

{kind=link}
In case you lead an enterprise knowledge science workforce or a quantitative analysis unit right this moment, you probably really feel like you’re dwelling in two parallel universes.
In a single universe, you’ve gotten the “GenAI” explosion. Chatbots now write code and create artwork, and boardrooms are obsessive about how giant language fashions (LLMs) will change the world. Within the different universe, you’ve gotten your day job: the “critical” work of predicting churn, forecasting demand, and detecting fraud utilizing structured, tabular knowledge.
For years, these two universes have felt utterly separate. You may even really feel that the GenAI hype rocketship has left your core enterprise knowledge standing on the platform.
However that separation is an phantasm, and it’s disappearing quick.
From chatbots to forecasts: GenAI arrives at tabular and time-series modeling
Whether or not you’re a skeptic or a real believer, you’ve gotten most actually interacted with a transformer mannequin to draft an e-mail or a diffusion mannequin to generate a picture. However whereas the world was centered on textual content and pixels, the identical underlying architectures have been quietly studying a unique language: the language of numbers, time, and tabular patterns.
Take as an illustration SAP-RPT-1 and LaTable. The primary makes use of a transformer structure, and the second is a diffusion mannequin; each are used for tabular knowledge prediction.
We’re witnessing the emergence of information science basis fashions.
These aren’t simply incremental enhancements to the predictive fashions you recognize. They signify a paradigm shift. Simply as LLMs can “zero-shot” a translation job they weren’t explicitly educated for, these new fashions can have a look at a sequence of information, for instance, gross sales figures or server logs, and generate forecasts with out the standard, labor-intensive coaching pipeline.
The tempo of innovation right here is staggering. By our depend, for the reason that starting of 2025 alone, we’ve got seen a minimum of 14 main releases of basis fashions particularly designed for tabular and time-series knowledge. This contains spectacular work from the groups behind Chronos-2, TiRex, Moirai-2, TabPFN-2.5, and TempoPFN (utilizing SDEs for knowledge technology), to call just some frontier fashions.
Fashions have develop into model-producing factories
Historically, machine studying fashions had been handled as static artifacts: educated as soon as on historic knowledge after which deployed to provide predictions.

That framing not holds. More and more, trendy fashions behave much less like predictors and extra like model-generating programs, able to producing new, situation-specific representations on demand.
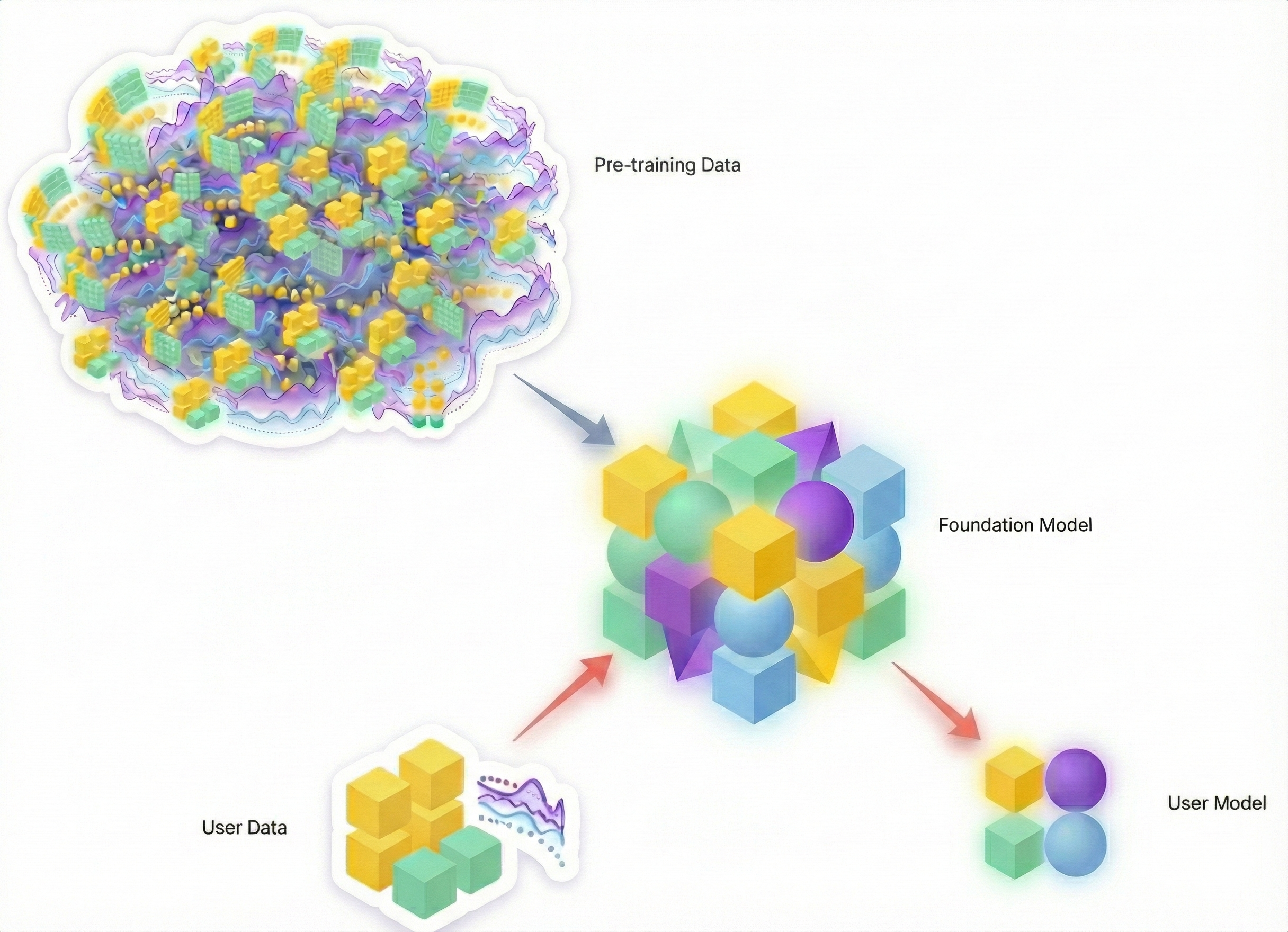
We’re transferring towards a future the place you received’t simply ask a mannequin for a single level prediction; you’ll ask a basis mannequin to generate a bespoke statistical illustration—successfully a mini-model—tailor-made to the particular scenario at hand.
The revolution isn’t coming; it’s already brewing within the analysis labs. The query now could be: why isn’t it in your manufacturing pipeline but?
The truth test: hallucinations and development strains
In case you’ve scrolled by way of the infinite examples of grotesque LLM hallucinations on-line, together with legal professionals citing faux instances and chatbots inventing historic occasions, the considered that chaotic power infiltrating your pristine company forecasts is sufficient to maintain you awake at night time.
Your issues are fully justified.
Classical machine studying is the conservative selection for now
Whereas the brand new wave of information science basis fashions (our collective time period for tabular and time-series basis fashions) is promising, it’s nonetheless very a lot within the early days.
Sure, mannequin suppliers can at present declare prime positions on tutorial benchmarks: all top-performing fashions on the time-series forecasting leaderboard GIFT-Eval and the tabular knowledge leaderboard TabArena are actually basis fashions or agentic wrappers of basis fashions. However in observe? The truth is that a few of these “top-notch” fashions at present wrestle to establish even probably the most fundamental development strains in uncooked knowledge.
They will deal with complexity, however generally journey over the fundamentals {that a} easy regression would nail it–try the sincere ablation research within the TabPFN v2 paper, as an illustration.
Why we stay assured: the case for basis fashions
Whereas these fashions nonetheless face early limitations, there are compelling causes to consider of their long-term potential. We’ve got already mentioned their skill to react immediately to consumer enter, a core requirement for any system working within the age of agentic AI. Extra basically, they will draw on a virtually limitless reservoir of prior info.
Give it some thought: who has a greater probability at fixing a posh prediction drawback?
- Choice A: A classical mannequin that is aware of your knowledge, however solely your knowledge. It begins from zero each time, blind to the remainder of the world.
- Choice B: A basis mannequin that has been educated on a mind-boggling variety of related issues throughout industries, a long time, and modalities—typically augmented by huge quantities of artificial knowledge—and is then uncovered to your particular scenario.
Classical machine studying fashions (like XGBoost or ARIMA) don’t undergo from the “hallucinations” of early-stage GenAI, however in addition they don’t include a “serving to prior.” They can not switch knowledge from one area to a different.
The wager we’re making, and the wager the business is transferring towards, is that finally, the mannequin with the “world’s expertise” (the prior) will outperform the mannequin that’s studying in isolation.
The lacking hyperlink: fixing for actuality, not leaderboards
Information science basis fashions have a shot at turning into the following large shift in AI. However for that to occur, we have to transfer the goalposts. Proper now, what researchers are constructing and what companies really need stays disconnected.
Main tech corporations and tutorial labs are at present locked in an arms race for numerical precision, laser-focused on topping prediction leaderboards simply in time for the following main AI convention. In the meantime, they’re paying comparatively little consideration to fixing advanced, real-world issues, which, sarcastically, pose the hardest scientific challenges.
The blind spot: interconnected complexity
Right here is the crux of the issue: none of the present top-tier basis fashions are designed to foretell the joint chance distributions of a number of dependent targets.
That sounds technical, however the enterprise implication is very large. In the true world, variables hardly ever transfer in isolation.
- Metropolis Planning: You can not predict site visitors movement on Primary Road with out understanding the way it impacts (and is impacted by) the movement on fifth Avenue.
- Provide Chain: Demand for Product A typically cannibalizes demand for Product B.
- Finance: Take portfolio threat. To grasp true market publicity, a portfolio supervisor doesn’t merely calculate the worst-case state of affairs for each instrument in isolation. As a substitute, they run joint simulations. You can not simply sum up particular person dangers; you want a mannequin that understands how property transfer collectively.
The world is a messy, tangled internet of dependencies. Present basis fashions are inclined to deal with it like a collection of remoted textbook issues. Till these fashions can grasp that complexity, outputting a mannequin that captures how variables dance collectively, they received’t substitute present options.
So, for the second, your handbook workflows are secure. However mistaking this short-term hole for a everlasting security internet could possibly be a grave mistake.
Right this moment’s deep studying limits are tomorrow’s solved engineering issues
The lacking items, equivalent to modeling advanced joint distributions, aren’t inconceivable legal guidelines of physics; they’re merely the following engineering hurdles on the roadmap.
If the pace of 2025 has taught us something, it’s that “inconceivable” engineering hurdles have a behavior of vanishing in a single day. The second these particular points are addressed, the aptitude curve received’t simply inch upward. It should spike.
Conclusion: the tipping level is nearer than it seems
Regardless of the present gaps, the trajectory is obvious and the clock is ticking. The wall between “predictive” and “generative” AI is actively crumbling.
We’re quickly transferring towards a future the place we don’t simply practice fashions on historic knowledge; we seek the advice of basis fashions that possess the “priors” of a thousand industries. We’re heading towards a unified knowledge science panorama the place the output isn’t only a quantity, however a bespoke, refined mannequin generated on the fly.
The revolution is just not ready for perfection. It’s iterating towards it at breakneck pace. The leaders who acknowledge this shift and start treating GenAI as a critical instrument for structured knowledge earlier than an ideal mannequin reaches the market would be the ones who outline the following decade of information science. The remainder shall be taking part in catch-up in a sport that has already modified.
We’re actively researching these frontiers at DataRobot to bridge the hole between generative capabilities and predictive precision. That is simply the beginning of the dialog. Keep tuned—we stay up for sharing our insights and progress with you quickly.
Within the meantime, you possibly can study extra about DataRobot and discover the platform with a free trial.