

{kind=link}
Inference scaling has introduced LLMs to the place they will purpose by most sensible conditions, offered they’ve the precise context. For a lot of real-world brokers, the bottleneck is now not reasoning capability, however grounding the agent within the appropriate info: giving the mannequin what it wants for the duty at hand.
This means a brand new axis for agent design. Somewhat than focusing solely on stronger fashions or higher prompts, we are able to ask: does the agent get higher because it accumulates extra info? We name this reminiscence scaling: the property that agent efficiency improves with the quantity of previous conversations, person suggestions, interplay trajectories (each profitable and failed), and enterprise context saved in its reminiscence. The impact is very pronounced in enterprise settings, the place tribal information is plentiful and a single agent serves many customers.
However this isn’t apparent a priori. Extra reminiscence doesn’t mechanically make an agent higher: low-quality traces can train the incorrect classes, and retrieval will get tougher as the shop grows. The central query is whether or not brokers can use bigger recollections productively relatively than merely accumulate them.
We have made early steps on this course at Databricks by ALHF and MemAlign, which modify agent habits primarily based on human suggestions, and the Instructed Retriever, which allows search brokers to translate advanced natural-language directions and knowledge-source schemas into exact, structured search queries. Collectively, these methods reveal that brokers will be extra useful by persistent reminiscence. This submit presents experimental outcomes demonstrating reminiscence scaling habits, discusses the infrastructure required to help it in manufacturing, and supplies a ahead wanting imaginative and prescient of memory-based brokers.
What Is Reminiscence Scaling?
Reminiscence scaling is the property that an agent’s efficiency improves as its exterior reminiscence grows. Right here “reminiscence” refers to a persistent retailer of data the agent can work together with at inference time, distinct from the mannequin’s weights or the present context window.
This makes reminiscence scaling a definite and complementary axis to each parametric scaling and inference-time scaling, addressing gaps in area information and grounding that neither mannequin measurement nor reasoning functionality can shut on their very own.The enhancements attributable to reminiscence scaling aren’t restricted to reply high quality. When an agent has memorized the related schemas, area guidelines, or profitable previous actions for an atmosphere, it will possibly skip redundant exploration and resolve queries quicker. In our experiments, we observe scaling in each accuracy and effectivity.
Relationship to continuous studying
Continuous studying sometimes focuses on updating mannequin parameters over time, which works properly in bounded settings however turns into computationally costly and brittle with many concurrent customers, brokers, and quickly shifting tasks. Reminiscence scaling asks a special query: does an agent with hundreds of customers carry out higher than one with a single person? By increasing an agent’s shared exterior state whereas conserving LLM weights frozen, the reply will be sure — a workflow sample realized from one person will be retrieved and utilized for one more instantly, with none retraining. It is a property that continuous studying, centered as it’s on a single person’s mannequin parameter updates, was by no means designed to supply.
Relationship to lengthy context
Massive context home windows would possibly look like an alternative to reminiscence, however they handle totally different issues. Packing thousands and thousands of uncooked tokens right into a immediate will increase latency, raises compute prices, and degrades reasoning high quality as irrelevant tokens compete for consideration. Reminiscence scaling depends as a substitute on selective retrieval — deciding not simply how a lot context to incorporate, however what to incorporate, surfacing solely the high-signal info related to the present job.
Kinds of Reminiscence
Not all recollections serve the identical objective. Two distinctions matter in follow:
Episodic vs. semantic. Episodic recollections are uncooked information of previous interactions — dialog logs, tool-call trajectories, person suggestions. Semantic recollections are generalized abilities and info distilled from these interactions (e.g., “customers on this area at all times imply fiscal quarter after they say ‘quarter'”). Every sort requires totally different storage, processing, and retrieval methods: episodic recollections for direct retrieval and semantic recollections distilled by an LLM for broader sample matching.
Private vs. organizational. Some recollections are particular to a single person’s preferences and workflows; others characterize shared organizational information — naming conventions, widespread queries, enterprise guidelines. The reminiscence system should scope retrieval and updates appropriately: floor organizational information broadly whereas conserving particular person context non-public, respecting permissions and ACLs.
Experiments: MemAlign on Genie Area
MemAlign is our exploration into what a easy reminiscence framework can appear like for AI brokers. It shops previous interactions as episodic recollections, makes use of an LLM to distill them into generalized guidelines and patterns (semantic recollections), and retrieves essentially the most related entries at inference time to information the agent. For particulars on the framework, see our earlier weblog submit.
We examined MemAlign on Databricks Genie Areas, a natural-language interface the place enterprise customers ask knowledge questions in plain English and obtain SQL-based solutions. An instance of the duty question and reply is offered belo
Our purpose is to measure how agent efficiency scales as we feed it extra reminiscence, utilizing two knowledge sources: curated examples (labeled) and uncooked person dialog logs (unlabeled).
Scaling with labeled knowledge
We evaluated MemAlign on unseen questions unfold throughout 10 Genie areas, incrementally including shards of annotated coaching examples to the agent’s reminiscence. Our baseline is an agent utilizing expert-curated Genie directions (manually written desk schemas, area guidelines, and few-shot examples).
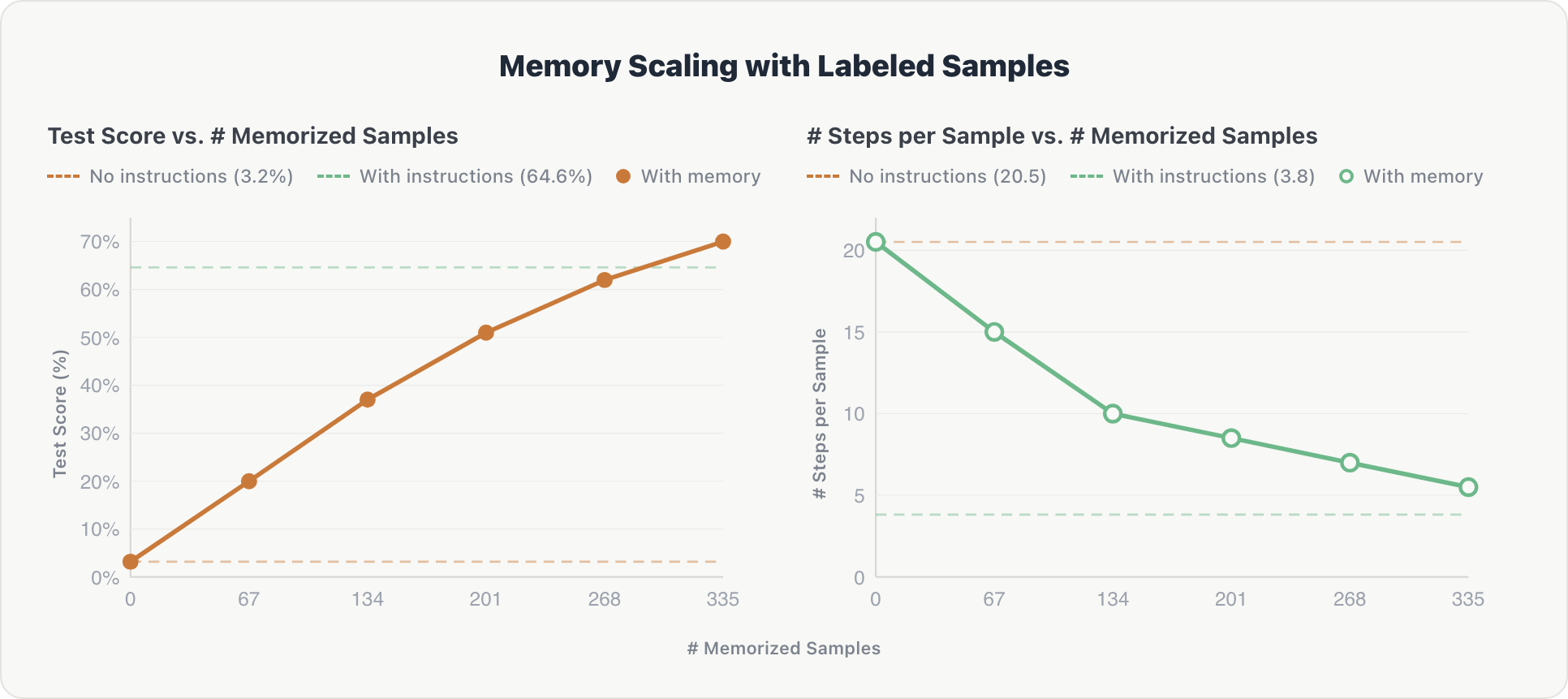
The outcomes present constant scaling alongside each dimensions:
Accuracy. Check scores elevated steadily with every extra reminiscence shard, rising from close to zero to 70%, in the end surpassing the expert-curated baseline by ~5%. Upon inspection, human-labeled knowledge proved extra complete and subsequently extra helpful than manually written desk schemas and area guidelines.
Effectivity. The typical variety of reasoning steps per instance dropped from ~20 to ~5 as reminiscence grew. The agent realized to retrieve related context instantly relatively than exploring the database from scratch, approaching the effectivity of hardcoded directions (~3.8 steps).
The impact is cumulative: as a result of the memorized samples span 10 totally different Genie areas, every shard contributes cross-domain info that builds on prior information.
Scaling with unlabeled person logs
Can reminiscence scale with noisy, real-world knowledge? To seek out out, we ran MemAlign in a dwell Genie area and fed it historic person dialog logs with no gold solutions. An LLM decide filtered these logs for helpfulness, and solely the high-quality ones had been memorized.
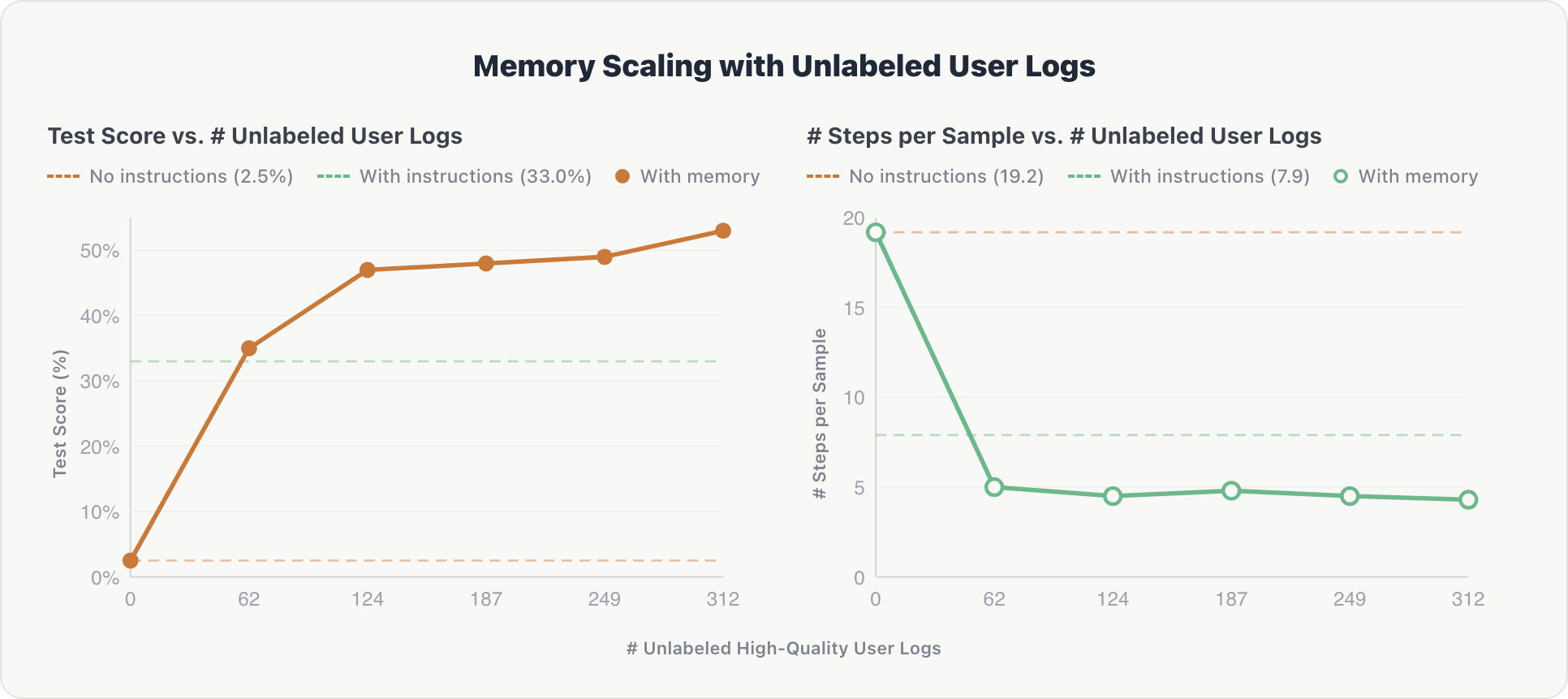
The scaling curve follows an identical sample and is steeper initially:
Accuracy. The agent confirmed a pointy preliminary achieve. After the primary log shard, it extracted key details about related tables and implicit person preferences. Efficiency rose from 2.5% to over 50%, surpassing the expert-curated baseline (33.0%) after simply 62 log information.
Effectivity. Reasoning steps dropped from ~19 to ~4.3 after the primary shard and remained secure. The agent internalized the area’s schema early and prevented redundant exploration on subsequent queries.
The takeaway: uncurated person interactions, filtered solely by an automatic, reference-free decide, can substitute for the expensive and time consuming hand-engineered area directions. This additionally factors towards brokers that enhance repeatedly from regular utilization and might scale past the restrictions of human annotation.
Experiments: Organizational Information Retailer
The experiments above present how reminiscence scaling occurs with person interactions. However enterprises even have present information that predates any person interplay: desk schemas, dashboard queries, enterprise glossaries, and inside documentation. We examined whether or not pre-computing this organizational information right into a structured reminiscence retailer may enhance agent efficiency.
We evaluated this data retailer on an inside knowledge analysis benchmark and on PMBench, which exams exhaustive truth search over blended inside paperwork like product supervisor assembly notes and planning supplies.
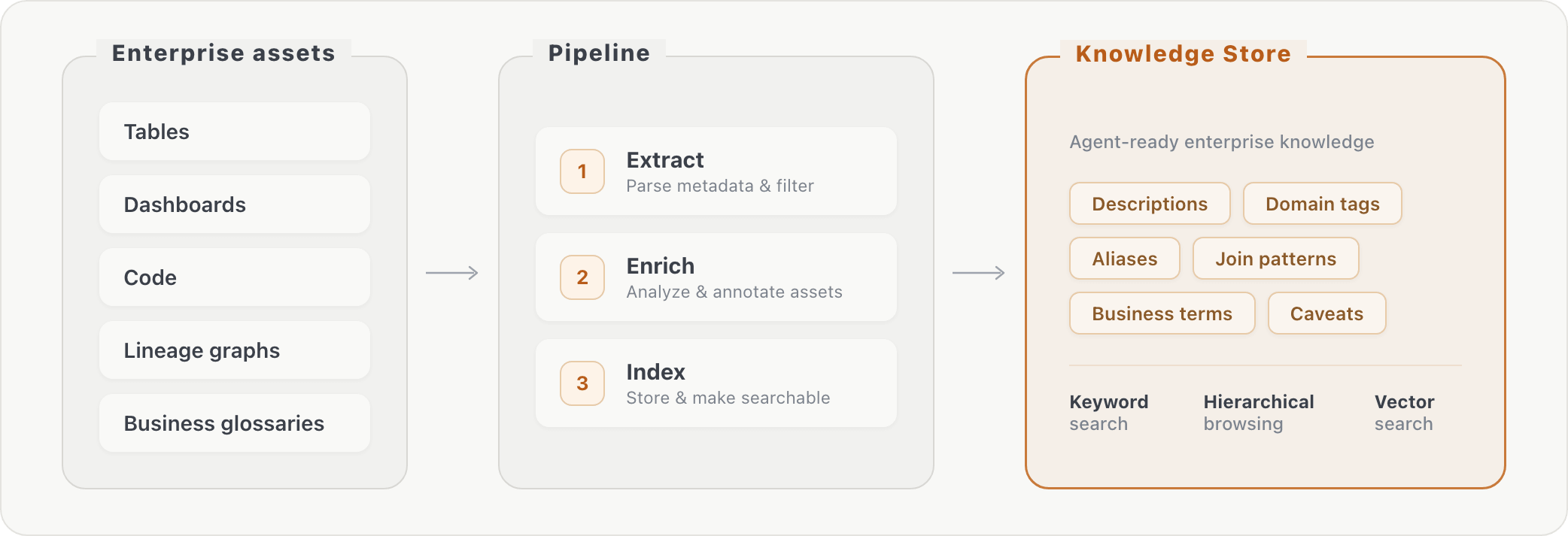
Our pipeline processes uncooked database metadata into retrievable information in three phases: (1) extraction of details about belongings, (2) asset enrichment through extra transformations, and (3) indexing of the enriched content material. At question time, the agent can lookup enterprise context through key phrase search or hierarchical searching. This bridges the hole between how enterprise customers phrase questions (“AI consumption”) and the way knowledge is definitely saved (particular column names in particular tables).
Including the information retailer improved accuracy by roughly 10% on each evaluated benchmarks. The positive aspects had been targeting questions that required vocabulary bridging, desk joins, and column-level information, i.e., info the agent couldn’t have found by schema exploration alone.
Infrastructure for Reminiscence Scaling
Reminiscence scaling in enterprise deployments requires a strong infrastructure past a easy vector retailer. In what follows, we’ll talk about three key challenges that this infrastructure wants to deal with: scalable storage, reminiscence administration, and governance.
Scalable Storage
The best reminiscence storage is the file system: markdown recordsdata in hierarchical folders, browsed and searched with commonplace shell instruments. File-based reminiscence works properly at small scale and for particular person customers, but it surely lacks indexing, structured queries, and environment friendly similarity search. As reminiscence grows to hundreds of entries throughout many customers, retrieval degrades and governance turns into tough to implement.
Devoted knowledge shops are the pure subsequent step. Standalone vector databases deal with semantic search properly however lack relational capabilities like joins and filtering. Fashionable PostgreSQL-based methods provide a extra unified different: they natively help structured queries, full-text search, and vector similarity search in a single engine.
Serverless variants of this structure that separate storage from compute, and supply low-cost, sturdy storage are a pure match. We have been utilizing Lakebase, constructed on Neon‘s serverless PostgreSQL engine, due to its scale-to-0 value and help for each vector and precise search. Constructed-in database branching additionally simplifies the event cycle — engineers can fork the agent’s reminiscence state for testing with out affecting manufacturing.
Reminiscence Administration
Scalable storage alone will not be sufficient. A reminiscence system should additionally handle its contents:
- Bootstrapping. New brokers are recognized to endure from cold-start issues. Ingesting present enterprise belongings (wikis, documentation, inside guides) by doc parsing and extraction supplies an preliminary reminiscence base that may alleviate a few of these issues, as demonstrated by our organizational information retailer experiments.
- Distillation. Uncooked episodic recollections are helpful for direct retrieval however develop into costly to retailer and search at scale. Periodically distilling them into semantic recollections (compressed guidelines and patterns) retains the reminiscence retailer tractable, and supplies generalizable insights to the agent, which will not be evident from episodic reminiscence alone.
- Consolidation. As reminiscence grows, it is very important preserve the system constant, compact, and up-to-date. This requires pipelines that take away duplicates, prune outdated info, and resolve conflicts between previous and new entries.
Safety
Reminiscence introduces governance necessities that don’t exist for stateless brokers. As brokers accumulate deeply contextual information, together with person preferences, proprietary workflows, and inside knowledge patterns, the identical governance ideas that apply to enterprise knowledge should prolong to agent reminiscence.
Entry controls have to be identity-aware: particular person recollections ought to stay non-public, whereas organizational information will be shared inside access-controlled bounds. This maps naturally to the form of fine-grained permissions that platforms like Unity Catalog already implement for knowledge belongings, comparable to row-level safety, column masking, and attribute-based entry management.
Extending these controls to reminiscence entries means an agent retrieving context for one person can’t inadvertently floor one other person’s non-public interactions.
Past entry management, knowledge lineage and auditability matter. When an agent’s habits is formed by its reminiscence, groups have to hint which recollections influenced a given response and when these recollections had been created or up to date. Compliance and regulatory necessities, notably in regulated industries, demand that reminiscence shops help the identical observability ensures because the underlying knowledge: full lineage monitoring, retention insurance policies, and the flexibility to purge particular entries on request.
Guaranteeing that the precise reminiscence reaches the precise person, and solely that person, is a central design downside at scale.
What Will get within the Approach
Each scaling axis finally runs into its personal bottleneck. Parametric scaling is constrained by the availability of high-quality coaching knowledge. Inference-time scaling can devolve into overthinking, the place longer chains of reasoning add value with out including sign, in the end degrading efficiency as sequence size will increase. Reminiscence scaling has analogous limits: issues of high quality, scope, and entry.
Reminiscence high quality is difficult to take care of. Some recollections are incorrect from the beginning; others develop into incorrect over time. A stateless agent makes remoted errors, however a memory-equipped agent can flip one mistake right into a recurring one by storing it and retrieving it later as proof. We’ve got seen brokers cite notebooks from earlier runs that had been themselves incorrect, then reuse these outcomes with much more confidence. Staleness is subtler: an agent that realized final quarter’s schema could preserve querying tables which have since been renamed or deleted. Filtering at ingestion helps, however manufacturing methods want greater than filtering. They want provenance, confidence estimates, freshness alerts, and periodic re-validation.
Governance should prolong to distillation. Scaling reminiscence throughout a company requires distilling repeated interactions into reusable semantic recollections. However abstraction doesn’t take away sensitivity. A reminiscence like “for firm Y, be a part of the CRM, market-intelligence, and partnership tables” could look innocent whereas nonetheless revealing confidential acquisition curiosity. The problem is to make reminiscence broadly helpful with out turning non-public patterns into shared information. Entry controls and sensitivity labels should survive distillation, not simply ingestion.
Helpful recollections could stay unreachable. Even when reminiscence is correct and present, the agent nonetheless has to find that it exists. Retrieval is inherently meta-cognitive: the agent should resolve what to ask its reminiscence retailer earlier than it is aware of what’s in there. When it fails to anticipate {that a} related reminiscence would possibly assist, it by no means points the precise question and falls again to sluggish, redundant exploration. In follow, the hole between saved information and accessible information could also be the principle limiter on reminiscence scaling.
These aren’t arguments towards reminiscence scaling. They’re the analysis issues that also must be solved to make reminiscence scaling strong. The central downside isn’t just storing extra historical past; it’s educating the agent easy methods to discover the precise reminiscence, easy methods to use it appropriately, and easy methods to preserve it present and correctly scoped.
Trying Forward: The Agent as Reminiscence
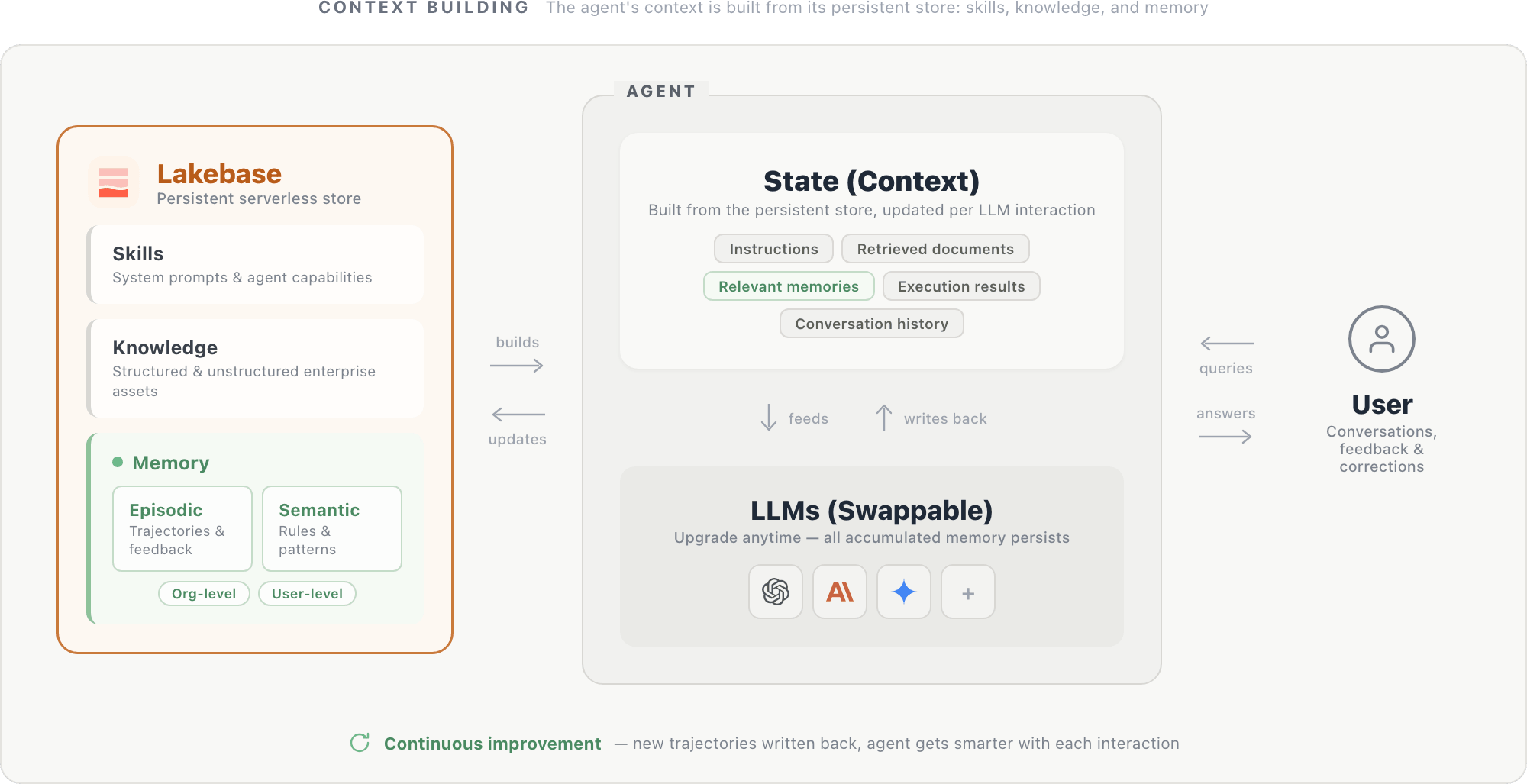
The experiments and infrastructure above level towards a pure design sample: an agent whose identification lives in its reminiscence, not its mannequin weights.
On this design, an agent’s context is constructed from a persistent retailer housed in a serverless database like Lakebase. The shop holds three parts: system prompts and agent capabilities (abilities), structured and unstructured enterprise belongings (information), and episodic and semantic recollections scoped on the group and person degree. Collectively, these parts kind the agent’s state: directions, retrieved paperwork, related recollections, execution outcomes (from SQL queries, API calls, and different instruments), and dialog historical past. This state is fed to the LLM at every step and up to date after every interplay.
The LLM itself is a swappable reasoning engine: upgrading to a more recent mannequin is simple, for the reason that new mannequin reads from the identical persistent retailer and instantly advantages from all accrued context.
As basis fashions converge in functionality, the differentiator for enterprise brokers will more and more be what reminiscence they’ve accrued relatively than which mannequin they name. Hypothetically, a smaller mannequin with a wealthy reminiscence retailer can outperform a bigger mannequin with much less reminiscence — if that’s the case, investing in reminiscence infrastructure may yield better returns than scaling mannequin parameters. Area information, person preferences, and operational patterns particular to your group aren’t in any basis mannequin. They will solely be constructed up by use, and in contrast to mannequin capabilities, they’re distinctive to every deployment.
Conclusion
We suggest Reminiscence Scaling, the place an agent’s efficiency improves because it accumulates extra expertise by person interplay and enterprise context into reminiscence. Our preliminary experiments present that each accuracy and effectivity scale with the quantity of data saved in exterior reminiscence.
Realizing this in manufacturing requires storage methods that unify structured and unstructured search, administration pipelines that preserve reminiscence constant, and governance controls that scope entry appropriately. These are solvable issues with present know-how. The payoff is brokers that genuinely enhance with continued use.
The remaining work is substantial: reminiscence has to remain correct, present, and accessible because it grows. However that’s precisely why reminiscence scaling is attention-grabbing. It opens a concrete methods and analysis agenda for constructing brokers that get higher with continued use in methods which are particular to every group and downside.
Authors: Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
We’d prefer to thank Kenneth Choi, Sam Havens, Andy Zhang, Ziyi Yang, Ashutosh Baheti, Sean Kulinski, Alexander Trott, Will Tipton, Gavin Peng, Rishabh Singh, and Patrick Wendell for his or her priceless suggestions all through the mission.