

{kind=link}
In clever programs, purposes vary from autonomous robotics to predictive upkeep issues. To manage these programs, the important elements are captured with a mannequin. Once we design controllers for these fashions, we virtually at all times face the identical problem: uncertainty. We’re not often in a position to see the entire image. Sensors are noisy, fashions of the system are imperfect; the world by no means behaves precisely as anticipated.
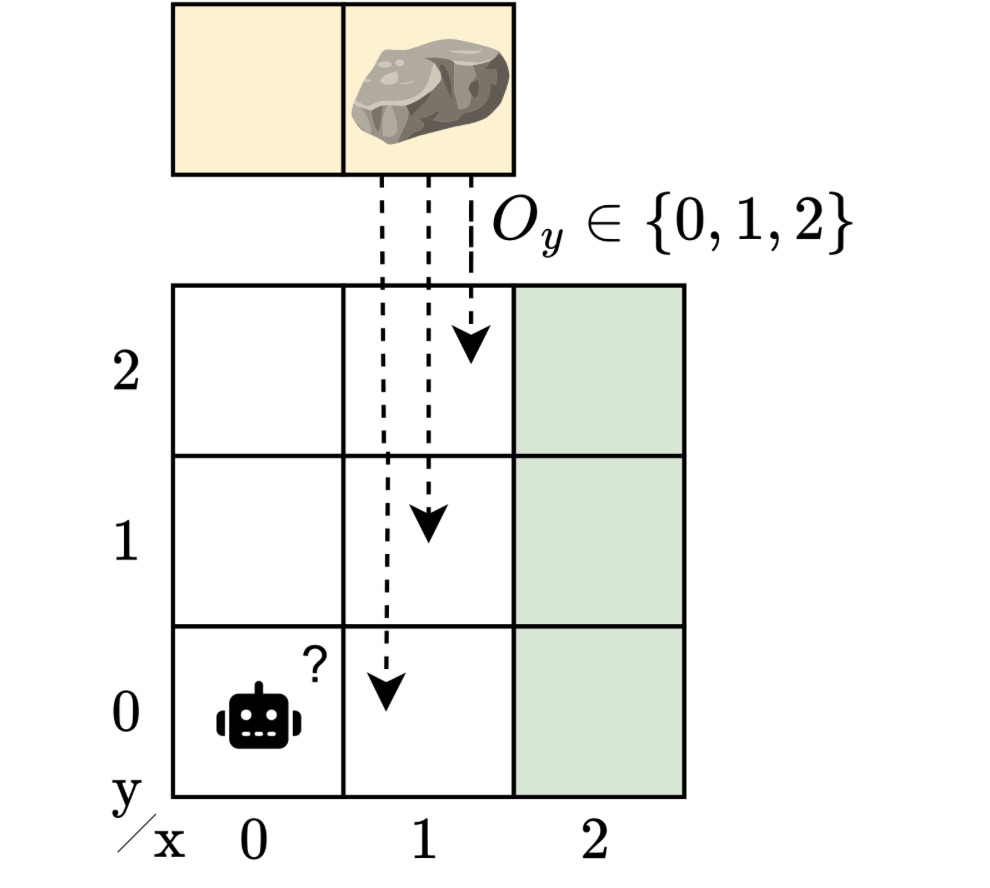
Think about a robotic navigating round an impediment to succeed in a “aim” location. We summary this state of affairs right into a grid-like atmosphere. A rock could block the trail, however the robotic doesn’t know precisely the place the rock is. If it did, the issue could be moderately straightforward: plan a route round it. However with uncertainty in regards to the impediment’s place, the robotic should be taught to function safely and effectively irrespective of the place the rock seems to be.
This easy story captures a wider problem: designing controllers that may address each partial observability and mannequin uncertainty. On this weblog publish, I’ll information you thru our IJCAI 2025 paper, “Sturdy Finite-Reminiscence Coverage Gradients for Hidden-Mannequin POMDPs”, the place we discover designing controllers that carry out reliably even when the atmosphere will not be exactly identified.
When you’ll be able to’t see every little thing
When an agent doesn’t totally observe the state, we describe its sequential decision-making drawback utilizing a partially observable Markov choice course of (POMDP). POMDPs mannequin conditions by which an agent should act, primarily based on its coverage, with out full data of the underlying state of the system. As an alternative, it receives observations that present restricted details about the underlying state. To deal with that ambiguity and make higher selections, the agent wants some type of reminiscence in its coverage to recollect what it has seen earlier than. We sometimes characterize such reminiscence utilizing finite-state controllers (FSCs). In distinction to neural networks, these are sensible and environment friendly coverage representations that encode inside reminiscence states that the agent updates because it acts and observes.
From partial observability to hidden fashions
Many conditions not often match a single mannequin of the system. POMDPs seize uncertainty in observations and within the outcomes of actions, however not within the mannequin itself. Regardless of their generality, POMDPs can’t seize units of partially observable environments. In actuality, there could also be many believable variations, as there are at all times unknowns — completely different impediment positions, barely completely different dynamics, or various sensor noise. A controller for a POMDP doesn’t generalize to perturbations of the mannequin. In our instance, the rock’s location is unknown, however we nonetheless need a controller that works throughout all potential places. It is a extra life like, but additionally a more difficult state of affairs.
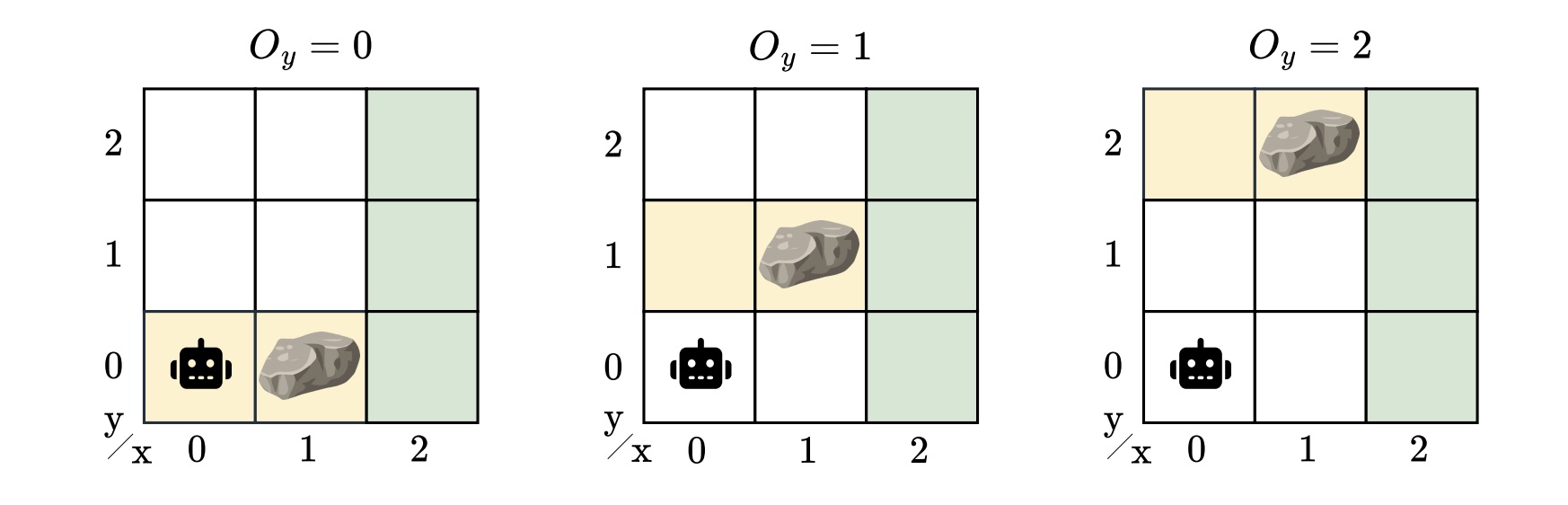
To seize this mannequin uncertainty, we launched the hidden-model POMDP (HM-POMDP). Reasonably than describing a single atmosphere, an HM-POMDP represents a set of potential POMDPs that share the identical construction however differ of their dynamics or rewards. An necessary truth is {that a} controller for one mannequin can also be relevant to the opposite fashions within the set.
The true atmosphere by which the agent will in the end function is “hidden” on this set. This implies the agent should be taught a controller that performs effectively throughout all potential environments. The problem is that the agent doesn’t simply should cause about what it might’t see but additionally about which atmosphere it’s working in.
A controller for an HM-POMDP have to be sturdy: it ought to carry out effectively throughout all potential environments. We measure the robustness of a controller by its sturdy efficiency: the worst-case efficiency over all fashions, offering a assured decrease sure on the agent’s efficiency within the true mannequin. If a controller performs effectively even within the worst case, we may be assured it should carry out acceptably on any mannequin of the set when deployed.
In the direction of studying sturdy controllers
So, how will we design such controllers?
We developed the sturdy finite-memory coverage gradient rfPG algorithm, an iterative method that alternates between the next two key steps:
- Sturdy coverage analysis: Discover the worst case. Decide the atmosphere within the set the place the present controller performs the worst.
- Coverage optimization: Enhance the controller for the worst case. Regulate the controller’s parameters with gradients from the present worst-case atmosphere to enhance sturdy efficiency.
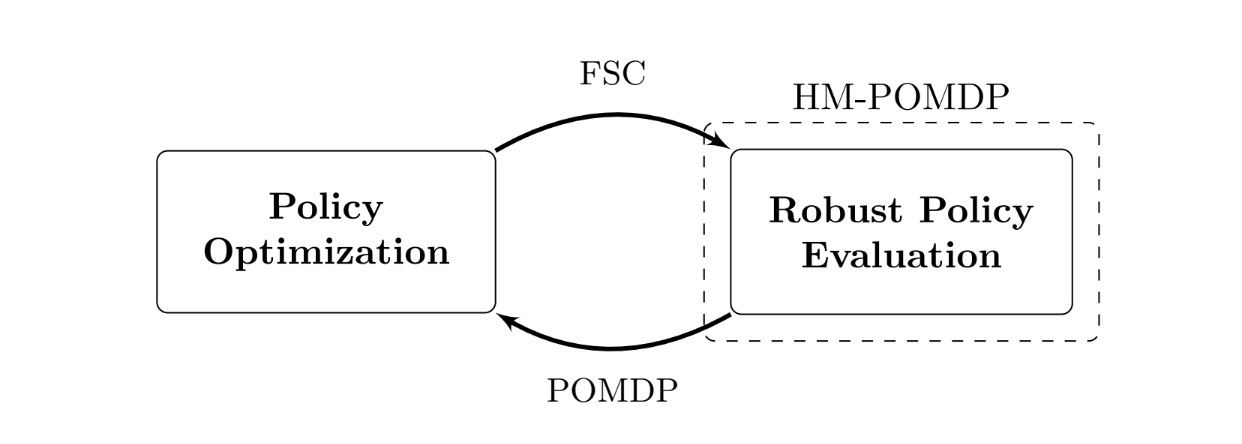
Over time, the controller learns sturdy habits: what to recollect and act throughout the encountered environments. The iterative nature of this method is rooted within the mathematical framework of “subgradients”. We apply these gradient-based updates, additionally utilized in reinforcement studying, to enhance the controller’s sturdy efficiency. Whereas the main points are technical, the instinct is straightforward: iteratively optimizing the controller for the worst-case fashions improves its sturdy efficiency throughout all of the environments.
Beneath the hood, rfPG makes use of formal verification methods applied within the device PAYNT, exploiting structural similarities to characterize giant units of fashions and consider controllers throughout them. Thanks to those developments, our method scales to HM-POMDPs with many environments. In follow, this implies we are able to cause over greater than 100 thousand fashions.
What’s the impression?
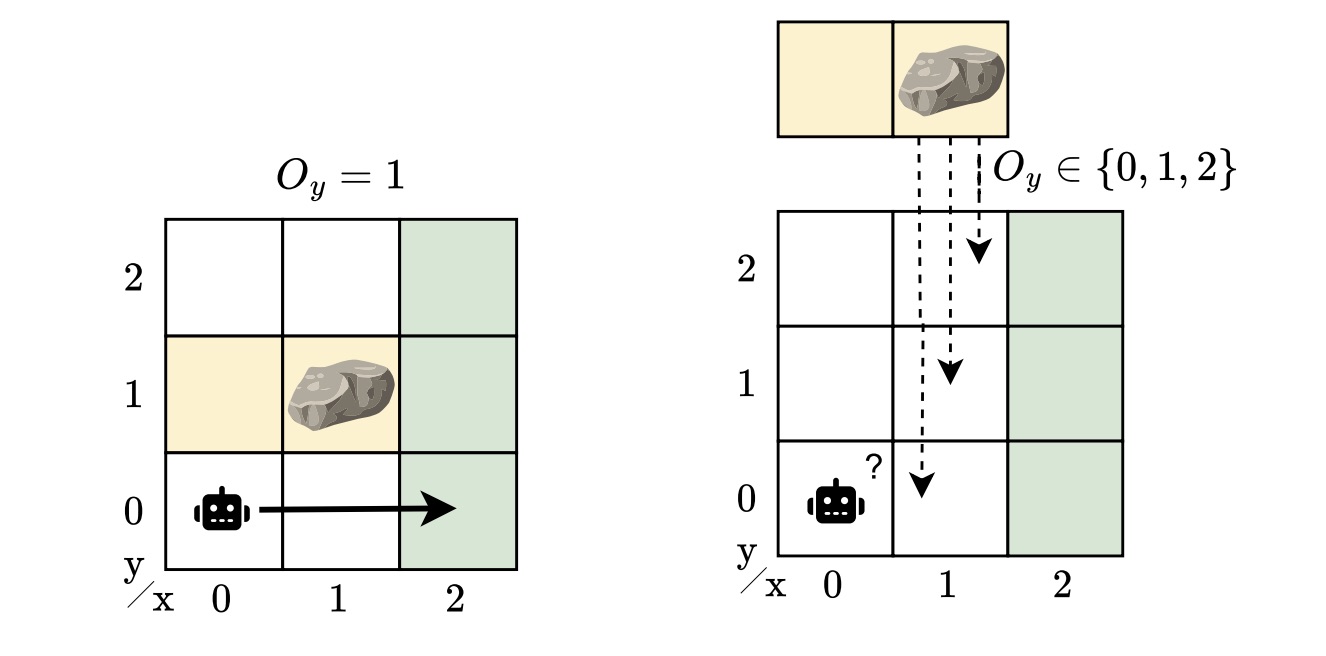
We examined rfPG on HM-POMDPs that simulated environments with uncertainty. For instance, navigation issues the place obstacles or sensor errors assorted between fashions. In these exams, rfPG produced insurance policies that weren’t solely extra sturdy to those variations but additionally generalized higher to utterly unseen environments than a number of POMDP baselines. In follow, that means we are able to render controllers sturdy to minor variations of the mannequin. Recall our working instance, with a robotic that navigates a grid-world the place the rock’s location is unknown. Excitingly, rfPG solves it near-optimally with solely two reminiscence nodes! You possibly can see the controller under.

By integrating model-based reasoning with learning-based strategies, we develop algorithms for programs that account for uncertainty slightly than ignore it. Whereas the outcomes are promising, they arrive from simulated domains with discrete areas; real-world deployment would require dealing with the continual nature of assorted issues. Nonetheless, it’s virtually related for high-level decision-making and reliable by design. Sooner or later, we are going to scale up — for instance, through the use of neural networks — and purpose to deal with broader lessons of variations within the mannequin, akin to distributions over the unknowns.
Need to know extra?
Thanks for studying! I hope you discovered it fascinating and obtained a way of our work. You could find out extra about my work on marisgg.github.io and about our analysis group at ai-fm.org.
This weblog publish is predicated on the next IJCAI 2025 paper:
- Maris F. L. Galesloot, Roman Andriushchenko, Milan Češka, Sebastian Junges, and Nils Jansen: “Sturdy Finite-Reminiscence Coverage Gradients for Hidden-Mannequin POMDPs”. In IJCAI 2025, pages 8518–8526.
For extra on the methods we used from the device PAYNT and, extra usually, about utilizing these methods to compute FSCs, see the paper under:
- Roman Andriushchenko, Milan Češka, Filip Macák, Sebastian Junges, Joost-Pieter Katoen: “An Oracle-Guided Strategy to Constrained Coverage Synthesis Beneath Uncertainty”. In JAIR, 2025.
In the event you’d wish to be taught extra about one other approach of dealing with mannequin uncertainty, take a look at our different papers as effectively. As an illustration, in our ECAI 2025 paper, we design sturdy controllers utilizing recurrent neural networks (RNNs):
- Maris F. L. Galesloot, Marnix Suilen, Thiago D. Simão, Steven Carr, Matthijs T. J. Spaan, Ufuk Topcu, and Nils Jansen: “Pessimistic Iterative Planning with RNNs for Sturdy POMDPs”. In ECAI, 2025.
And in our NeurIPS 2025 paper, we examine the analysis of insurance policies:
- Merlijn Krale, Eline M. Bovy, Maris F. L. Galesloot, Thiago D. Simão, and Nils Jansen: “On Evaluating Insurance policies for Sturdy POMDPs”. In NeurIPS, 2025.

Maris Galesloot
is an ELLIS PhD Candidate on the Institute for Computing and Data Science of Radboud College.
Maris Galesloot
is an ELLIS PhD Candidate on the Institute for Computing and Data Science of Radboud College.