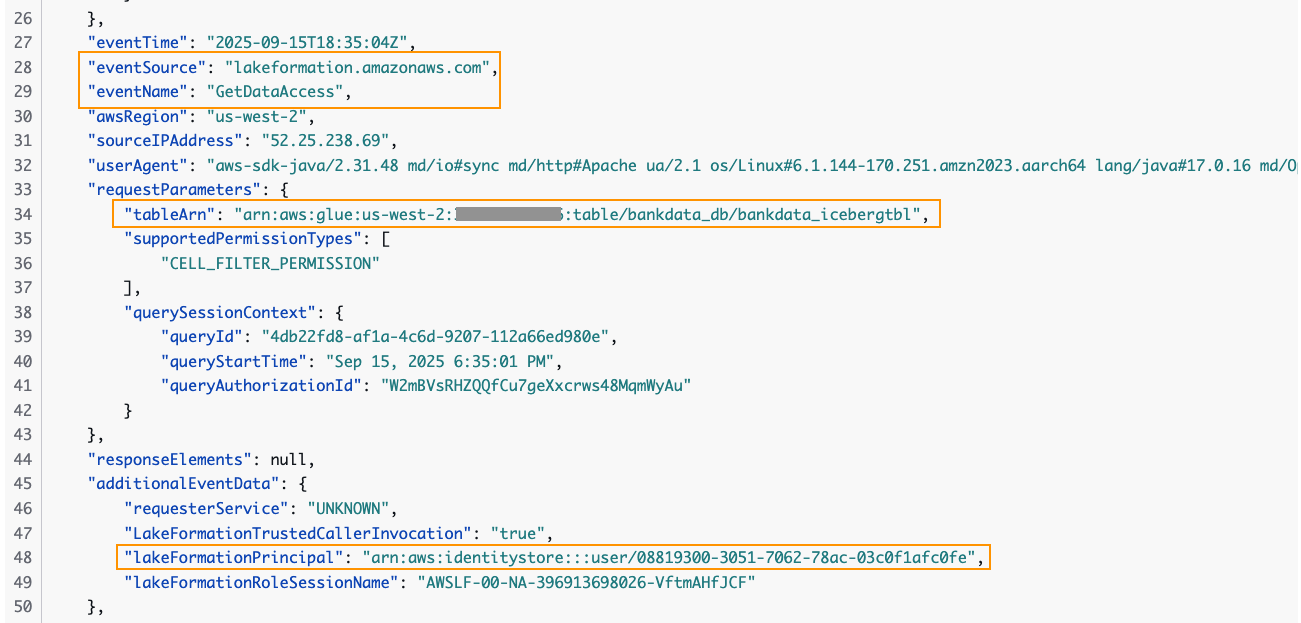
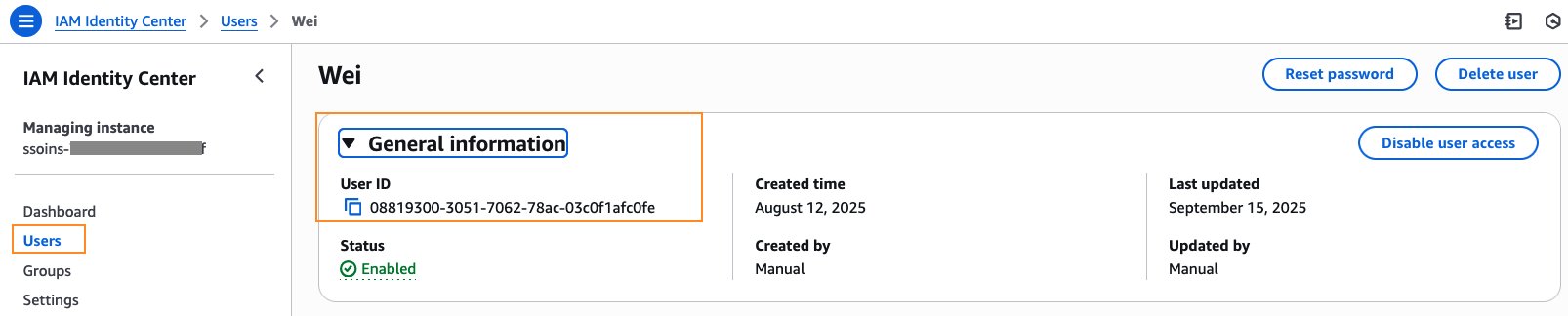
The person ID for Wei is out there within the IAM Id Heart console beneath Common info.
Thus, we have been in a position to sign up as a person IAM Id Heart person to the SageMaker Unified Studio area and question the Knowledge Catalog tables utilizing Amazon EMR and AWS Glue compute. These IAM Id Heart customers have been in a position to question the tables that they have been granted entry to, as a substitute of the SageMaker Unified Studio venture’s IAM function.
Cleanup
To keep away from incurring prices, it’s necessary to delete the assets launched for this walkthrough. Clear up the assets as follows:
- SageMaker Unified Studio by default shuts down idle assets akin to JupyterLab after 1 hour. In case you’ve created a SageMaker Unified Studio area for this put up, keep in mind to delete the area.
- In case you’ve created IAM Id Heart customers and teams, delete the customers and delete the teams. Additional, should you’ve created an IAM Id Heart occasion just for this put up, delete your IAM Id Heart occasion.
- Delete the database
bankdata_dbfrom Lake Formation. This may even delete the tables and all related permissions. Delete the LF-Tagtransactionsand its values. - Delete the desk’s corresponding knowledge out of your S3 bucket two subfolders
bankdata-csvandbankdata-iceberg.
Conclusion
On this put up, we walked by way of how you can allow a SageMaker Unified Studio area with IAM Id Heart trusted id propagation and question Lake Formation managed tables in Knowledge Catalog utilizing Apache Spark interactive classes with EMR Serverless, AWS Glue, and Amazon EMR on EC2. We additionally verified in CloudTrail logs the IAM Id Heart person ID accessing the desk.
Amazon SageMaker Unified Studio with trusted id propagation offers the next advantages.
Enterprise advantages
- Enhanced knowledge safety
- Improved workforce knowledge entry and insights
Technical capabilities
- Permits knowledge entry primarily based on workforce id
- Gives unified governance by way of Lake Formation for Knowledge Catalog tables when accessed by way of SMUS
- Ensures remoted and safe classes for every IAM Id Heart person
- Helps a number of analytics choices:
- Spark classes by way of EMR Serverless, EMR on EC2, and AWS Glue
- SQL analytics by way of Athena and Redshift Spectrum
Organizational benefits
- Direct use of company identities for enterprise knowledge entry
- Simplified entry to knowledge platforms and meshes constructed on Knowledge Catalog and Lake Formation
- Permits varied person roles to work with their most popular AWS analytics providers
- Reduces knowledge exploration time for Spark-familiar knowledge scientists
To study extra, seek advice from the next assets:
We encourage you to take a look at the brand new trusted id propagation enabled SageMaker Unified Studio for Spark classes. Attain out to us by way of your AWS account groups or utilizing the feedback part.
Acknowledgment: A particular because of everybody who contributed to the event and launch of this characteristic: Palani Nagarajan, Karthik Seshadri, Vikrant Kumar, Yijie Yan, Radhika Ravirala and Jerica Nicholls.
APPENDIX A – Desk creation in Knowledge Catalog
- We’ve created an artificial financial institution transactions dataset with 100 rows in CSV format. Obtain the dataset dummy_bank_transaction_data.csv
- In your S3 bucket, create two subfolders:
bankdata-csvandbankdata-icebergand add the dataset tobankdata-csv. - Open the Athena console, navigate to question editor, and enter the next statements in sequence:
- Enter a preview and confirm the desk knowledge:
APPENDIX B – Creating LF-Tags, attaching tags to the desk from Appendix A, and granting permissions to IAM Id Heart customers.
We create a Lake Formation tag with Keyname = transactions and Values = secured, accessible. We affiliate the tag to the desk and overwrite a number of columns as summarized within the desk.
|
Useful resource |
LF-Tag affiliation |
|
|
Database |
bankdata_db |
transactions = accessible |
|
Desk |
bankdata_icebergtbl |
transactions = accessible |
| Columns | transaction_id | transactions = secured |
| bank_account_number | transactions = secured | |
| initiator_name | transactions = secured |
We then grant Lake Formation permissions to the 2 IAM Id Heart teams utilizing these LF-Tags as follows:
|
IAM Id Heart group |
LF-Tags |
Permission |
|
DataScientists |
transactions = accessible AND transactions = secured |
Database DESCRIBE, Desk SELECT |
|
MarketAnalytics |
transactions = accessible |
Database DESCRIBE, Desk SELECT |
- Check in to the Lake Formation console and navigate to LF-Tags and permissions. Create an LF-Tag with Keyname =
transactionsand Values =secured,accessible. - Choose the database
bankdata_dband affiliate the LF-Tagtransactions=accessible. - Choose
bankdata_icebergtbland confirm that the LF-Tagtransactions=accessibleis inherited by the desk. - Edit the schema of the desk and alter the LF-Tag worth on the columns
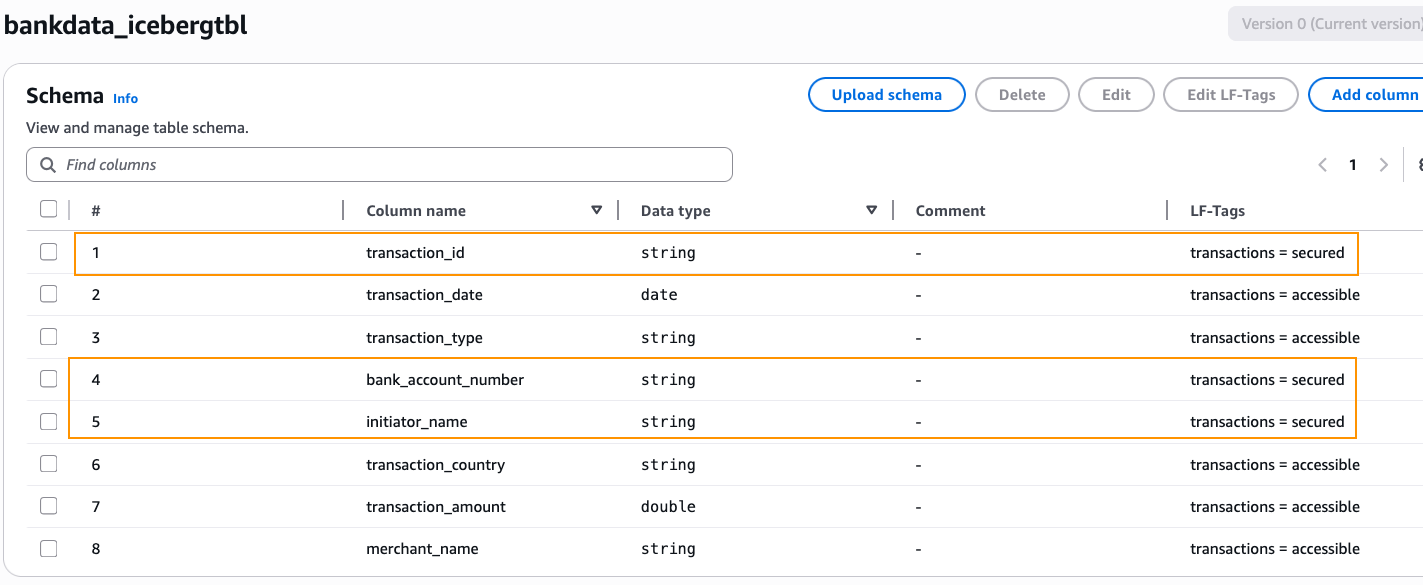
transaction_id,bank_account_number, andinitiator_nametotransactions=secured. After altering, select Save as new model.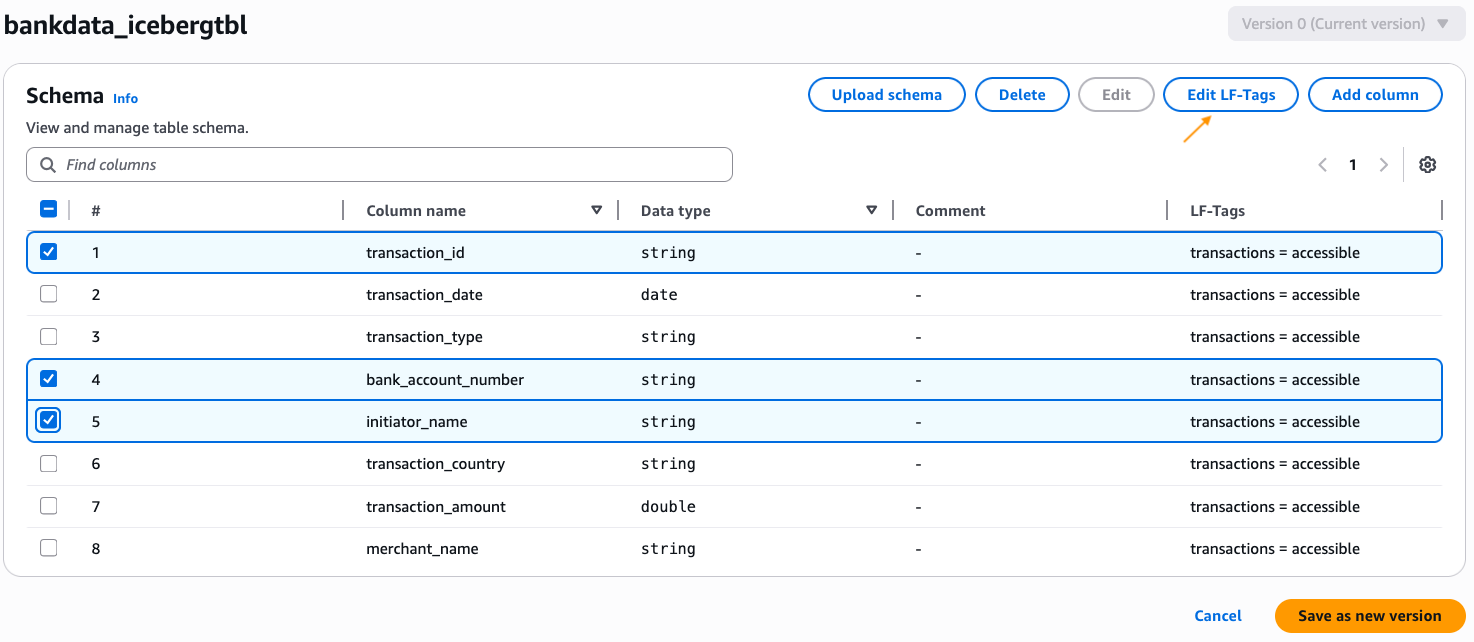
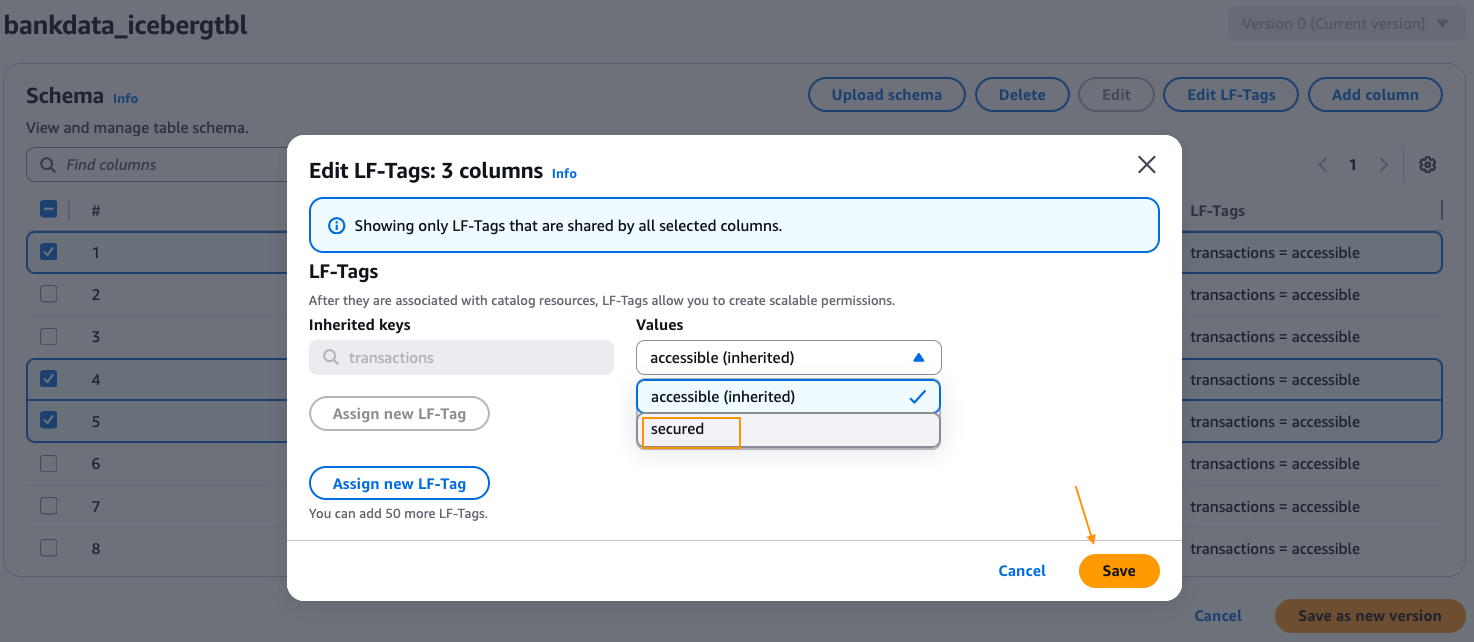
- Navigate to the Knowledge permissions web page on the Lake Formation console. Select Grant to grant permissions.
- Choose the IAM Id Heart group
DataScientistsfor Principals. Choose LF-Tagstransactionsand each the valuesaccessible,secured. Select Database DESCRIBE and Tables SELECT permissions. Select Grant.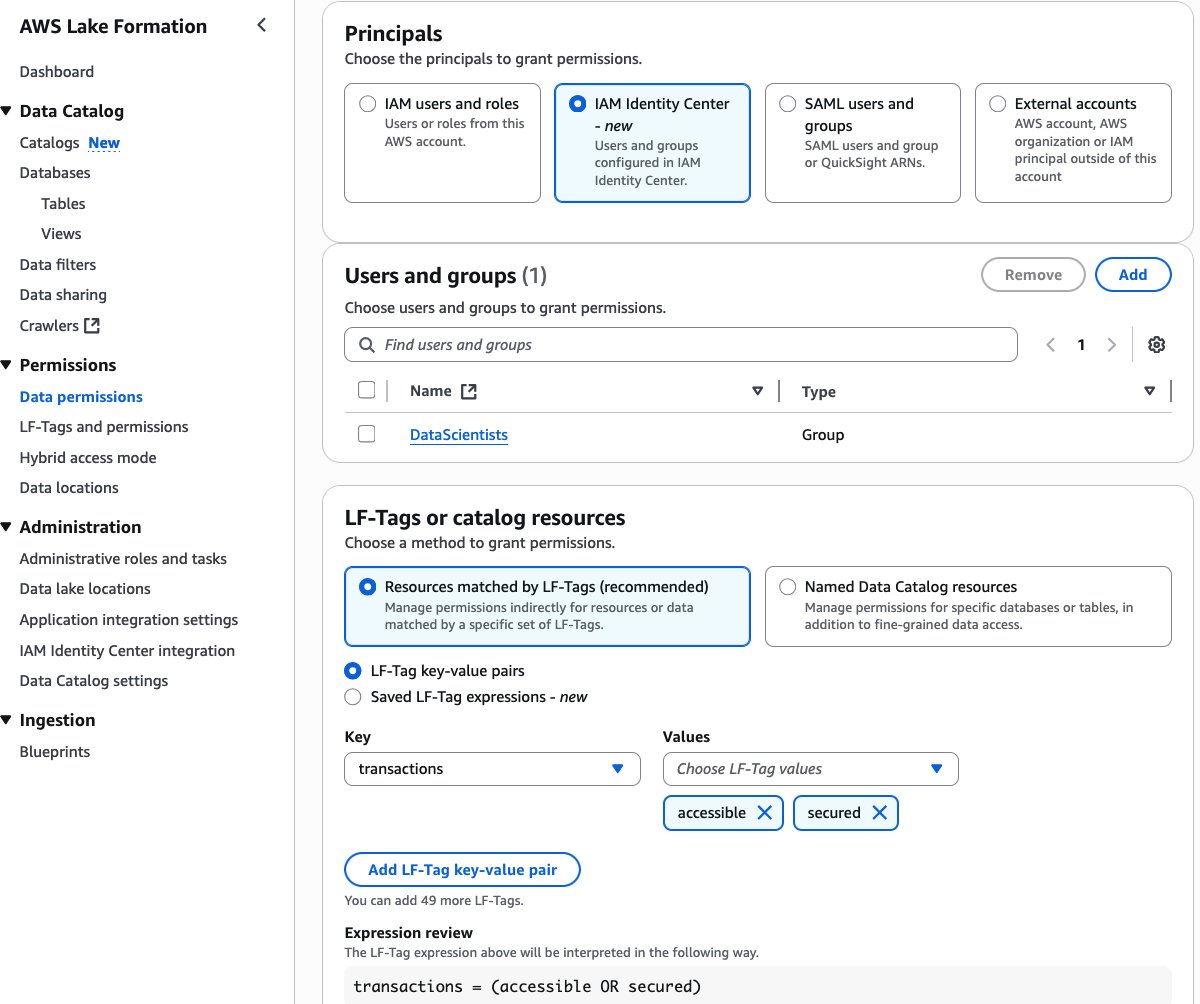
- On the Knowledge permissions web page on the Lake Formation console, select Grant once more.
- Choose the IAM Id Heart group
MarketAnalyticsfor Principals. Choose LF-Tagstransactionsand solely one of many values,accessible. Choose Database DESCRIBE and Tables SELECT permissions. Select Grant.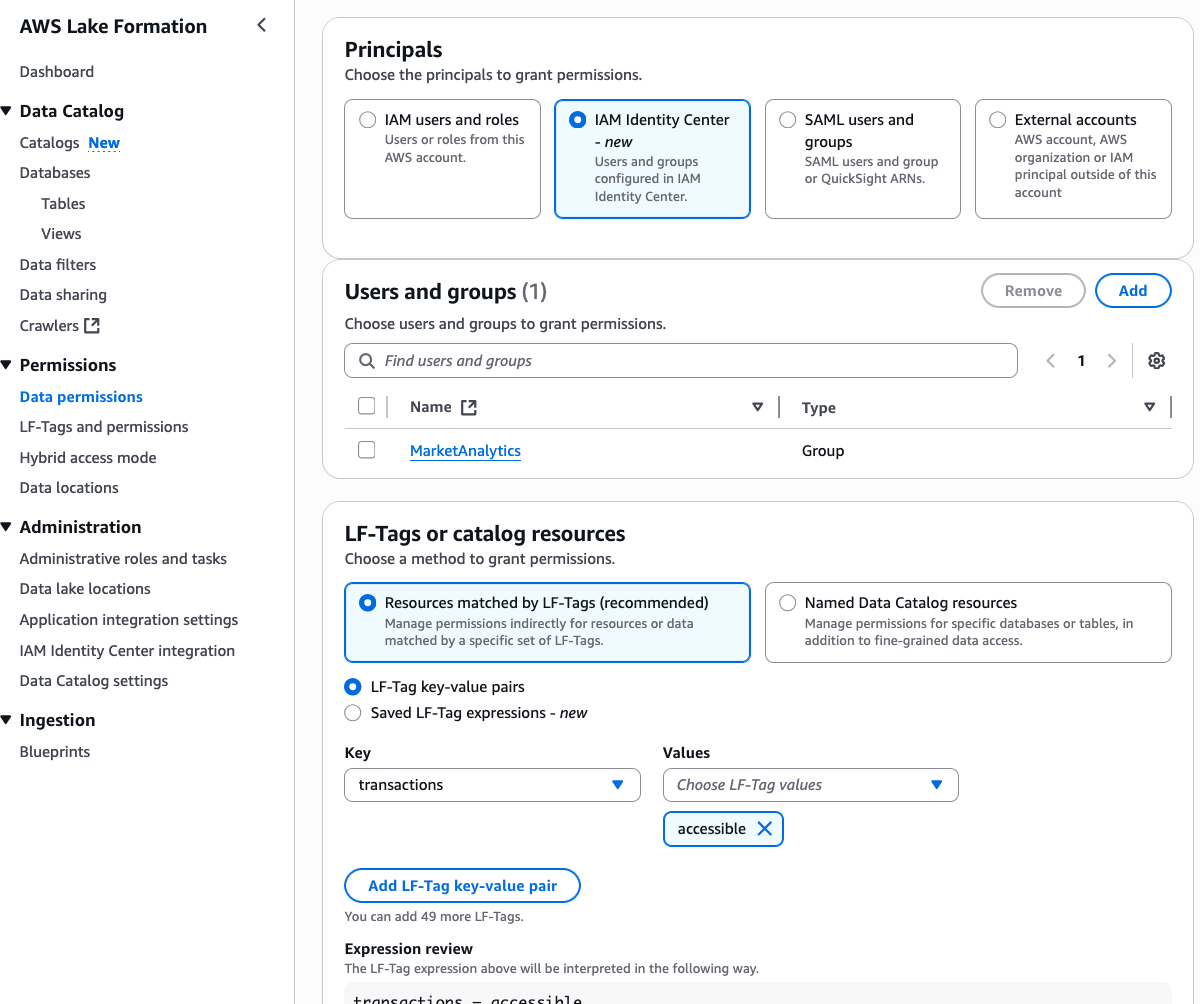
- Additionally grant DESCRIBE permission on the
defaultdatabase to each the IDC teams. - Confirm the granted permissions within the Knowledge permissions web page, by filtering with expression Principal sort = IAM Id Heart group.
Thus, we’ve granted all column entry on the desk bankdata_icebergtbl to the DataScientists group whereas securing three PII columns from the MarketAnalytics group.
Concerning the Authors