

{kind=link}
Two new Qwen fashions got here out not too long ago – the Qwen3-4B-Instruct-2507 and Qwen3-4B-Considering-2507. Each Qwen3 fashions have context size of 256K, and realizing this, I believed to myself, “Why not make a RAG to make good use of the context size?”. It’s price mentioning that the Qwen3 household has a big number of fashions meant for coding, pondering, embedding, and reranking. Right here, to make our RAG in the very best method, we are going to use Qwen3’s embedding mannequin and reranker mannequin.
Don’t fear, we gained’t begin off by constructing the RAG! We’ll first individually take a look at these fashions after which construct the RAG.
Qwen3 fashions: Background
Developed by Alibaba Cloud, a number of Qwen3 fashions have been launched a couple of months again. As an enchancment to those fashions, two new fashions, Qwen3-Instruct-2507 and Qwen3-Considering-2507, have been not too long ago launched in three sizes: 235B-A22B, 30B-A3B, and 4B. Word that we’ll be primarily specializing in the ‘Qwen3-Instruct-2507’ 4B variant for this text. All these fashions are open-source and are available on Hugging Face and Kaggle. It’s additionally price mentioning that the Qwen3 fashions have multilingual assist, extra particularly, 119 languages and dialects. Let’s see a couple of of the Qwen3 fashions in motion, and later construct the RAG we’re right here for.
Qwen3 Fashions Demo
Let’s begin with the textual content era mannequin, however earlier than that, ensure to get your Hugging Face entry token from right here.
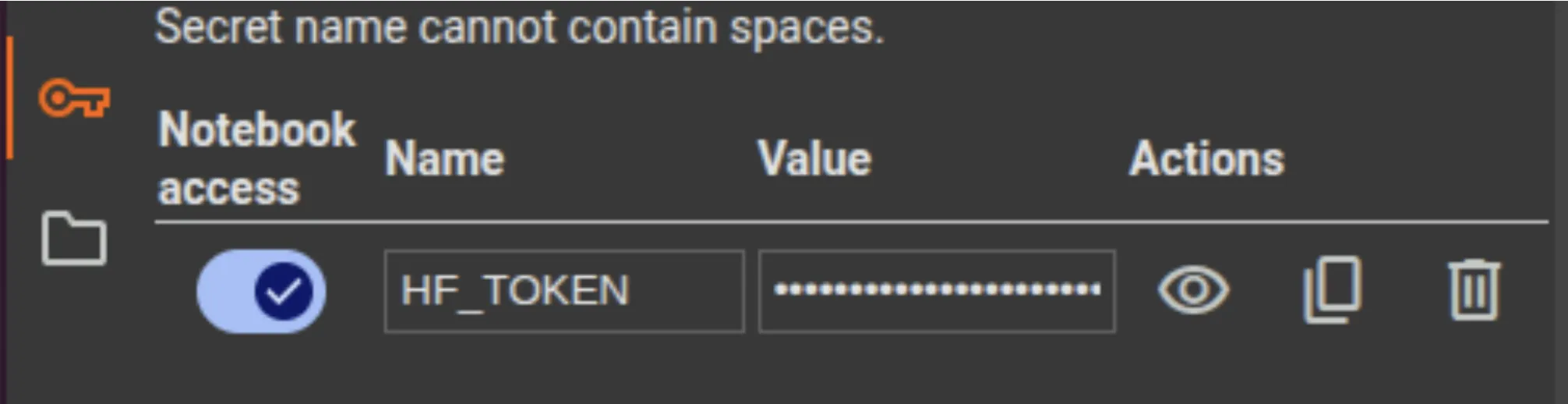
Word: We’ll be doing this demo on Google Colab. After opening a brand new pocket book, ensure so as to add the entry token as HF_TOKEN within the secrets and techniques tab on the left. Be sure to activate entry to the pocket book.
Qwen3-4B-Instruct-2507
That is an up to date model of the Qwen3-4B non-thinking mode and has a meaty context size of 256k. As you may inform from the identify itself, this mannequin has 4 billion parameters, which is comparatively gentle and appropriate to make use of on Colab. Let’s hearth up this mannequin utilizing Hugging Face transformers and see it in motion.
Word: Change the runtime kind to T4 GPU to deal with the mannequin.
# Setup and Dependencies
import torch
import torch.nn.purposeful as F
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoModel# Instruct Mannequin (Textual content Era)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-4B-Instruct-2507")
mannequin = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B-Instruct-2507",
torch_dtype="auto",
device_map="auto"
)
immediate = "Clarify what machine studying is in easy phrases."
messages = [{"role": "user", "content": prompt}]
textual content = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(mannequin.system)
generated_ids = mannequin.generate(
**model_inputs,
max_new_tokens=256
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
response = tokenizer.decode(output_ids, skip_special_tokens=True)
print(response)Right here’s the output I acquired for my query on “Clarify what machine studying is in easy phrases.” :
Positive! In easy phrases, **machine studying** is a method for computer systems to study from information and enhance at doing duties with out being explicitly programmed to take action.
Think about you could have a robotic that learns to acknowledge cats in pictures. As a substitute of writing step-by-step directions like "search for a spherical face, massive eyes, and a nostril," you simply present it many photos of cats and photos of canine. Over time, the robotic begins to determine what makes a cat completely different from a canine — it learns by itself by way of examples.
That’s machine studying: the pc seems to be at information (like photos, numbers, or textual content), finds patterns, and will get higher at making predictions or choices based mostly on these patterns.
Consider it like how a toddler learns to determine completely different animals by seeing them time and again. The machine does one thing related — it learns from expertise (information) and will get smarter with time.
So, in brief:
**Machine studying = instructing computer systems to study from information and enhance on their very own.** 😊Qwen3-Embedding-0.6B
That is an embedding mannequin used to transform textual content to dense vector representations to grasp the connection between texts. That is a necessary a part of the RAG that we’ll be constructing later. The embedding mannequin types the center of the Retriever in Retrieval Augmented Era (RAG).
Let’s outline a perform for reusability and discover the embedding to search out the similarity between the texts. I’m passing 4 strings (textual content) within the ‘texts’ checklist.
# Qwen3-Embedding-0.6B (Textual content Embeddings)
def last_token_pool(last_hidden_states, attention_mask):
left_padding = (attention_mask[:, -1].sum() == attention_mask.form[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.form[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-0.6B', padding_side="left")
mannequin = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B')
texts = [
"Machine learning is a subset of artificial intelligence.",
"Python is a popular programming language.",
"The weather is sunny today.",
"Artificial intelligence is transforming industries."
]
batch_dict = tokenizer(
texts,
padding=True,
truncation=True,
max_length=8192,
return_tensors="pt",
)
outputs = mannequin(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings @ embeddings.T)
print(scores.tolist())Output:
[[1.0, 0.4834885597229004, 0.3609130382537842, 0.6805511713027954], [0.4834885597229004, 1.0000001192092896, 0.44289979338645935, 0.4494439363479614], [0.3609130382537842, 0.44289979338645935, 1.0000001192092896, 0.4508340656757355], [0.6805511713027954, 0.4494439363479614, 0.4508340656757355, 1.0]]This can be a matrix we calculated by discovering the similarity scores of texts with one another. Let’s simply take a look at the first row of the matrix for simpler understanding. As you may see, the similarity of the identical texts is all the time 1, the subsequent instant highest is 0.68, which is between a sentence about AI and a sentence about ML, and the similarity between a press release about climate and AI just isn’t very excessive, which is sensible.
Qwen3-Reranker-0.6B
We will go the retrieved chunks that may be obtained by vector search utilizing the embedding mannequin. The reranker mannequin scores every chunk towards the question to order the checklist of paperwork and assign precedence, or use these scores to subset the retrieved chunks. We’ll see this mannequin instantly in motion within the upcoming part for higher understanding.
Constructing A RAG utilizing the Qwen fashions
We’ll construct a RAG on Analytics Vidhya Blogs (~ 40 blogs) utilizing the three specified Qwen3 fashions. We’ll sequentially course of the information and use the fashions. For environment friendly processing, we’ll be loading/unloading the mannequin for utilization to protect reminiscence. Let’s take a look at the steps and dive into the script.
- Step 1: Obtain the information. Right here’s the hyperlink to my repository the place you could find the information and the scripts.
- Step 2: Set up the necessities:
!pip set up faiss-cpu PyPDF2 - Step 3: Unzip the information right into a folder:
!unzip Information.zip - Step 4: For simpler execution, you may simply add the qwen_rag.py script within the Colab setting and run the script utilizing:
!python qwen_rag.py
Breaking down the script:
- We’re utilizing the PYPDF2 library to load the content material of the articles in PDF format. A perform is outlined to learn weblog content material in .txt or .pdf codecs.
- We’re chunking the content material into chunks of measurement 800 and an overlap of 100 to keep up context relevancy in consecutive paperwork.
- We’re utilizing FAISS to create a vector retailer, and with the assistance of our question, we’re retrieving top-15 paperwork based mostly on similarity.
- Now we use the reranker on these 15 paperwork to get the top-3 by utilizing this perform:
def rerank_documents(question, candidates, k_rerank=3):
"""Rerank paperwork utilizing reranker mannequin"""
print("Reranking paperwork...")
tokenizer, mannequin = load_reranker_model()
# Put together inputs
pairs = []
for doc, _ in candidates:
pair = f": Given an internet search question, retrieve related passages that reply the queryn: {question}n: {doc['content']}"
pairs.append(pair)
# Tokenize
inputs = tokenizer(pairs, padding=True, truncation=True, max_length=8192, return_tensors="pt").to(system)
# Get scores
with torch.no_grad():
outputs = mannequin(**inputs)
logits = outputs.logits[:, -1, :]
# Get sure/no token scores
token_false_id = tokenizer.convert_tokens_to_ids("no")
token_true_id = tokenizer.convert_tokens_to_ids("sure")
true_scores = logits[:, token_true_id]
false_scores = logits[:, token_false_id]
batch_scores = torch.stack([false_scores, true_scores], dim=1)
batch_scores = torch.nn.purposeful.log_softmax(batch_scores, dim=1)
scores = batch_scores[:, 1].exp().tolist()
# Unload reranker mannequin
del tokenizer, mannequin
clear_memory()
print("Reranker mannequin unloaded")
# Kind by rating
paperwork = [doc for doc, _ in candidates]
doc_scores = checklist(zip(paperwork, scores))
doc_scores.kind(key=lambda x: x[1], reverse=True)
return doc_scores[:k_rerank] - As soon as we’ve got these 3 prime paperwork, we go them to the instruct mannequin to get our last output from the Retrieval Augmented Generator.
Output:
Query: What's the distinction between LoRA and QLoRA?
Reply: LoRA (Low-Rank Adaptation) and QLoRA (Quantized Low-Rank Adaptation) are each parameter-efficient fine-tuning methods used to adapt giant language fashions (LLMs) to particular duties. Whereas they share similarities, they differ of their method and effectivity.
1. **LoRA (Low-Rank Adaptation)**:
- LoRA introduces low-rank matrices (A and B) into the self-attention module of every layer within the pre-trained mannequin. These matrices act as adapters that enable the mannequin to adapt and specialize for particular duties whereas minimizing the variety of further parameters wanted.
- LoRA reduces parameter overhead by specializing in optimizing trainable low-rank matrices as an alternative of fine-tuning all parameters. This makes it rather more memory-efficient and computationally cheaper.
- LoRA permits the pre-trained mannequin to be shared throughout a number of duties, facilitating environment friendly task-switching throughout deployment.
- LoRA doesn't introduce any further inference latency in comparison with totally fine-tuned fashions, making it appropriate for real-time functions.
2. **QLoRA (Quantized Low-Rank Adaptation)**:
- QLoRA is an extension of LoRA that additional introduces quantization to reinforce parameter effectivity throughout fine-tuning. It builds on the ideas of LoRA whereas introducing 4-bit NormalFloat (NF4) quantization and Double Quantization methods.
- NF4 quantization leverages the inherent distribution of pre-trained neural community weights, remodeling all weights to a set distribution that matches inside the vary of NF4 (-1 to 1). This permits for efficient quantization with out the necessity for costly quantile estimation algorithms.
- Double Quantization addresses the reminiscence overhead of quantization constants by quantizing the quantization constants themselves. This considerably reduces the reminiscence footprint with out compromising efficiency.
- QLoRA achieves even greater reminiscence effectivity by introducing quantization, making it notably invaluable for deploying giant fashions on resource-constrained gadgets.
- Regardless of its parameter-efficient nature, QLoRA retains excessive mannequin high quality, acting on par and even higher than totally fine-tuned fashions on varied downstream duties.
In abstract, whereas LoRA focuses on lowering the variety of trainable parameters by way of low-rank adaptation, QLoRA additional enhances this effectivity by incorporating quantization methods, making it extra appropriate for deployment on gadgets with restricted computational sources.
Sources: fine_tuning.txt, Parameter-Environment friendly Superb-Tuning of Giant Language Fashions with LoRA and QLoRA.pdf, Parameter-Environment friendly Superb-Tuning of Giant Language Fashions with LoRA and QLoRA.pdfWord: You’ll be able to consult with the log file ‘rag_retrieval_log.txt’ to get extra details about the paperwork retrieved and the similarity rating with the question and the reranker scores.
Conclusion
By combining Qwen3’s instruct, embedding, and reranker fashions, we’ve constructed a sensible RAG pipeline that makes full use of their strengths. With 256K context size and multilingual assist, the Qwen household proves versatile for real-world duties. For subsequent steps, you can strive rising the paperwork handed to the instruct mannequin or use a pondering mannequin for a special use case. The outputs additionally appear promising. I recommend you strive evaluating the RAG on metrics like Faithfulness and Reply Relevancy to make sure the LLM is generally freed from hallucinations in your process/use-case.
Incessantly Requested Questions
Chunking is the method of splitting giant textual content into smaller overlapping segments to keep up context whereas enabling environment friendly retrieval.
A vector retailer is a database that shops textual content embeddings for quick similarity search and retrieval.
You’ll be able to consider a RAG utilizing metrics like accuracy, relevance, and response consistency throughout completely different queries.
It is determined by your context size restrict; sometimes, 3–5 top-ranked paperwork work properly.
A reranker scores retrieved paperwork towards a question to reorder them by relevance earlier than passing to the LLM.
Keen about know-how and innovation, a graduate of Vellore Institute of Know-how. Presently working as a Information Science Trainee, specializing in Information Science. Deeply fascinated with Deep Studying and Generative AI, desirous to discover cutting-edge methods to resolve advanced issues and create impactful options.
Login to proceed studying and luxuriate in expert-curated content material.