

{kind=link}
Amazon EMR Serverless is a deployment possibility for Amazon EMR that you should use to run open supply huge knowledge analytics frameworks equivalent to Apache Spark and Apache Hive with out having to configure, handle, or scale clusters and servers. EMR Serverless integrates with Amazon Net Companies (AWS) providers throughout knowledge storage, streaming, orchestration, monitoring, and governance to offer a complete serverless analytics answer.
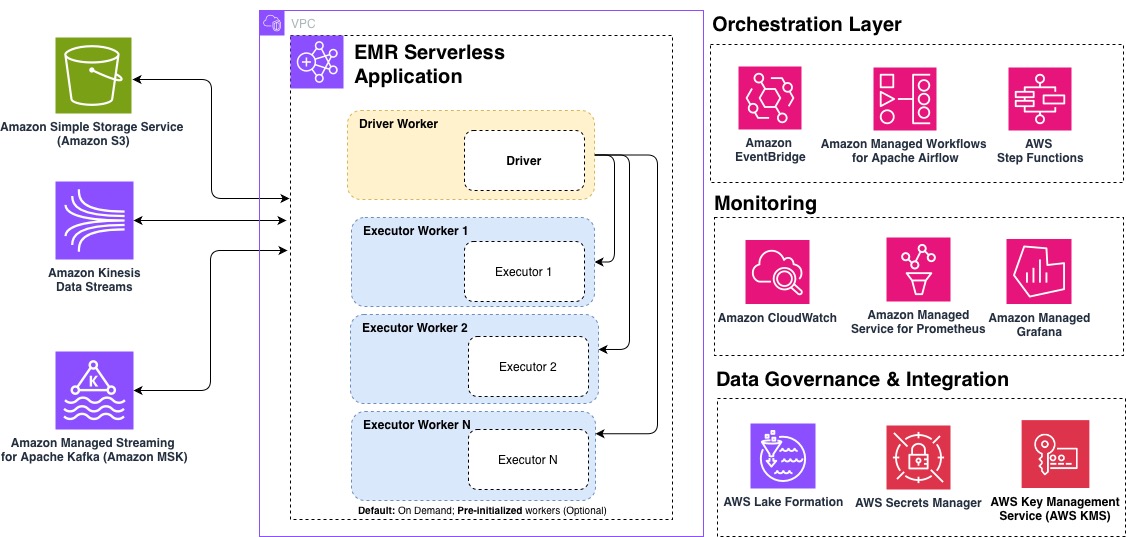
On this put up, we share the highest 10 finest practices for optimizing your EMR Serverless workloads for efficiency, price, and scalability. Whether or not you’re getting began with EMR Serverless or trying to fine-tune present manufacturing workloads, these suggestions will aid you construct environment friendly, cost-effective knowledge processing pipelines. The next diagram illustrates an end-to-end EMR Serverless structure, displaying the way it integrates into your analytics pipelines.
1. Outline purposes one time, reuse a number of occasions
EMR Serverless purposes perform as cluster templates that instantiate when jobs are submitted and may course of a number of jobs with out being recreated. This design considerably reduces startup latency for recurring workloads and simplifies operational administration.
Typical workflow for EMR on EC2 transient cluster:

Typical workflow for EMR Serverless:

Functions characteristic a self-managing lifecycle that provisions sources to be out there when wanted with out handbook intervention. They routinely provision capability when a job is submitted. For purposes with out pre-initialized capability, sources are launched instantly after job completion. For purposes with pre-initialized capability configured, these pre-initialized employees will cease after exceeding the configured idle timeout (quarter-hour by default). You’ll be able to alter this timeout on the software stage utilizing AutoStopConfig configuration within the CreateApplication or UpdateApplication API. For instance, in case your jobs run each half-hour, rising the idle timeout can remove startup delays between executions.
Most workloads are suited to on-demand capability provisioning, which routinely scales sources based mostly in your job necessities with out incurring fees when idle. This method is cost-effective and appropriate for typical use instances together with extract, remodel, and cargo (ETL) workloads, batch processing jobs, and situations requiring most job resiliency.
For particular workloads with strict instant-start necessities, you may optionally configure pre-initialized capability. Pre-initialized capability creates a heat pool of drivers and executors which might be able to run jobs inside seconds. Nonetheless, this efficiency benefit comes with a tradeoff of added price as a result of pre-initialized employees incur steady fees even when idle till the applying reaches the Stopped state. Moreover, pre-initialized capability restricts jobs to a single Availability Zone, which reduces resiliency.
Pre-initialized capability ought to solely be thought-about for:
- Time-sensitive jobs with sub second service stage settlement (SLA) necessities the place startup latency is unacceptable
- Interactive analytics the place consumer expertise relies on instantaneous response
- Excessive-frequency manufacturing pipelines operating each jiffy
In most different instances, on-demand capability offers the most effective steadiness of price, efficiency, and resiliency.
Past optimizing your purposes’ use of sources, contemplate the way you set up them throughout your workloads. For manufacturing workloads, use separate purposes for various enterprise domains or knowledge sensitivity ranges. This isolation improves governance and prevents useful resource rivalry between vital and noncritical jobs.
Deciding on the appropriate underlying processor structure can considerably influence each efficiency and value. Graviton ARM-based processors provide vital efficiency enchancment in comparison with x86_64.
EMR Serverless routinely updates to the most recent occasion generations as they turn out to be out there, which suggests your purposes profit from the most recent {hardware} enhancements with out requiring further configuration.
To make use of Graviton with EMR Serverless, specify ARM64 with the structure parameter throughout software creation utilizing the CreateApplication or with the UpdateApplication API for present purposes:
Issues when utilizing Graviton:
- Useful resource availability – For big-scale workloads, contemplate partaking along with your AWS account staff to debate capability planning for Graviton employees.
- Compatibility – Though many generally used and normal libraries are suitable with Graviton (arm64) structure, you’ll need to validate that third-party packages and libraries used are suitable.
- Migration planning – Take a strategic method to Graviton adoption. Construct new purposes on ARM64 structure by default and migrate present workloads by way of a phased transition plan that minimizes disruption. This structured method will assist optimize price and efficiency with out compromising reliability.
- Carry out benchmarks – It’s necessary to notice that actual worth efficiency will differ by workload. We advocate performing your individual benchmarks to gauge particular outcomes in your workload. For extra particulars, consult with Obtain as much as 27% higher price-performance for Spark workloads with AWS Graviton2 on Amazon EMR Serverless.
3. Use defaults, right-size employees if wanted
Employees are used to execute the duties in your workload. Whereas EMR Serverless defaults are optimized out of the field for a majority of use instances, it’s possible you’ll have to right-size your employees to enhance processing time and optimize price effectivity. When submitting EMR Serverless jobs, it’s really useful to outline Spark properties to configure employees, together with reminiscence dimension (in GB) and variety of cores.
EMR Serverless configures the default employee dimension of 4 vCPUs, 16 GB reminiscence, and 20 GB disk. Though this typically offers a balanced configuration for many jobs, you would possibly wish to alter the dimensions based mostly in your efficiency necessities. Even when configuring pre-initialized employees with particular sizing, at all times set your Spark properties at job submission. This permits your job to make use of the desired employee sizing slightly than default properties when it scales past pre-initialized capability. When right-sizing your Spark workload, it’s necessary to establish the vCPU:reminiscence ratio in your job. This ratio determines how a lot reminiscence you allocate per digital CPU core in your executors. Spark executors want each CPU and reminiscence to course of knowledge successfully, and the optimum ratio varies based mostly in your workload traits.
To get began, use the next steerage, then refine your configuration based mostly in your particular workload necessities.
Executor configuration
The next desk offers really useful executor configurations based mostly on widespread workload patterns:
| Workload kind | Ratio | CPU | Reminiscence | Configuration |
|---|---|---|---|---|
| Compute intensive | 1:2 | 16 vCPU | 32 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.reminiscence=32G |
| Common objective | 1:4 | 16 vCPU | 64 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.reminiscence=64G |
| Reminiscence intensive | 1:8 | 16 vCPU | 108 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.reminiscence=108G |
Driver configuration
The next desk offers really useful driver configurations based mostly on widespread workload patterns:
| Workload kind | Ratio | CPU | Reminiscence | Configuration |
|---|---|---|---|---|
| Common objective | 1:4 | 4 vCPU | 16 GB | spark.emr-serverless.driver.cores=4spark.emr-serverless.driver.reminiscence=16G |
| Apache Iceberg workloads | 1:8(Giant driver for metadata lookups) | 8 vCPU | 60 GB | spark.emr-serverless.driver.cores=8spark.emr-serverless.driver.reminiscence=60G |
To additional monitor and tune your configuration, monitor your workload’s useful resource consumption utilizing Amazon CloudWatch job worker-level metrics to establish constraints. Monitor CPU utilization, reminiscence utilization, and disk utilization metrics, then use the next desk to fine-tune your configuration based mostly on noticed bottlenecks.
| Metrics noticed | Workload kind | Prompt motion | |
| 1 | Excessive reminiscence (>90%), Low CPU (<50%) | Reminiscence-bound workload | Improve vCPU:reminiscence ratio |
| 2 | Excessive CPU (>85%), low reminiscence (<60%) | CPU-bound workload | Improve vCPU rely, keep 1:4 ratio (For instance, if utilizing 8 vCPU, use 32 GB reminiscence) |
| 3 | Excessive storage I/O, regular CPU or reminiscence with lengthy shuffle operations | Shuffle-intensive | Allow serverless storage or shuffle-optimized disks |
| 4 | Low utilization throughout metrics | Over-provisioned | Scale back employee dimension or rely |
| 5 | Constant excessive utilization (>90%) | Underneath-provisioned | Scale up employee specs |
| 6 | Frequent GC pauses** | Reminiscence stress | Improve reminiscence overhead (10 –15%) |
**You’ll be able to establish frequent rubbish gather (GC) pauses utilizing the Spark UI below the Executors tab. There will likely be a GC time column that ought to typically be lower than 10% of process time. Alternatively, the driving force logs would possibly steadily comprise GC (Allocation Failure)] messages.
4. Management scaling boundary with T-shirt sizing
By default, EMR Serverless makes use of dynamic useful resource allocation (DRA), which routinely scales sources based mostly on workload demand. EMR Serverless constantly evaluates metrics from the job to optimize for price and pace, eradicating the necessity so that you can estimate the precise variety of employees required.
For price optimization and predictable efficiency, you may configure an higher scaling boundary utilizing one of many following approaches:
- Setting the spark.dynamicAllocation.maxExecutors parameter on the job stage
- Setting the application-level most capability
Somewhat than making an attempt to fine-tune spark.dynamicAllocation.maxExecutors to an arbitrary worth for every job, you may take into consideration setting this configuration as t-shirt sizes that signify totally different workload profiles:
| Workload dimension | Use instances | spark.dynamicAllocation.maxExecutors |
|---|---|---|
| Small | Exploratory queries, growth | 50 |
| Medium | Common ETL jobs, studies | 200 |
| Giant | Advanced transformations, large-scale processing | 500 |
This t-shirt sizing method simplifies capability planning and helps you steadiness efficiency with price effectivity based mostly in your workload class, slightly than making an attempt to optimize every particular person job.
For EMR Serverless releases 6.10 and above, the default worth for spark.dynamicAllocation.maxExecutors is infinity, however for earlier releases, it’s 100.
EMR Serverless routinely scales employees up or down based mostly on the workload and parallelism required at each stage of the job. This computerized scaling is constantly evaluating metrics from the job to optimize for price and pace, which removes the necessity so that you can estimate the variety of employees that the applying must run your workloads.
Nonetheless, in some instances, you probably have a predictable workload, you would possibly wish to statically set the variety of executors. To take action, you may disable DRA and specify the variety of executors manually:
5. Provision applicable storage for EMR Serverless jobs
Understanding your storage choices and sizing them appropriately can stop job failures and optimize execution occasions. EMR Serverless gives a number of storage choices to deal with intermediate knowledge throughout job execution. The storage possibility chosen will depend upon the EMR launch and use case. The storage choices out there in EMR Serverless are:
| Storage kind | EMR launch | Disk dimension vary | Use case | Advantages |
|---|---|---|---|---|
| Serverless Storage (really useful) | 7.12+ | N/A (auto-scaling) | Most Spark workloads, particularly data-intensive workloads |
|
| Normal Disks | 7.11 and decrease | 20–200 GB per employee | Small to medium workloads processing datasets below 10 TB |
|
| Shuffle-Optimized Disks | 7.1.0+ | 20–2,000 GB per employee | Giant-scale ETL workloads processing multi-TB |
|
By matching your storage configuration to your workload traits, you’ll allow EMR Serverless jobs to run effectively and reliably at scale.
6. Multi-AZ out-of-the-box with built-in resiliency
EMR Serverless purposes are multi-AZ from the beginning when pre-initialized capability isn’t enabled. This built-in failover functionality offers resilience towards Availability Zone disruptions with out handbook intervention. A single job will function inside a single Availability Zone to forestall cross-AZ knowledge switch prices and subsequent jobs will likely be intelligently distributed throughout a number of AZs. If EMR Serverless determines that an AZ is impaired, it is going to submit new jobs to a wholesome AZ, enabling your workloads to proceed operating regardless of AZ impairment.
To totally profit from EMR Serverless multi-AZ performance confirm the next:
- Configure a community connection to your VPC with a number of subnets throughout Availability Zones chosen
- Keep away from pre-initialized capability which restricts purposes to a single AZ
- Ensure that there are adequate IP addresses out there in every subnet to help the scaling of employees
Along with multi-AZ, with Amazon EMR 7.1 and better, you may allow job resiliency, which permits your jobs to be routinely retried in case errors are encountered. If there are a number of Availability Zones configured, it is going to even be retried in a special AZ. You’ll be able to allow this characteristic for each batch and streaming jobs, although retry conduct differs between the 2.
Configure job resiliency by specifying a retry coverage that defines the utmost variety of retry makes an attempt. For batch jobs, the default isn’t any computerized retries (maxAttempts=1). For streaming jobs, EMR Serverless retries indefinitely with built-in thrash prevention that stops retries after 5 failed makes an attempt inside 1 hour. You’ll be able to configure this threshold between 1–10 makes an attempt. For extra info, consult with Job resiliency.
Within the occasion that you’ll want to cancel your job, you may specify a grace interval to permit your jobs to close down cleanly slightly than the default conduct of quick termination. This will additionally embrace customized shutdown hooks if you’ll want to carry out customized cleanup actions.
By combining multi-AZ help, computerized job retries, and swish shutdown durations, you create a strong basis for EMR Serverless workloads that may tolerate interruptions and keep knowledge integrity with out handbook intervention.
7. Safe and prolong connectivity with VPC integration
By default, EMR Serverless can entry AWS providers equivalent to Amazon Easy Storage Service (Amazon S3), AWS Glue, Amazon CloudWatch Logs, AWS Key Administration Service (AWS KMS), AWS Safety Token Service (AWS STS), Amazon DynamoDB, and AWS Secrets and techniques Supervisor. If you wish to hook up with knowledge shops inside your VPC, equivalent to Amazon Redshift or Amazon Relational Database Service (Amazon RDS), you should configure VPC entry for the EMR Serverless software.
When configuring VPC entry in your EMR Serverless software, preserve these key concerns in thoughts to achieve optimum efficiency and value effectivity:
- Plan for adequate IP addresses – Every employee makes use of one IP deal with inside a subnet. This contains the employees that will likely be launched when your job is scaling out. If there aren’t sufficient IP addresses, your job won’t have the ability to scale, which may end in job failure. Confirm you’ve gotten adhered to finest practices for subnet planning for optimum efficiency.
- Arrange Gateway endpoints for Amazon S3 for purposes in a personal subnets – Operating EMR Serverless in a personal subnet with out VPC endpoints for Amazon S3 will route your Amazon S3 site visitors by way of NAT gateways, leading to further knowledge switch fees. VPC endpoints for S3 will preserve this site visitors inside your VPC, lowering prices and enhancing efficiency for Amazon S3 operations.
- Handle AWS Config prices for community interfaces – EMR Serverless generates an elastic community interface document in AWS Config for every employee, which might accumulate prices as your workloads scale. In the event you don’t require AWS Config monitoring for EMR Serverless community interfaces, think about using resource-based exclusions or tagging methods to filter them out whereas sustaining AWS Config protection for different sources.
For extra particulars, refer Configuring VPC entry for EMR Serverless purposes.
8. Simplify job submission and dependency administration
EMR Serverless helps versatile job submission by way of the StartJobRun API, which accepts the complete spark-submit syntax. For runtime atmosphere configuration, use the spark.emr-serverless.driverEnv and spark.executorEnv prefixes to set atmosphere variables for driver and executor processes. That is significantly helpful for passing delicate configuration or runtime-specific settings.
For Python purposes, bundle dependencies utilizing digital environments by making a venv, packaging it as a tar.gz archive, or importing to Amazon S3 utilizing spark.archives with the suitable PYSPARK_PYTHON atmosphere variable. This permits Python dependencies to be out there throughout driver and executor employees.
For improved management below excessive load, allow job concurrency and queuing (out there in EMR 7.0.0+) to restrict the variety of jobs that may be executed concurrently. With this characteristic, jobs submitted that exceed the concurrency restrict are queued till sources turn out to be out there.
You’ll be able to configure Job concurrency and queue settings utilizing the SchedulerConfiguration property utilizing the CreateApplication or UpdateApplication API.
--scheduler-configuration '{"maxConcurrentRuns": 5, "queueTimeoutMinutes": 30}'
9. Use EMR Serverless configurations to implement limits
EMR Serverless routinely scales sources based mostly on workload demand, offering optimized defaults that work nicely for many use instances with out requiring Spark configuration tuning. To handle prices successfully, you may configure useful resource limits that align along with your finances and efficiency necessities. For superior use instances, EMR Serverless additionally offers configuration choices so you may fine-tune useful resource consumption and obtain the identical effectivity as cluster-based deployments. Understanding these limits helps you steadiness efficiency with price effectivity in your jobs.
| Restrict kind | Objective | How you can configure |
|---|---|---|
| Job-level | Management sources for particular person jobs | spark.dynamicAllocation.maxExecutors or spark.executor.cases |
| Software-level | Restrict sources per software or enterprise area | Set most capability when creating the applying or whereas updating. |
| Account-level | Stop irregular useful resource spikes throughout all purposes | Auto-adjustable service quota Max concurrent vCPUs per account; request will increase through Service Quotas console |
These three layers of limits work collectively to offer versatile useful resource administration at totally different scopes. For many use instances, configuring job-level limits utilizing the t-shirt sizing method is adequate, whereas software and account-level limits present further guardrails for price management.
10. Monitor with CloudWatch, Prometheus, and Grafana
Monitoring EMR Serverless workloads simplifies the method of debugging, performing price optimization, and efficiency monitoring. EMR Serverless gives three tiers of monitoring that work collectively: Amazon CloudWatch, Amazon Managed Service for Prometheus, and Amazon Managed Grafana.
- Amazon CloudWatch – CloudWatch integration is enabled by default and publishes metrics to the AWS/EMRServerless namespace. EMR Serverless sends metrics to CloudWatch each minute on the software stage, in addition to job, worker-type, and capacity-allocation-type ranges. Utilizing CloudWatch, you may configure dashboards for enhanced observability into workloads or configure alarms to alert for job failures, scaling anomalies, and SLA breaches. Utilizing CloudWatch with EMR Serverless offers insights to your workloads so you may catch points earlier than they influence customers.
- Amazon Managed Service for Prometheus – With EMR Serverless launch 7.1+, you may allow Prometheus for detailed Spark engine metrics to push metrics to Amazon Managed Service for Prometheus. This unlocks executor-level visibility, together with reminiscence utilization, shuffle volumes, and GC stress. You should use this to establish memory-constrained executors, detect shuffle-heavy levels, and discover knowledge skew.
- Amazon Managed Grafana – Grafana connects to each CloudWatch and Prometheus knowledge sources, offering a single pane of glass for unified observability and correlation evaluation. This layered method helps you correlate infrastructure points with application-level efficiency issues.
Key metrics to trace:
- Job completion occasions and success charges
- Employee utilization and scaling occasions
- Shuffle learn/write volumes
- Reminiscence utilization patterns
For extra particulars, consult with Monitor Amazon EMR Serverless employees in close to actual time utilizing Amazon CloudWatch.
Conclusion
On this put up, we shared 10 finest practices that will help you maximize the worth of Amazon EMR Serverless by optimizing efficiency, controlling prices, and sustaining dependable operations at scale. By specializing in software design, right-sized workloads, and architectural selections, you may construct knowledge processing pipelines which might be each environment friendly and resilient.
To be taught extra, consult with the Getting began with EMR Serverless information.
In regards to the Authors