

{kind=link}
On this submit, I’ll introduce a reinforcement studying (RL) algorithm primarily based on an “various” paradigm: divide and conquer. In contrast to conventional strategies, this algorithm is not primarily based on temporal distinction (TD) studying (which has scalability challenges), and scales properly to long-horizon duties.

We are able to do Reinforcement Studying (RL) primarily based on divide and conquer, as an alternative of temporal distinction (TD) studying.
Drawback setting: off-policy RL
Our downside setting is off-policy RL. Let’s briefly evaluate what this implies.
There are two lessons of algorithms in RL: on-policy RL and off-policy RL. On-policy RL means we are able to solely use recent knowledge collected by the present coverage. In different phrases, we’ve got to throw away previous knowledge every time we replace the coverage. Algorithms like PPO and GRPO (and coverage gradient strategies on the whole) belong to this class.
Off-policy RL means we don’t have this restriction: we are able to use any sort of knowledge, together with previous expertise, human demonstrations, Web knowledge, and so forth. So off-policy RL is extra normal and versatile than on-policy RL (and naturally tougher!). Q-learning is probably the most well-known off-policy RL algorithm. In domains the place knowledge assortment is dear (e.g., robotics, dialogue techniques, healthcare, and so on.), we frequently haven’t any selection however to make use of off-policy RL. That’s why it’s such an necessary downside.
As of 2025, I believe we’ve got fairly good recipes for scaling up on-policy RL (e.g., PPO, GRPO, and their variants). Nonetheless, we nonetheless haven’t discovered a “scalable” off-policy RL algorithm that scales properly to advanced, long-horizon duties. Let me briefly clarify why.
Two paradigms in worth studying: Temporal Distinction (TD) and Monte Carlo (MC)
In off-policy RL, we sometimes practice a price operate utilizing temporal distinction (TD) studying (i.e., Q-learning), with the next Bellman replace rule:
[begin{aligned} Q(s, a) gets r + gamma max_{a’} Q(s’, a’), end{aligned}]
The issue is that this: the error within the subsequent worth $Q(s’, a’)$ propagates to the present worth $Q(s, a)$ by way of bootstrapping, and these errors accumulate over the whole horizon. That is principally what makes TD studying wrestle to scale to long-horizon duties (see this submit if you happen to’re excited by extra particulars).
To mitigate this downside, individuals have combined TD studying with Monte Carlo (MC) returns. For instance, we are able to do $n$-step TD studying (TD-$n$):
[begin{aligned} Q(s_t, a_t) gets sum_{i=0}^{n-1} gamma^i r_{t+i} + gamma^n max_{a’} Q(s_{t+n}, a’). end{aligned}]
Right here, we use the precise Monte Carlo return (from the dataset) for the primary $n$ steps, after which use the bootstrapped worth for the remainder of the horizon. This fashion, we are able to scale back the variety of Bellman recursions by $n$ instances, so errors accumulate much less. Within the excessive case of $n = infty$, we get well pure Monte Carlo worth studying.
Whereas this can be a cheap answer (and infrequently works properly), it’s extremely unsatisfactory. First, it doesn’t basically resolve the error accumulation downside; it solely reduces the variety of Bellman recursions by a continuing issue ($n$). Second, as $n$ grows, we undergo from excessive variance and suboptimality. So we are able to’t simply set $n$ to a big worth, and have to rigorously tune it for every job.
Is there a basically completely different option to resolve this downside?
The “Third” Paradigm: Divide and Conquer
My declare is {that a} third paradigm in worth studying, divide and conquer, might present a really perfect answer to off-policy RL that scales to arbitrarily long-horizon duties.
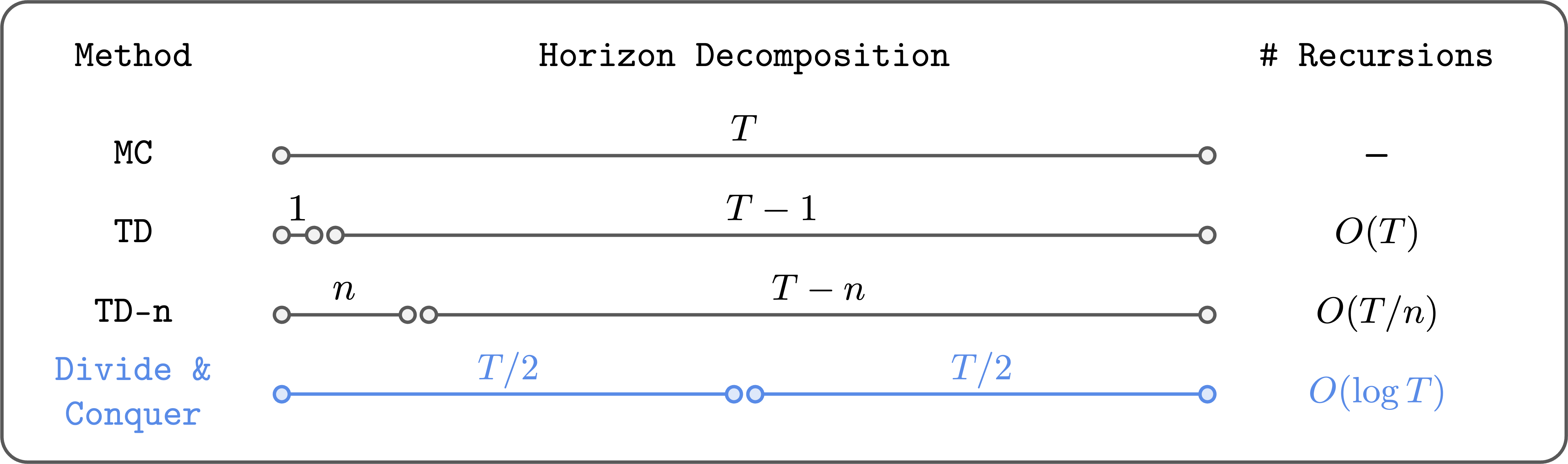
Divide and conquer reduces the variety of Bellman recursions logarithmically.
The important thing thought of divide and conquer is to divide a trajectory into two equal-length segments, and mix their values to replace the worth of the total trajectory. This fashion, we are able to (in principle) scale back the variety of Bellman recursions logarithmically (not linearly!). Furthermore, it doesn’t require selecting a hyperparameter like $n$, and it doesn’t essentially undergo from excessive variance or suboptimality, not like $n$-step TD studying.
Conceptually, divide and conquer actually has all the great properties we would like in worth studying. So I’ve lengthy been enthusiastic about this high-level thought. The issue was that it wasn’t clear the way to truly do that in observe… till not too long ago.
A sensible algorithm
In a current work co-led with Aditya, we made significant progress towards realizing and scaling up this concept. Particularly, we had been capable of scale up divide-and-conquer worth studying to extremely advanced duties (so far as I do know, that is the primary such work!) a minimum of in a single necessary class of RL issues, goal-conditioned RL. Purpose-conditioned RL goals to be taught a coverage that may attain any state from some other state. This gives a pure divide-and-conquer construction. Let me clarify this.
The construction is as follows. Let’s first assume that the dynamics is deterministic, and denote the shortest path distance (“temporal distance”) between two states $s$ and $g$ as $d^*(s, g)$. Then, it satisfies the triangle inequality:
[begin{aligned} d^*(s, g) leq d^*(s, w) + d^*(w, g) end{aligned}]
for all $s, g, w in mathcal{S}$.
By way of values, we are able to equivalently translate this triangle inequality to the next “transitive” Bellman replace rule:
[begin{aligned}
V(s, g) gets begin{cases}
gamma^0 & text{if } s = g, \
gamma^1 & text{if } (s, g) in mathcal{E}, \
max_{w in mathcal{S}} V(s, w)V(w, g) & text{otherwise}
end{cases}
end{aligned}]
the place $mathcal{E}$ is the set of edges within the setting’s transition graph, and $V$ is the worth operate related to the sparse reward $r(s, g) = 1(s = g)$. Intuitively, which means that we are able to replace the worth of $V(s, g)$ utilizing two “smaller” values: $V(s, w)$ and $V(w, g)$, supplied that $w$ is the optimum “midpoint” (subgoal) on the shortest path. That is precisely the divide-and-conquer worth replace rule that we had been in search of!
The issue
Nonetheless, there’s one downside right here. The difficulty is that it’s unclear how to decide on the optimum subgoal $w$ in observe. In tabular settings, we are able to merely enumerate all states to search out the optimum $w$ (that is basically the Floyd-Warshall shortest path algorithm). However in steady environments with massive state areas, we are able to’t do that. Principally, for this reason earlier works have struggled to scale up divide-and-conquer worth studying, although this concept has been round for many years (in reality, it dates again to the very first work in goal-conditioned RL by Kaelbling (1993) – see our paper for an extra dialogue of associated works). The primary contribution of our work is a sensible answer to this difficulty.
The answer
Right here’s our key thought: we limit the search house of $w$ to the states that seem within the dataset, particularly, those who lie between $s$ and $g$ within the dataset trajectory. Additionally, as an alternative of looking for the optimum $textual content{argmax}_w$, we compute a “delicate” $textual content{argmax}$ utilizing expectile regression. Specifically, we decrease the next loss:
[begin{aligned} mathbb{E}left[ell^2_kappa (V(s_i, s_j) – bar{V}(s_i, s_k) bar{V}(s_k, s_j))right], finish{aligned}]
the place $bar{V}$ is the goal worth community, $ell^2_kappa$ is the expectile loss with an expectile $kappa$, and the expectation is taken over all $(s_i, s_k, s_j)$ tuples with $i leq okay leq j$ in a randomly sampled dataset trajectory.
This has two advantages. First, we don’t want to look over the whole state house. Second, we stop worth overestimation from the $max$ operator by as an alternative utilizing the “softer” expectile regression. We name this algorithm Transitive RL (TRL). Try our paper for extra particulars and additional discussions!
Does it work properly?
humanoidmaze
puzzle
To see whether or not our technique scales properly to advanced duties, we immediately evaluated TRL on among the most difficult duties in OGBench, a benchmark for offline goal-conditioned RL. We primarily used the toughest variations of humanoidmaze and puzzle duties with massive, 1B-sized datasets. These duties are extremely difficult: they require performing combinatorially advanced expertise throughout as much as 3,000 setting steps.
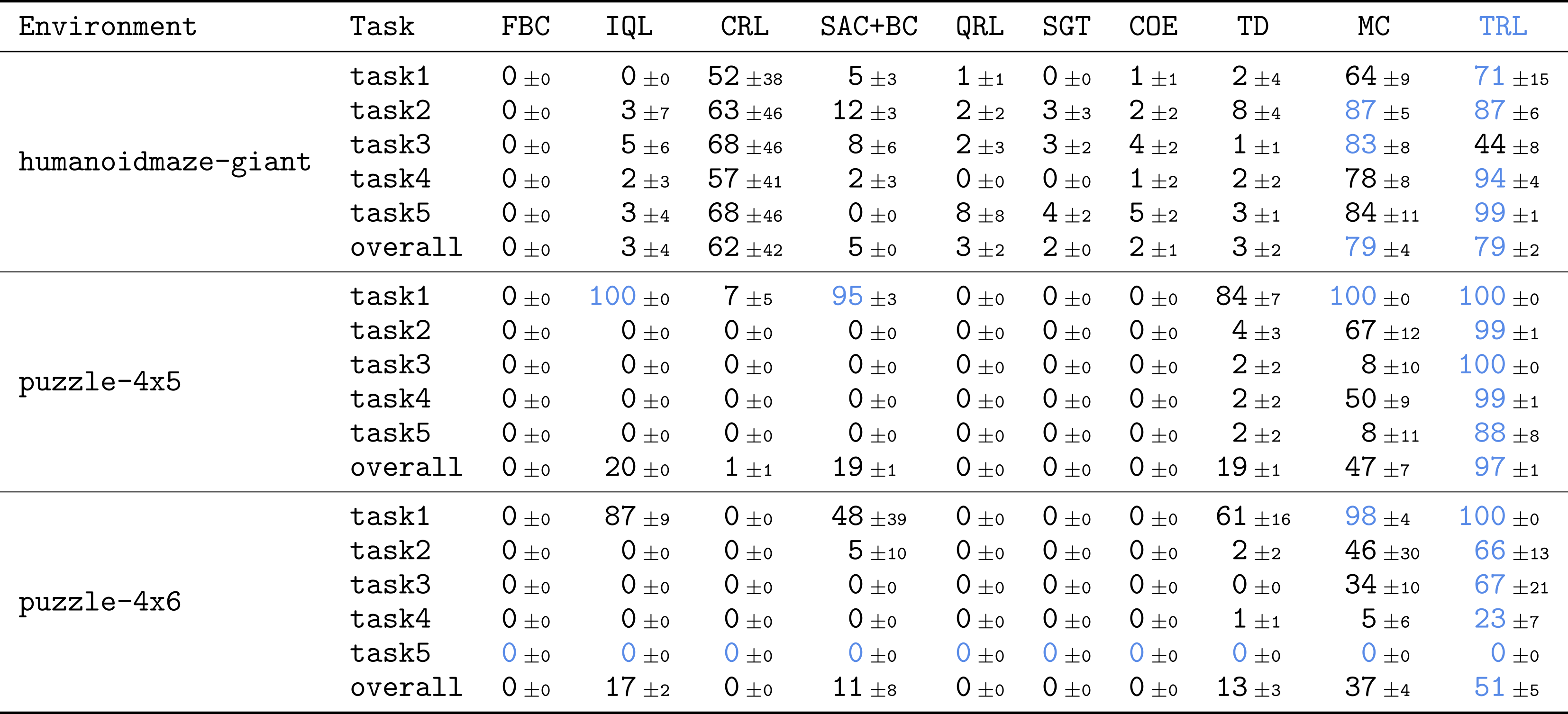
TRL achieves the perfect efficiency on extremely difficult, long-horizon duties.
The outcomes are fairly thrilling! In comparison with many sturdy baselines throughout completely different classes (TD, MC, quasimetric studying, and so on.), TRL achieves the perfect efficiency on most duties.

TRL matches the perfect, individually tuned TD-$n$, without having to set $boldsymbol{n}$.
That is my favourite plot. We in contrast TRL with $n$-step TD studying with completely different values of $n$, from $1$ (pure TD) to $infty$ (pure MC). The result’s very nice. TRL matches the perfect TD-$n$ on all duties, without having to set $boldsymbol{n}$! That is precisely what we wished from the divide-and-conquer paradigm. By recursively splitting a trajectory into smaller ones, it may well naturally deal with lengthy horizons, with out having to arbitrarily select the size of trajectory chunks.
The paper has a variety of further experiments, analyses, and ablations. For those who’re , try our paper!
What’s subsequent?
On this submit, I shared some promising outcomes from our new divide-and-conquer worth studying algorithm, Transitive RL. That is just the start of the journey. There are various open questions and thrilling instructions to discover:
-
Maybe an important query is the way to prolong TRL to common, reward-based RL duties past goal-conditioned RL. Would common RL have an identical divide-and-conquer construction that we are able to exploit? I’m fairly optimistic about this, on condition that it’s potential to transform any reward-based RL job to a goal-conditioned one a minimum of in principle (see web page 40 of this guide).
-
One other necessary problem is to cope with stochastic environments. The present model of TRL assumes deterministic dynamics, however many real-world environments are stochastic, primarily on account of partial observability. For this, “stochastic” triangle inequalities may present some hints.
-
Virtually, I believe there’s nonetheless a variety of room to additional enhance TRL. For instance, we are able to discover higher methods to decide on subgoal candidates (past those from the identical trajectory), additional scale back hyperparameters, additional stabilize coaching, and simplify the algorithm much more.
Typically, I’m actually excited concerning the potential of the divide-and-conquer paradigm. I nonetheless assume one of the necessary issues in RL (and even in machine studying) is to discover a scalable off-policy RL algorithm. I don’t know what the ultimate answer will seem like, however I do assume divide and conquer, or recursive decision-making on the whole, is likely one of the strongest candidates towards this holy grail (by the way in which, I believe the opposite sturdy contenders are (1) model-based RL and (2) TD studying with some “magic” methods). Certainly, a number of current works in different fields have proven the promise of recursion and divide-and-conquer methods, similar to shortcut fashions, log-linear consideration, and recursive language fashions (and naturally, traditional algorithms like quicksort, phase timber, FFT, and so forth). I hope to see extra thrilling progress in scalable off-policy RL within the close to future!
Acknowledgments
I’d prefer to thank Kevin and Sergey for his or her useful suggestions on this submit.
This submit initially appeared on Seohong Park’s weblog.