

{kind=link}
This put up was co-authored by Mike Araujo Principal Engineer at Medidata Options.
The life sciences business is transitioning from fragmented, standalone instruments in the direction of built-in, platform-based options. Medidata, a Dassault Systèmes firm, is constructing a next-generation information platform that addresses the advanced challenges of recent scientific analysis. On this put up, we present you the way Medidata created a unified, scalable, real-time information platform that serves 1000’s of scientific trials worldwide with AWS companies, Apache Iceberg, and a contemporary lakehouse structure.
Challenges with legacy structure
Because the Medidata scientific information repository expanded, the staff acknowledged the shortcomings of the legacy information resolution to supply high quality information merchandise to their clients throughout their rising portfolio of information choices. A number of information tenants started to erode. The next diagram exhibits Medidata’s legacy extract, rework, and cargo (ETL) structure.
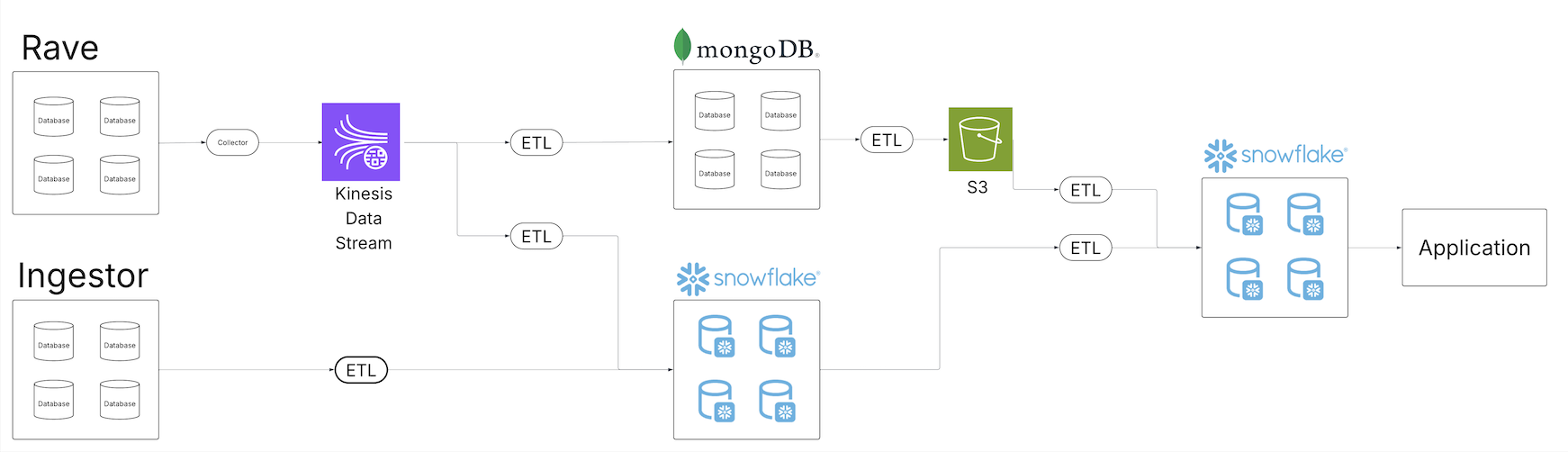
Constructed upon a sequence of scheduled batch jobs, the legacy system proved ill-equipped to supply a unified view of the information throughout the complete ecosystem. Batch jobs ran at totally different intervals, typically requiring a enough diploma of scheduling buffer to verify upstream jobs accomplished inside the anticipated window. As the information quantity expanded, the roles and their schedules continued to inflate, introducing a latency window between ingestion and processing for dependent customers. Totally different customers working from varied underlying information companies additional magnified the issue as pipelines needed to be repeatedly constructed throughout quite a lot of information supply stacks.
The increasing portfolio of pipelines started to overwhelm current upkeep operations. With extra operations, the chance for failure expanded and restoration efforts additional sophisticated. Current observability programs had been inundated with operational information, and figuring out the foundation trigger of information high quality points grew to become a multi-day endeavor. Will increase within the information quantity required scaling issues throughout the complete information property.
Moreover, the proliferation of information pipelines and copies of the information in several applied sciences and storage programs necessitated increasing entry controls with enhanced security measures to verify solely the proper customers had entry to the subset of information to which they had been permitted. Ensuring entry management adjustments had been accurately propagated throughout all programs added an extra layer of complexity to customers and producers.
Answer overview
With the appearance of Scientific Information Studio (Medidata’s unified information administration and analytics resolution for scientific trials) and Information Join (Medidata’s information resolution for buying, reworking, and exchanging digital well being file (EHR) information throughout healthcare organizations), Medidata launched a brand new world of information discovery, evaluation, and integration to the life sciences business powered by open supply applied sciences and hosted on AWS. The next diagram illustrates the answer structure.
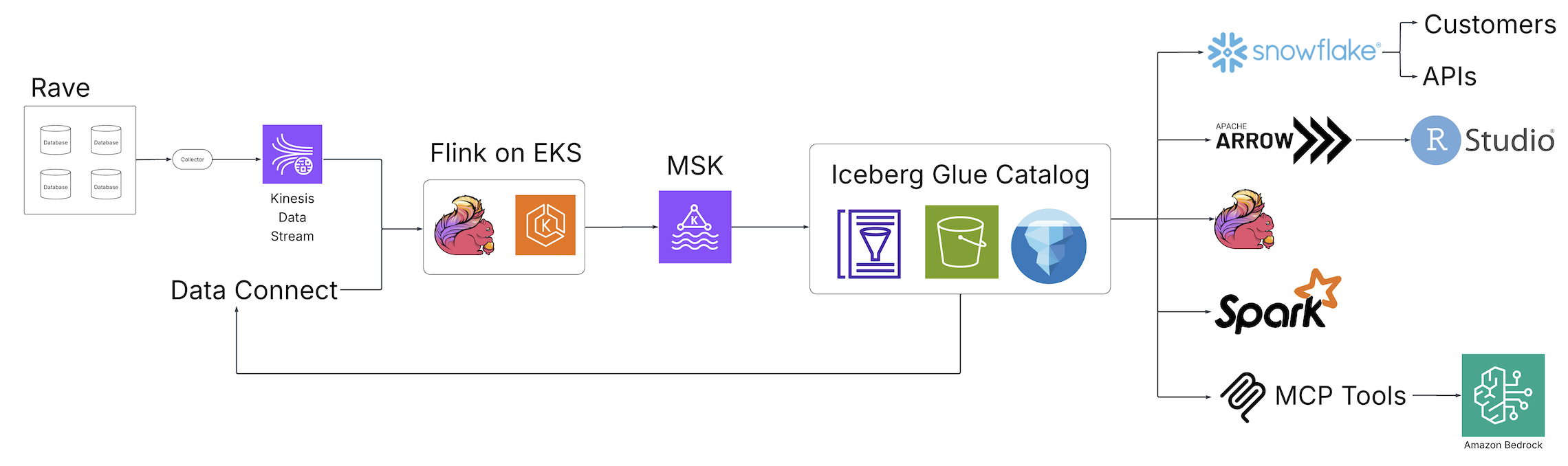
Fragmented batch ETL jobs had been changed by real-time Apache Flink streaming pipelines, an open supply, distributed engine for stateful processing, and powered by Amazon Elastic Kubernetes Service (Amazon EKS), a totally managed Kubernetes service. The Flink jobs write to Apache Kafka working in Amazon Managed Apache Kafka (Amazon MSK), a streaming information service that manages Kafka infrastructure and operations, earlier than touchdown in Iceberg tables backed by the AWS Glue Information Catalog, a centralized metadata repository for information property. From this assortment of Iceberg tables, a central, single supply of information is now accessible from quite a lot of customers with out extra downstream processing, assuaging the necessity for customized pipelines to fulfill the necessities of downstream customers. Via these elementary architectural adjustments, the staff at Medidata solved the problems offered by the legacy resolution.
Information availability and consistency
With the introduction of the Flink jobs and Iceberg tables, the staff was capable of ship a constant view of their information throughout the Medidata information expertise. Pipeline latency was decreased from days to minutes, serving to Medidata clients understand a 99% efficiency acquire from the information ingestion to the information analytics layers. On account of Iceberg’s interoperability, Medidata customers noticed the identical view of the information no matter the place they seen that information, minimizing the necessity for consumer-driven customized pipelines as a result of Iceberg might plug into current customers.
Upkeep and sturdiness
Iceberg’s interoperability offered a single copy of the information to fulfill their use instances, so the Medidata staff might focus its commentary and upkeep efforts on a five-times smaller subset of operations than beforehand required. Observability was enhanced by tapping into the assorted metadata elements and metrics uncovered by Iceberg and the Information Catalog. High quality administration remodeled from cross-system traces and queries to a single evaluation of unified pipelines, with an added good thing about time limit information queries because of the Iceberg snapshot characteristic. Information quantity will increase are dealt with with out-of-box scaling supported by the complete infrastructure stack and AWS Glue Iceberg optimization options that embody compaction, snapshot retention, and orphan file deletion, which offer a set-and-forget expertise for fixing a lot of widespread Iceberg frustrations, such because the small file drawback, orphan file retention, and question efficiency.
Safety
With Iceberg on the middle of its resolution structure, the Medidata staff not needed to spend the time constructing customized entry management layers with enhanced security measures at every information integration level. Iceberg on AWS centralizes the authorization layer utilizing acquainted programs resembling AWS Identification and Entry Administration (IAM), offering a single and sturdy management for information entry. The info additionally stays fully inside the Medidata digital personal cloud (VPC), additional lowering the chance for unintended disclosures.
Conclusion
On this put up, we demonstrated how legacy universe of consumer-driven customized ETL pipelines may be changed with a scalable, high-performant streaming lakehouses. By placing Iceberg on AWS on the middle of information operations, you possibly can have a single supply of information on your customers.
To study extra about Iceberg on AWS, seek advice from Optimizing Iceberg tables and Utilizing Apache Iceberg on AWS.
In regards to the authors