

{kind=link}
TL; DR
The quickest solution to stall an agentic AI undertaking is to reuse a workflow that now not suits. Utilizing syftr, we recognized “silver bullet” flows for each low-latency and high-accuracy priorities that persistently carry out properly throughout a number of datasets. These flows outperform random seeding and switch studying early in optimization. They get better about 75% of the efficiency of a full syftr run at a fraction of the price, which makes them a quick start line however nonetheless leaves room to enhance.
When you have ever tried to reuse an agentic workflow from one undertaking in one other, you understand how typically it falls flat. The mannequin’s context size won’t be sufficient. The brand new use case would possibly require deeper reasoning. Or latency necessities may need modified.
Even when the previous setup works, it might be overbuilt – and overpriced – for the brand new drawback. In these circumstances, an easier, sooner setup may be all you want.
We got down to reply a easy query: Are there agentic flows that carry out properly throughout many use circumstances, so you’ll be able to select one based mostly in your priorities and transfer ahead?
Our analysis suggests the reply is sure, and we name them “silver bullets.”
We recognized silver bullets for each low-latency and high-accuracy objectives. In early optimization, they persistently beat switch studying and random seeding, whereas avoiding the complete price of a full syftr run.
Within the sections that comply with, we clarify how we discovered them and the way they stack up towards different seeding methods.
A fast primer on Pareto-frontiers
You don’t want a math diploma to comply with alongside, however understanding the Pareto-frontier will make the remainder of this put up a lot simpler to comply with.
Determine 1 is an illustrative scatter plot – not from our experiments – exhibiting accomplished syftr optimization trials. Sub-plot A and Sub-plot B are equivalent, however B highlights the primary three Pareto-frontiers: P1 (crimson), P2 (inexperienced), and P3 (blue).

- Every trial: A selected circulate configuration is evaluated on accuracy and common latency (larger accuracy, decrease latency are higher).
- Pareto-frontier (P1): No different circulate has each larger accuracy and decrease latency. These are non-dominated.
- Non-Pareto flows: At the very least one Pareto circulate beats them on each metrics. These are dominated.
- P2, P3: Should you take away P1, P2 turns into the next-best frontier, then P3, and so forth.
You would possibly select between Pareto flows relying in your priorities (e.g., favoring low latency over most accuracy), however there’s no purpose to decide on a dominated circulate — there’s at all times a greater possibility on the frontier.
Optimizing agentic AI flows with syftr
All through our experiments, we used syftr to optimize agentic flows for accuracy and latency.
This method permits you to:
- Choose datasets containing query–reply (QA) pairs
- Outline a search area for circulate parameters
- Set targets equivalent to accuracy and price, or on this case, accuracy and latency
Briefly, syftr automates the exploration of circulate configurations towards your chosen targets.
Determine 2 reveals the high-level syftr structure.
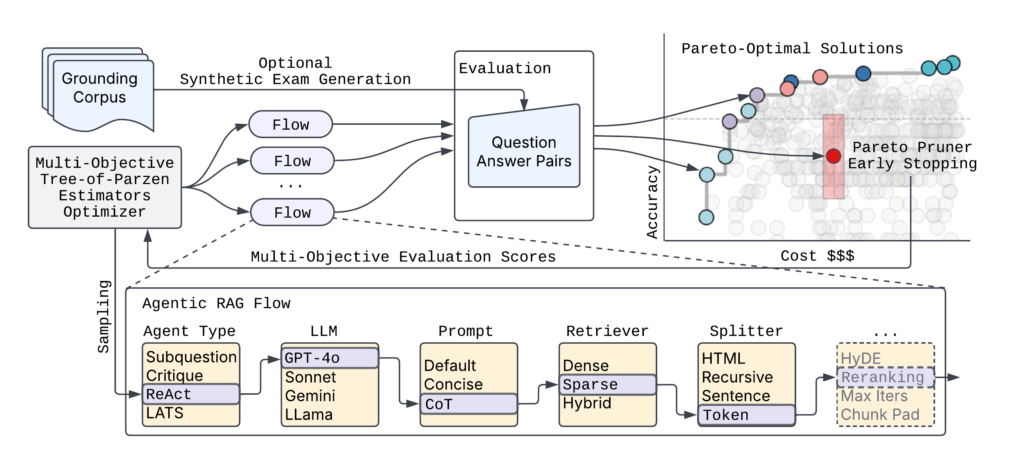
Given the virtually countless variety of doable agentic circulate parametrizations, syftr depends on two key methods:
- Multi-objective Bayesian optimization to navigate the search area effectively.
- ParetoPruner to cease analysis of possible suboptimal flows early, saving time and compute whereas nonetheless surfacing the simplest configurations.
Silver bullet experiments
Our experiments adopted a four-part course of (Determine 3).
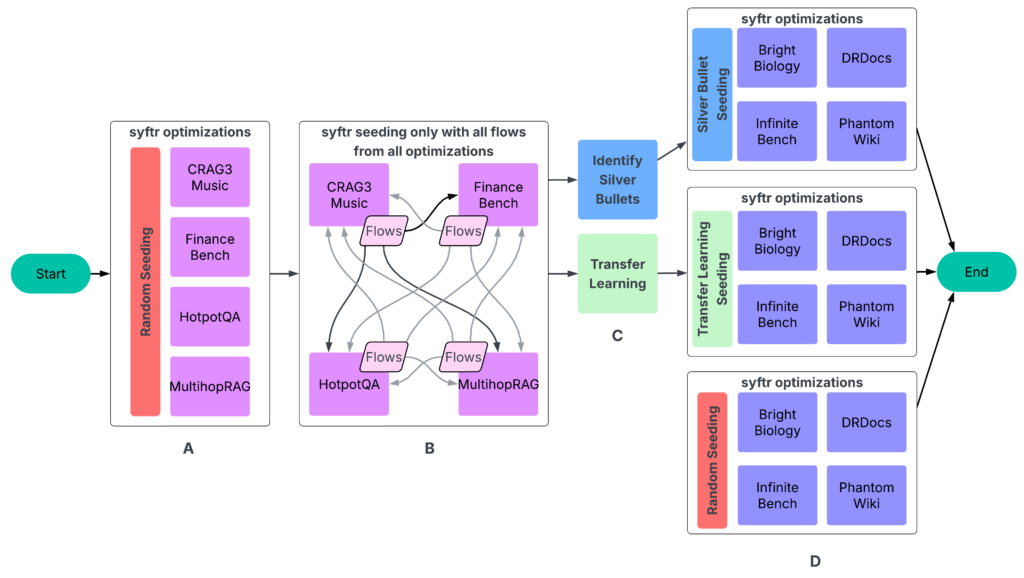
A: Run syftr utilizing easy random sampling for seeding.
B: Run all completed flows on all different experiments. The ensuing information then feeds into the subsequent step.
C: Figuring out silver bullets and conducting switch studying.
D: Working syftr on 4 held-out datasets 3 times, utilizing three completely different seeding methods.
Step 1: Optimize flows per dataset
We ran a number of hundred trials on every of the next datasets:
- CRAG Job 3 Music
- FinanceBench
- HotpotQA
- MultihopRAG
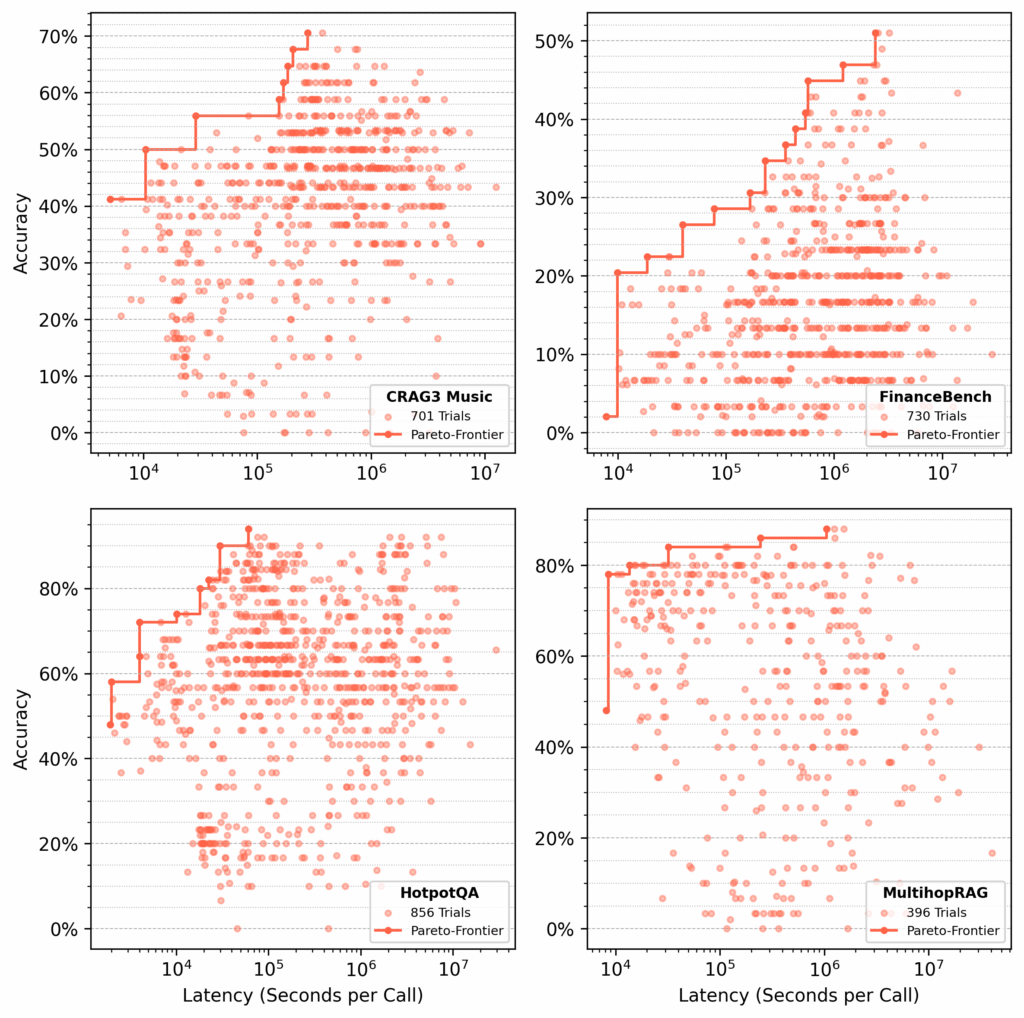
For every dataset, syftr looked for Pareto-optimal flows, optimizing for accuracy and latency (Determine 4).
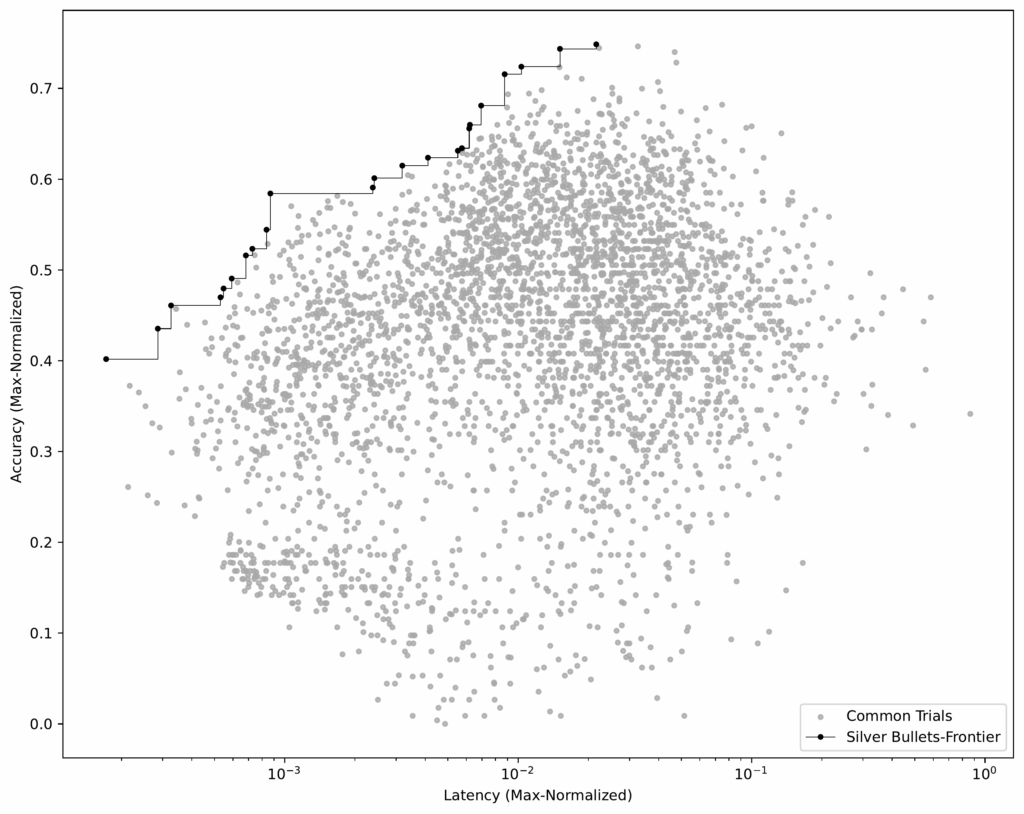
Step 3: Establish silver bullets
As soon as we had equivalent flows throughout all coaching datasets, we might pinpoint the silver bullets — the flows which can be Pareto-optimal on common throughout all datasets.
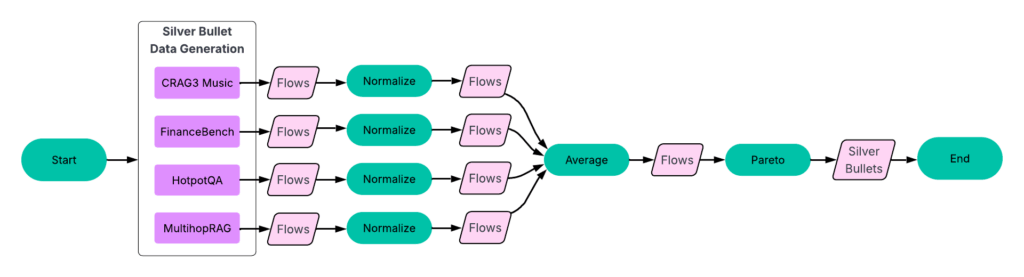
Course of:
- Normalize outcomes per dataset. For every dataset, we normalize accuracy and latency scores by the best values in that dataset.
- Group equivalent flows. We then group matching flows throughout datasets and calculate their common accuracy and latency.
- Establish the Pareto-frontier. Utilizing this averaged dataset (see Determine 6), we choose the flows that construct the Pareto-frontier.
These 23 flows are our silver bullets — those that carry out properly throughout all coaching datasets.
Step 4: Seed with switch studying
In our authentic syftr paper, we explored switch studying as a solution to seed optimizations. Right here, we in contrast it instantly towards silver bullet seeding.
On this context, switch studying merely means deciding on particular high-performing flows from historic (coaching) research and evaluating them on held-out datasets. The information we use right here is similar as for silver bullets (Determine 3).
Course of:
- Choose candidates. From every coaching dataset, we took the top-performing flows from the highest two Pareto-frontiers (P1 and P2).
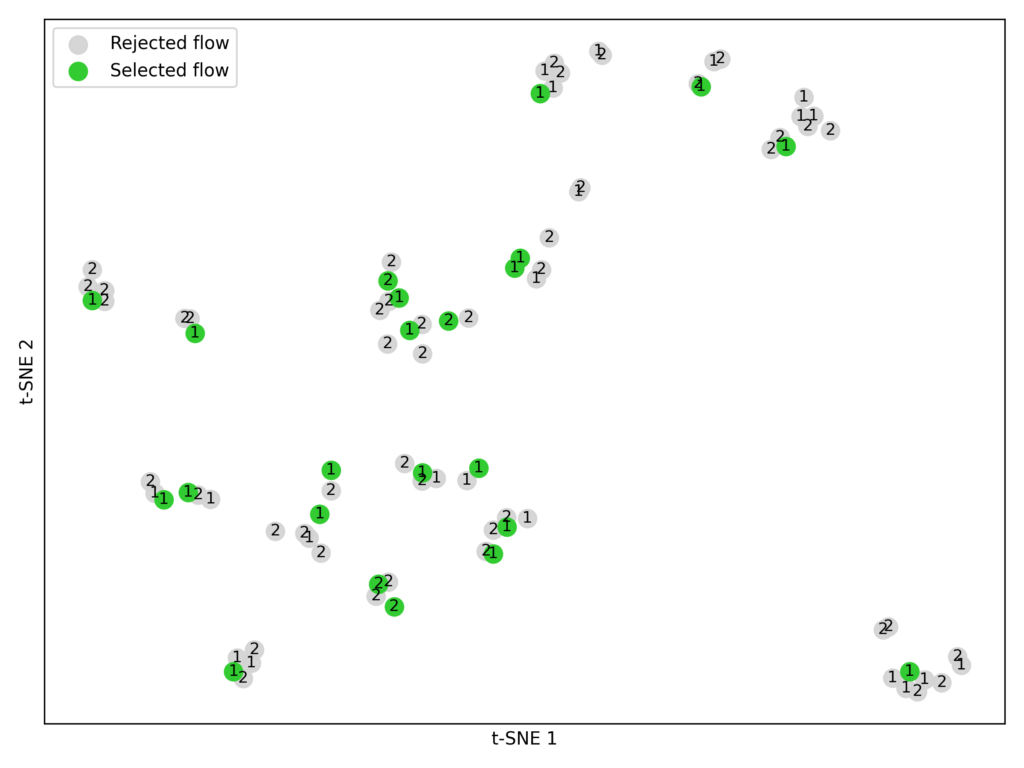
- Embed and cluster. Utilizing the embedding mannequin BAAI/bge-large-en-v1.5, we transformed every circulate’s parameters into numerical vectors. We then utilized Ok-means clustering (Ok = 23) to group related flows (Determine 7).
- Match experiment constraints. We restricted every seeding technique (silver bullets, switch studying, random sampling) to 23 flows for a good comparability, since that’s what number of silver bullets we recognized.
Observe: Switch studying for seeding isn’t but absolutely optimized. We might use extra Pareto-frontiers, choose extra flows, or attempt completely different embedding fashions.
Step 5: Testing all of it
Within the remaining analysis part (Step D in Determine 3), we ran ~1,000 optimization trials on 4 check datasets — Brilliant Biology, DRDocs, InfiniteBench, and PhantomWiki — repeating the method 3 times for every of the next seeding methods:
- Silver bullet seeding
- Switch studying seeding
- Random sampling
For every trial, GPT-4o-mini served because the decide, verifying an agent’s response towards the ground-truth reply.
Outcomes
We got down to reply:
Which seeding method — random sampling, switch studying, or silver bullets — delivers the most effective efficiency for a brand new dataset within the fewest trials?
For every of the 4 held-out check datasets (Brilliant Biology, DRDocs, InfiniteBench, and PhantomWiki), we plotted:
- Accuracy
- Latency
- Price
- Pareto-area: a measure of how shut outcomes are to the optimum outcome
In every plot, the vertical dotted line marks the purpose when all seeding trials have accomplished. After seeding, silver bullets confirmed on common:
- 9% larger most accuracy
- 84% decrease minimal latency
- 28% bigger Pareto-area
in comparison with the opposite methods.
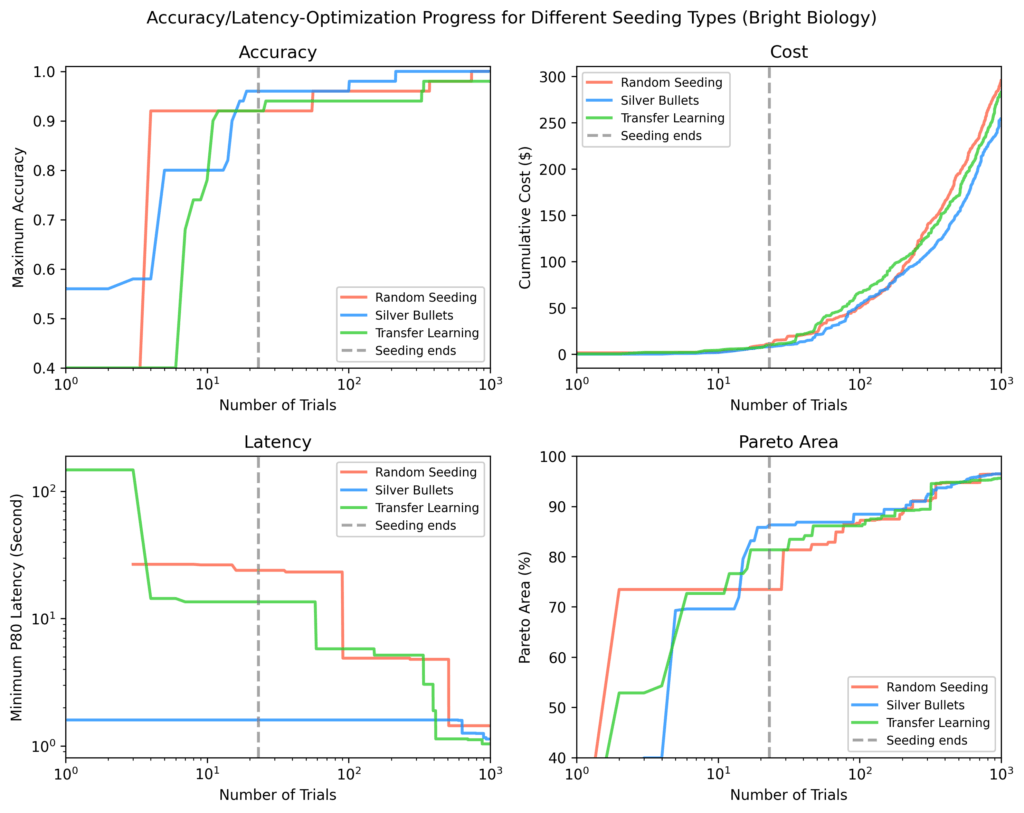
Brilliant Biology
Silver bullets had the best accuracy, lowest latency, and largest Pareto-area after seeding. Some random seeding trials didn’t end. Pareto-areas for all strategies elevated over time however narrowed as optimization progressed.
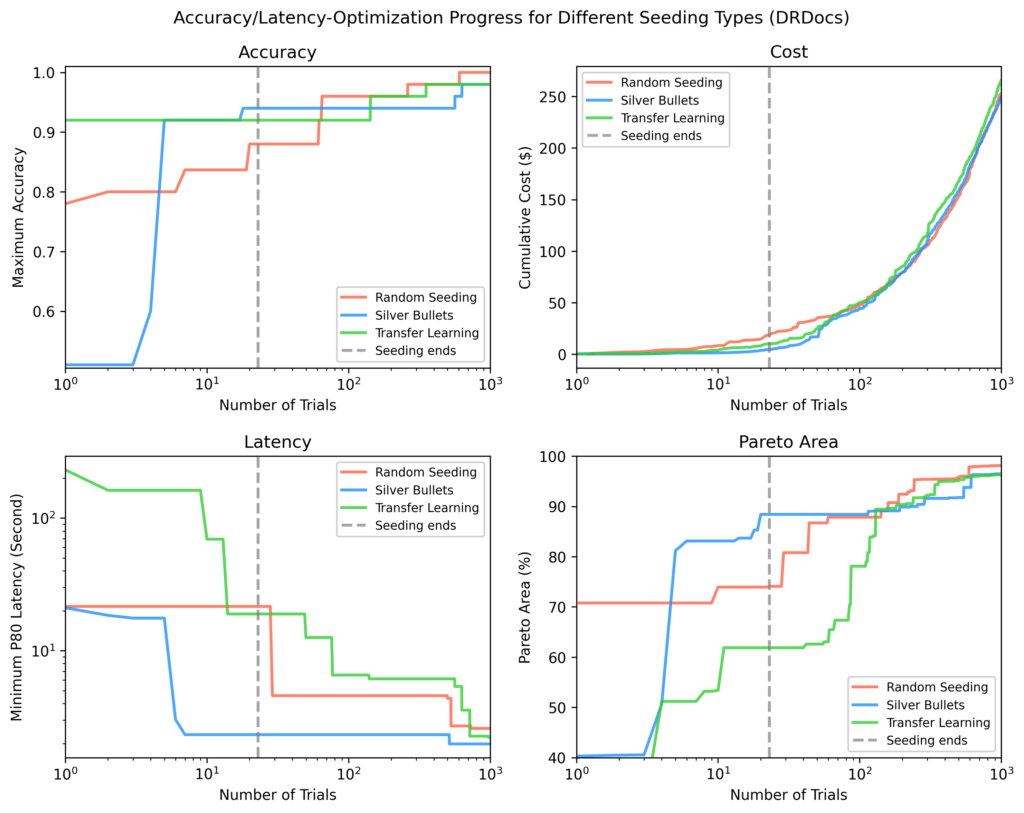
DRDocs
Much like Brilliant Biology, silver bullets reached an 88% Pareto-area after seeding vs. 71% (switch studying) and 62% (random).
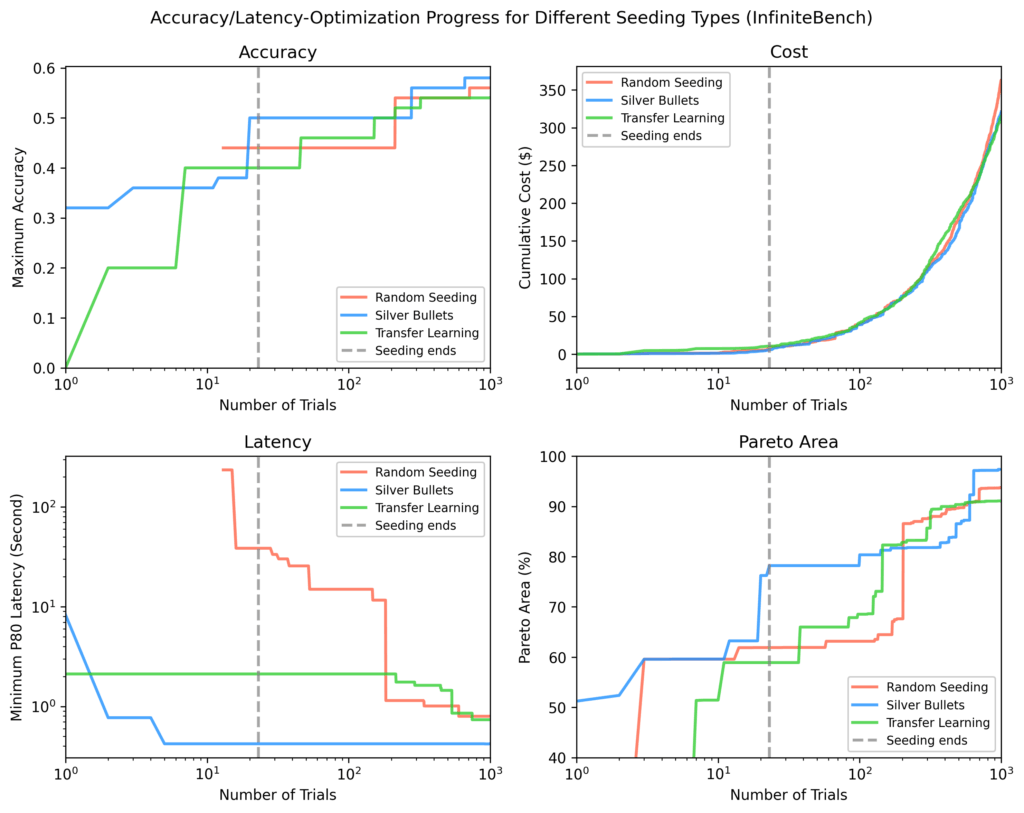
InfiniteBench
Different strategies wanted ~100 extra trials to match the silver bullet Pareto-area, and nonetheless didn’t match the quickest flows discovered by way of silver bullets by the top of ~1,000 trials.
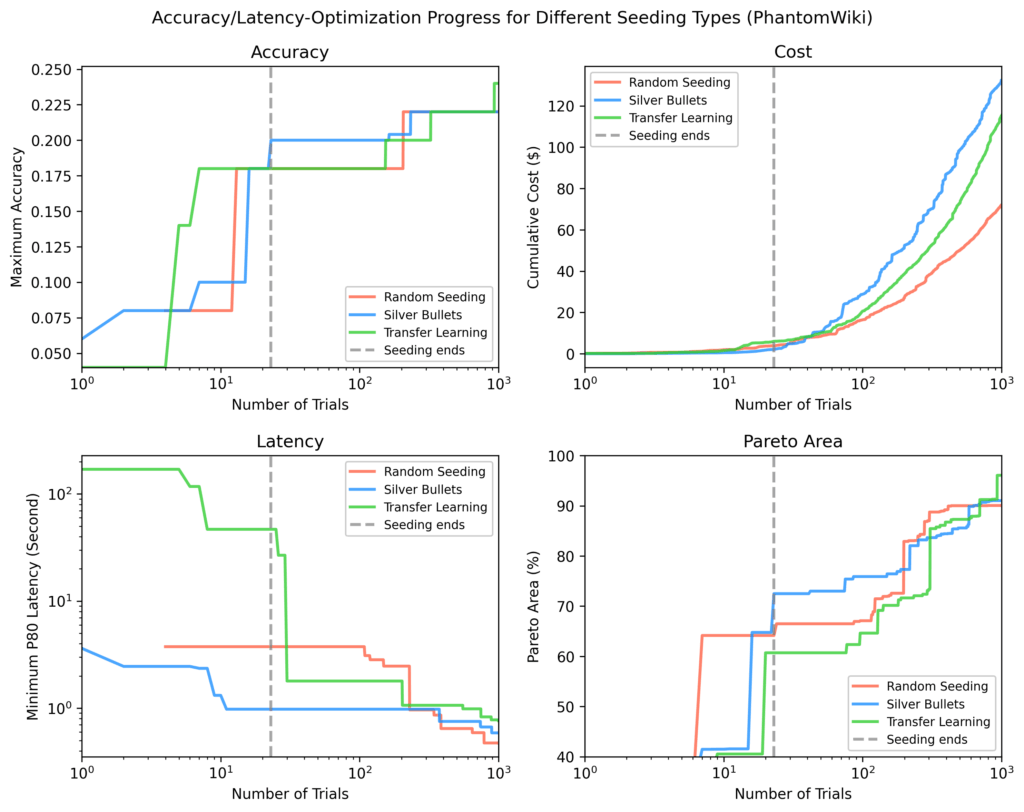
PhantomWiki
Silver bullets once more carried out greatest after seeding. This dataset confirmed the widest price divergence. After ~70 trials, the silver bullet run briefly targeted on costlier flows.
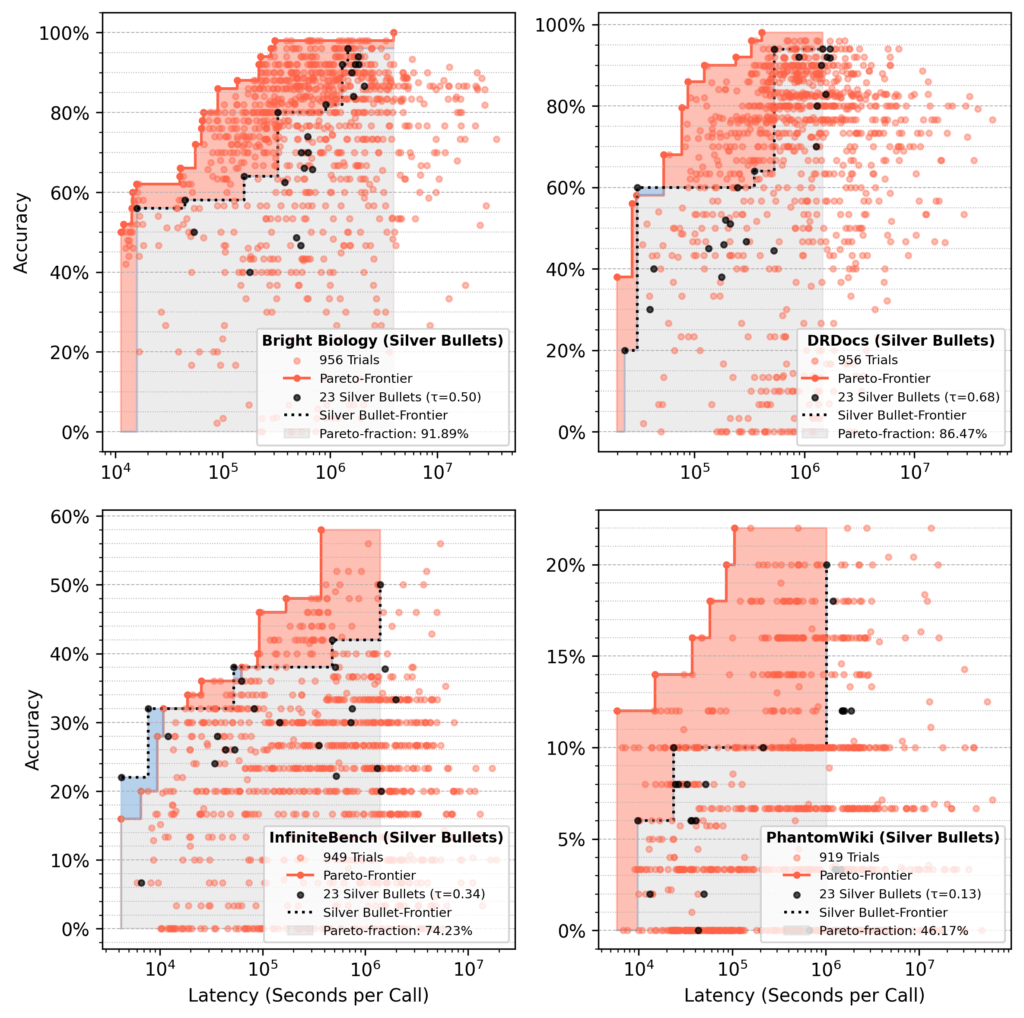
Pareto-fraction evaluation
In runs seeded with silver bullets, the 23 silver bullet flows accounted for ~75% of the ultimate Pareto-area after 1,000 trials, on common.
- Pink space: Features from optimization over preliminary silver bullet efficiency.
- Blue space: Silver bullet flows nonetheless dominating on the finish.
Our takeaway
Seeding with silver bullets delivers persistently sturdy outcomes and even outperforms switch studying, regardless of that technique pulling from a various set of historic Pareto-frontier flows.
For our two targets (accuracy and latency), silver bullets at all times begin with larger accuracy and decrease latency than flows from different methods.
In the long term, the TPE sampler reduces the preliminary benefit. Inside a couple of hundred trials, outcomes from all methods typically converge, which is anticipated since every ought to ultimately discover optimum flows.
So, do agentic flows exist that work properly throughout many use circumstances? Sure — to some extent:
- On common, a small set of silver bullets recovers about 75% of the Pareto-area from a full optimization.
- Efficiency varies by dataset, equivalent to 92% restoration for Brilliant Biology in comparison with 46% for PhantomWiki.
Backside line: silver bullets are a reasonable and environment friendly solution to approximate a full syftr run, however they don’t seem to be a substitute. Their impression might develop with extra coaching datasets or longer coaching optimizations.
Silver bullet parametrizations
We used the next:
LLMs
- microsoft/Phi-4-multimodal-instruct
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
- Qwen/Qwen2.5
- Qwen/Qwen3-32B
- google/gemma-3-27b-it
- nvidia/Llama-3_3-Nemotron-Tremendous-49B
Embedding fashions
- BAAI/bge-small-en-v1.5
- thenlper/gte-large
- mixedbread-ai/mxbai-embed-large-v1
- sentence-transformers/all-MiniLM-L12-v2
- sentence-transformers/paraphrase-multilingual-mpnet-base-v2
- BAAI/bge-base-en-v1.5
- BAAI/bge-large-en-v1.5
- TencentBAC/Conan-embedding-v1
- Linq-AI-Analysis/Linq-Embed-Mistral
- Snowflake/snowflake-arctic-embed-l-v2.0
- BAAI/bge-multilingual-gemma2
Movement sorts
- vanilla RAG
- ReAct RAG agent
- Critique RAG agent
- Subquestion RAG
Right here’s the complete record of all 23 silver bullets, sorted from low accuracy / low latency to excessive accuracy / excessive latency: silver_bullets.json.
Attempt it your self
Wish to experiment with these parametrizations? Use the running_flows.ipynb pocket book in our syftr repository — simply be sure to have entry to the fashions listed above.
For a deeper dive into syftr’s structure and parameters, try our technical paper or discover the codebase.
We’ll even be presenting this work on the Worldwide Convention on Automated Machine Studying (AutoML) in September 2025 in New York Metropolis.