

{kind=link}
Clients of all sizes have been efficiently utilizing Amazon OpenSearch Service to energy their observability workflows and acquire visibility into their purposes and infrastructure. Throughout incident investigation, Website Reliability Engineers (SREs) and operations middle personnel depend on OpenSearch Service to question logs, study visualizations, analyze patterns, correlate traces to seek out the basis reason for the incident, and scale back Imply Time to Decision (MTTR). When an incident occurs that triggers alerts, SREs sometimes soar between a number of dashboards, write particular queries, examine current deployments, and correlate between logs and traces to piece collectively a timeline of occasions. Not solely is that this course of largely handbook, but it surely additionally creates a cognitive load on these personnel, even when all the information is available. That is the place agentic AI may help, by being an clever assistant that may perceive how you can question, interpret numerous telemetry alerts, and systematically examine an incident.
On this put up, we current an observability agent utilizing OpenSearch Service and Amazon Bedrock AgentCore that may assist floor root trigger and get insights sooner, deal with a number of query-correlation cycles, and in the end scale back MTTR even additional.
Answer overview
The next diagram reveals the general structure for the observability agent.
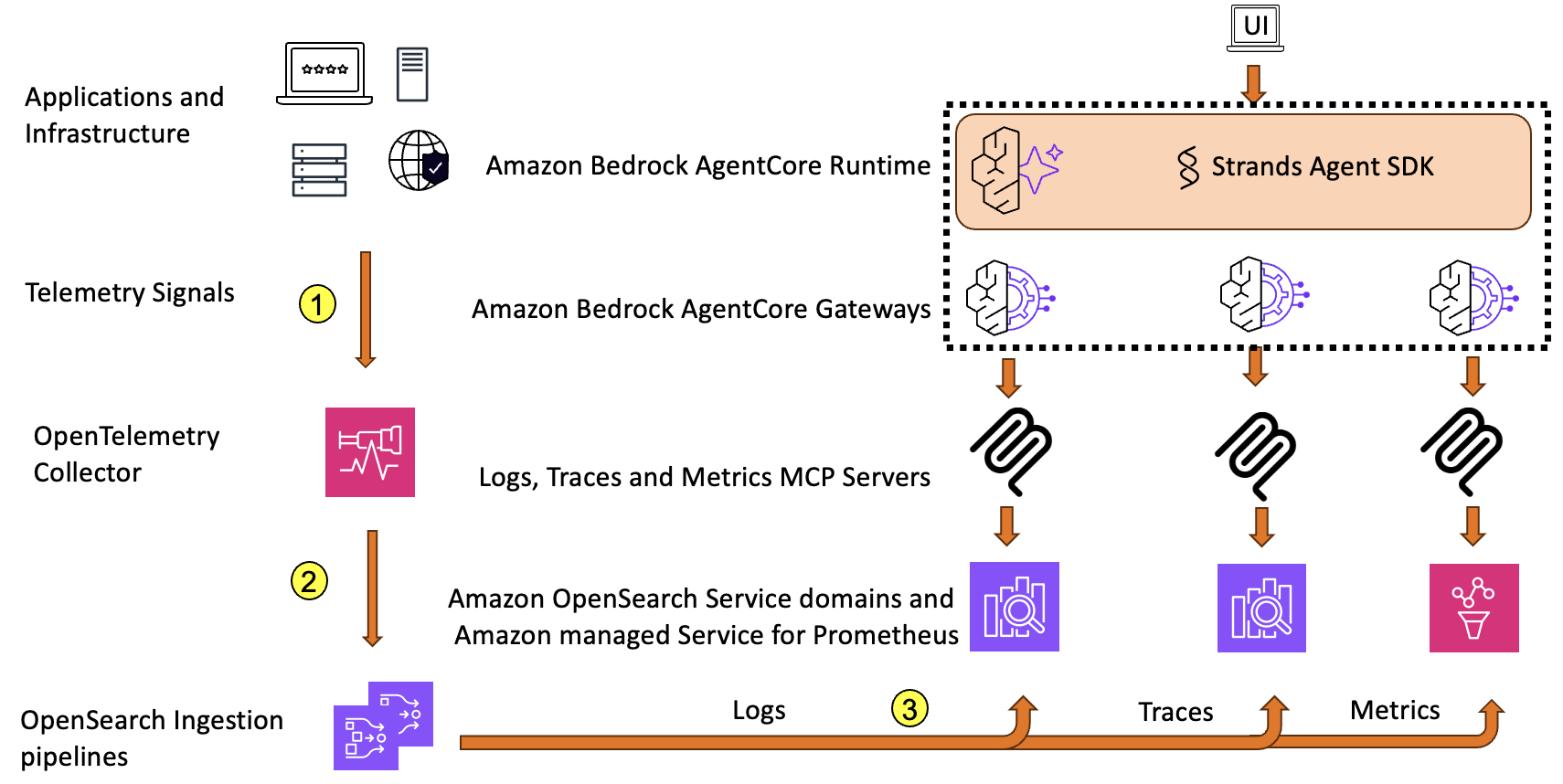
Purposes and infrastructure emit telemetry alerts within the type of logs, traces, and metrics. These alerts are then gathered by OpenTelemetry Collector (Step 1) and exported to Amazon OpenSearch Ingestion utilizing particular person pipelines for each sign: logs, traces, and metrics (Step 2). These pipelines ship the sign knowledge to an OpenSearch Service area and Amazon Managed Service for Prometheus (Step 3).
OpenTelemetry is the usual for instrumentation, and gives vendor-neutral knowledge assortment throughout a broad vary of languages and frameworks. Enterprises of assorted sizes are adopting this structure sample utilizing OpenTelemetry for his or her observability wants, particularly these dedicated to open supply instruments. Extra notably, this structure builds on open supply foundations, serving to enterprises keep away from vendor lock-in, profit from the open supply neighborhood, and implement it throughout on-premises and numerous cloud environments.
For this put up, we use the OpenTelemetry Demo utility to display our observability use case. That is an ecommerce utility powered by about 20 completely different microservices, and generates lifelike telemetry knowledge along with function units to generate load and simulate failures.
Mannequin Context Protocol servers for observability sign knowledge
The Mannequin Context Protocol (MCP) gives a standardized mechanism to attach brokers to exterior knowledge sources and instruments. On this resolution, we constructed three distinct MCP servers, one for every kind of sign.
The Logs MCP server exposes software features for looking, filtering, and choosing log knowledge that’s saved in an OpenSearch Service area for log knowledge. This allows the agent to question the logs utilizing numerous standards like easy key phrase matching, service title filter, log degree, or time ranges. This mimics the standard queries you’d run throughout an investigation. The next snippet reveals a pseudo code of what the software operate can seem like:
The Traces MCP server exposes software features for looking and retrieving details about distributed traces. These features may help search for traces by hint ID and discover traces for a selected service, the spans belonging to a hint, the service map data constructed based mostly on the spans, and the speed, error, and length (often known as RED metrics). This allows the agent to comply with a request’s path throughout the providers and pinpoint the place failures occurred or latency originated.
The Metrics MCP server exposes software features for querying time collection metrics. The agent can use these features to examine error price percentiles and useful resource utilization, that are key alerts for understanding the general well being of the system and figuring out anomalous conduct.
These three MCP servers span throughout the various kinds of knowledge utilized by investigation engineers, offering an entire working set for an agent to conduct investigations with autonomous correlation throughout logs, traces, and metrics to find out the attainable root causes for a problem. Moreover, a customized MCP server exposes software features over enterprise knowledge on income, gross sales, and different enterprise metrics. For the OpenTelemetry demo utility, you possibly can develop artificial knowledge to help in offering context for influence and different enterprise degree metrics. For brevity, we don’t present that server as part of this structure.
Observability agent
The observability agent is central to the answer. It’s constructed to assist with incident investigation. Conventional automations and handbook runbooks sometimes comply with predefined working procedures, however with an observability agent, you don’t have to outline them. The agent can analyze, cause based mostly on the information out there to it, and adapt its technique based mostly on what it discovers. It correlates findings throughout logs, traces, and metrics to reach at a root trigger.
The observability agent is constructed with the Strands Agent SDK, an open supply framework that simplifies growth of AI brokers. The SDK gives a model-driven method with flexibility to deal with underlying orchestration and reasoning (the agent loop) by invoking uncovered instruments and sustaining coherent, turn-based interactions. This implementation additionally discovers instruments dynamically, so if there’s a change within the capabilities, the agent could make choices based mostly on up-to-date data.
The agent runs on Amazon Bedrock AgentCore Runtime, which gives absolutely managed infrastructure for internet hosting and operating brokers. The runtime helps common agent frameworks, together with Stands, LangGraph, and CrewAI. The runtime additionally gives scaling availability and compute that many enterprises require to run production-grade brokers.
We use Amazon Bedrock AgentCore Gateway to hook up with all three MCP servers. When deploying brokers at scale, gateways are indispensable elements to cut back administration duties like customized code growth, infrastructure provisioning, complete ingress and egress safety, and unified entry. These are important enterprise features wanted when bringing a workload to manufacturing. On this utility, we create gateways that join all three MCP servers as targets utilizing server-sent occasions. Gateways work alongside Amazon Bedrock AgentCore Identities to offer safe credentials administration and safe identification propagation from the person to the speaking entities. The pattern utility makes use of AWS Identification and Entry Administration (IAM) for identification administration and propagation.
Incident investigation is usually a multi-step course of. It entails iterative speculation testing, a number of rounds of querying, and constructing context over time. We use Amazon Bedrock AgentCore Reminiscence for this objective. On this resolution, we use session-based namespaces to take care of separate dialog threads for various investigations. For instance, when a person asks “What about Fee service?” throughout an investigation, the agent retrieves current dialog historical past from reminiscence to take care of consciousness of prior findings. We retailer each person questions and agent responses with timestamps to assist the agent reconstruct the dialog chronologically and cause about already accomplished findings.
We configured the observability agent to make use of Anthropic’s Claude Sonnet v4.5 in Amazon Bedrock for reasoning. The mannequin interprets questions, decides which MCP software to invoke, analyzes the outcomes, and formulates the set of questions or conclusions. We use a system immediate to instruct the mannequin to assume like an skilled SRE or an operation middle engineer: “Beginning with a high-level examine, narrowing down affected elements, correlate throughout telemetry sign sorts and derive conclusion with substantiation. You ask the mannequin to additionally counsel logical subsequent steps resembling performing a drill down to analyze inter service dependencies.” This makes the agent versatile to investigate and cause about frequent styles of incident investigations.
Observability agent in motion
We constructed a real-time RED (price, errors, length) metrics dashboards for your entire utility, as proven within the following determine.
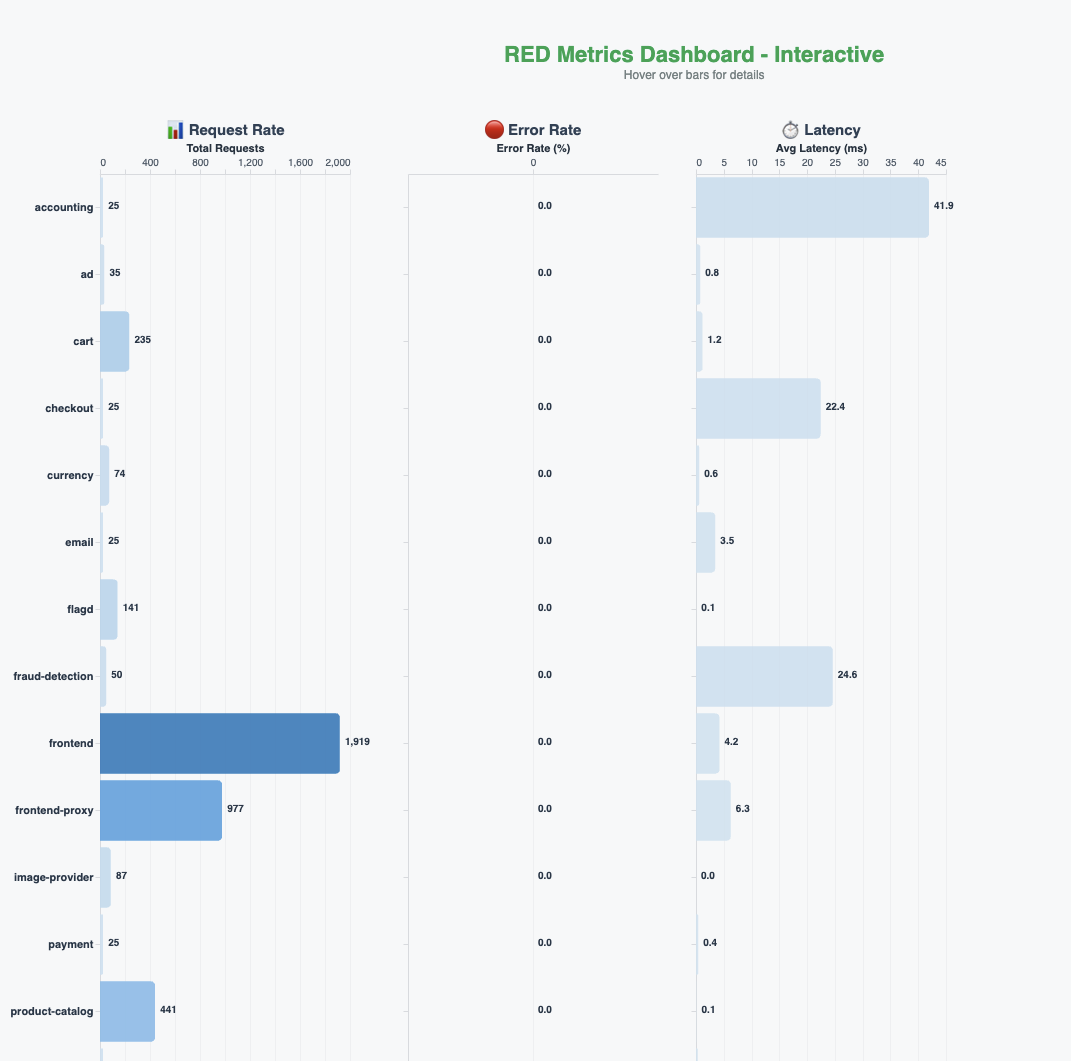
To determine a baseline, we requested the agent the next query: “Are there any errors in my utility within the final 5 minutes?”The agent queries the traces and metrics, analyzes the outcomes, and responds saying there aren’t any errors within the system. It notes that each one the providers are energetic, traces are wholesome, and the system is processing requests usually. The agent additionally proactively suggests subsequent steps that may be helpful for additional investigation.
Introducing failures
The OpenTelemetry demo utility has a function flag that we will use to introduce deliberate failures within the system. It additionally contains load technology so these errors can floor prominently. We use these options to introduce a couple of failures with the cost service. The actual-time RED metrics dashboards within the earlier determine mirror the influence and present the error charges climbing.
Investigation and root trigger evaluation
Now that we’re producing errors, we have interaction the agent once more. That is sometimes the beginning of the investigation session. Additionally, we have now workflows like alarms triggering or pages going out that can set off the beginning of an investigation.
We ask the query “Customers are complaining that it’s taking a very long time to purchase gadgets. Are you able to examine to see what’s going on?”
The agent retrieves the dialog historical past from reminiscence (if there’s any), invokes instruments to question RED metrics throughout providers, and analyzes the outcomes. It identifies a important buy stream efficiency problem: cost service is in a connectivity disaster and fully unavailable, with excessive latency noticed in fraud detection, advert service, and suggestion service. The agent gives instant motion suggestions—restore cost service connectivity as the highest precedence—and suggests subsequent steps, together with investigating cost service logs.
Following the agent’s suggestion, we ask it to analyze the logs: “Examine cost service logs to know the connectivity problem.”
The agent searches logs for the checkout and cost providers, correlates them with hint knowledge, and analyzes service dependencies from the service map. It confirms that though cart service, product catalog service, and foreign money service are wholesome, the cost service is totally unreachable, efficiently figuring out the basis reason for our intentionally launched failure.
Past root trigger: Analyzing enterprise influence
As talked about earlier, we have now artificial enterprise gross sales and income knowledge in a separate MCP server, so when the person asks the agent “Analyze the enterprise influence of the checkout and cost service failures,” the agent makes use of this enterprise knowledge, examines the transaction knowledge from traces, calculates estimated income influence, and assesses buyer abandonment charges as a consequence of checkout failures. This reveals how the agent can transcend figuring out the basis trigger and supply assist with operational actions like making a runbook for problem decision sooner or later, which may be first the step to offering computerized remediation with out involving SREs.
Advantages and outcomes
Though the failure state of affairs on this put up is simplified for illustration, it highlights a number of key advantages that straight contribute to lowering MTTR.
Accelerated investigation cycles
Conventional workflows for troubleshooting contain a number of iterations of hypotheses, verification, querying, and knowledge evaluation at every step, requiring context switching and consuming hours of effort. The observability agent reduces these drastically to some minutes by autonomous reasoning, correlation, and actioning, which in flip reduces MTTR.
Dealing with advanced workflows
Actual-world manufacturing eventualities typically contain cascading failures and a number of system failures. The observability agent’s capabilities can prolong to those eventualities by utilizing historic knowledge and sample recognition. As an illustration, it will probably distinguish associated points from false positives utilizing temporal or identity-based correlation, dependency graphs, and different strategies, serving to SREs keep away from wasted investigation effort on unrelated anomalies.
Somewhat than present a single reply, the agent can present probabilistic distribution throughout potential root causes, serving to SREs prioritize remediation strategies; for instance:
- Fee service community connectivity problem: 75%
- Downstream cost gateway timeout: 15%
- Database connection pool exhaustion: 8%
- Different/Unknown: 2%
The agent can examine present signs in opposition to previous incidents, figuring out whether or not comparable patterns have occurred prior to now, thereby evolving from a reactive question software right into a proactive diagnostic assistant.
Conclusion
Incident investigation stays largely handbook. SREs juggle dashboards, craft queries, and correlate alerts beneath strain, even when all the information is available. On this put up, we confirmed how an observability agent constructed with Amazon Bedrock AgentCore and OpenSearch Service can alleviate this cognitive burden by autonomously querying logs, traces, and metrics; correlating findings; and guiding SREs towards root trigger sooner. Though this sample represents one method, the pliability of Amazon Bedrock AgentCore mixed with the search and analytics capabilities of OpenSearch Service allows brokers to be designed and deployed in quite a few methods—at completely different levels of the incident lifecycle, with various ranges of autonomy, or targeted on particular investigation duties—to fit your group’s distinctive operational wants. Agentic AI doesn’t exchange present observability funding, however amplifies them by offering an efficient approach to make use of your knowledge throughout incident investigations.
In regards to the authors