

{kind=link}
You’re not brief on instruments. Or fashions. Or frameworks.
What you’re brief on is a principled means to make use of them — at scale.
Constructing efficient generative AI workflows, particularly agentic ones, means navigating a combinatorial explosion of decisions.
Each new retriever, immediate technique, textual content splitter, embedding mannequin, or synthesizing LLM multiplies the area of doable workflows, leading to a search area with over 10²³ doable configurations.
Trial-and-error doesn’t scale. And model-level benchmarks don’t mirror how parts behave when stitched into full programs.
That’s why we constructed syftr — an open supply framework for mechanically figuring out Pareto-optimal workflows throughout accuracy, value, and latency constraints.
See syftr in motion
Desire a fast walkthrough earlier than diving in? This brief demo exhibits how syftr works to assist AI groups effectively discover generative AI workflow configurations and floor high-performing choices.
The complexity behind generative AI workflows
As an instance how shortly complexity compounds, think about even a comparatively easy RAG pipeline just like the one proven in Determine 1.
Every element—retriever, immediate technique, embedding mannequin, textual content splitter, synthesizing LLM—requires cautious choice and tuning. And past these selections, there’s an increasing panorama of end-to-end workflow methods, from single-agent workflows like ReAct and LATS to multi-agent workflows like CaptainAgent and Magentic-One.

What’s lacking is a scalable, principled solution to discover this configuration area.
That’s the place syftr is available in.
Its open supply framework makes use of multi-objective Bayesian Optimization to effectively seek for Pareto-optimal RAG workflows, balancing value, accuracy, and latency throughout configurations that will be inconceivable to check manually.
Benchmarking Pareto-optimal workflows with syftr
As soon as syftr is utilized to a workflow configuration area, it surfaces candidate pipelines that obtain robust tradeoffs throughout key efficiency metrics.
The instance under exhibits syftr’s output on the CRAG (Complete RAG) Sports activities benchmark, highlighting workflows that keep excessive accuracy whereas considerably decreasing value.
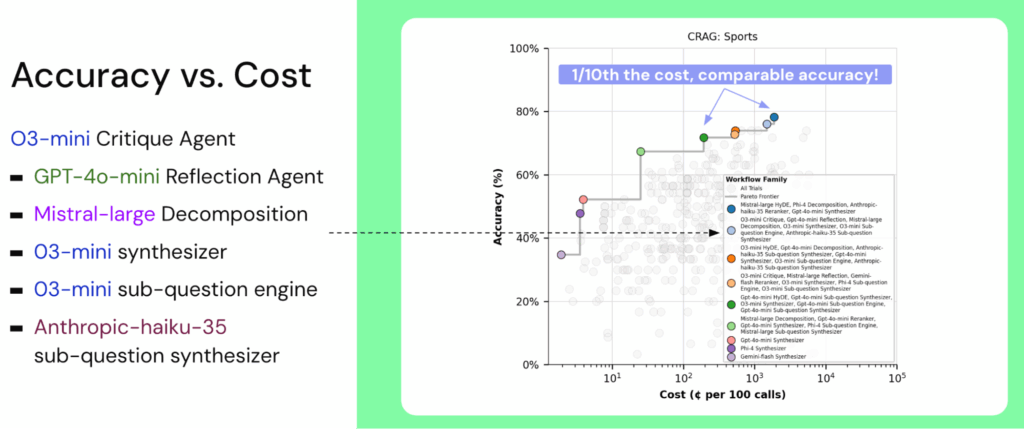
Whereas Determine 2 exhibits what syftr can ship, it’s equally vital to know how these outcomes are achieved.
On the core of syftr is a multi-objective search course of designed to effectively navigate huge workflow configuration areas. The framework prioritizes each efficiency and computational effectivity – important necessities for real-world experimentation at scale.
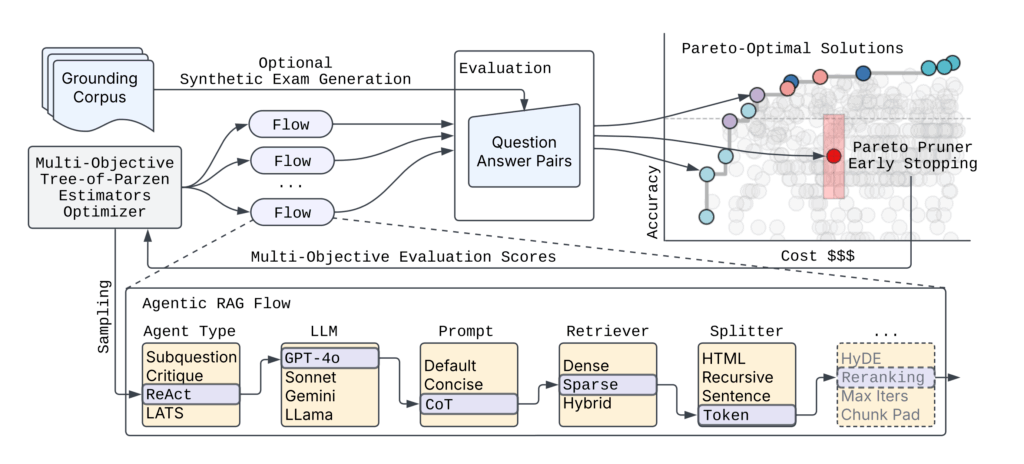
Since evaluating each workflow on this area isn’t possible, we usually consider round 500 workflows per run.
To make this course of much more environment friendly, syftr features a novel early stopping mechanism — Pareto Pruner — which halts analysis of workflows which are unlikely to enhance the Pareto frontier. This considerably reduces computational value and search time whereas preserving outcome high quality.
Why present benchmarks aren’t sufficient
Whereas mannequin benchmarks, like MMLU, LiveBench, Chatbot Enviornment, and the Berkeley Perform-Calling Leaderboard, have superior our understanding of remoted mannequin capabilities, basis fashions hardly ever function alone in real-world manufacturing environments.
As an alternative, they’re usually one element — albeit a necessary one — inside bigger, subtle AI programs.
Measuring intrinsic mannequin efficiency is crucial, however it leaves open crucial system-level questions:
- How do you assemble a workflow that meets task-specific targets for accuracy, latency, and value?
- Which fashions do you have to use—and during which elements of the pipeline?
syftr addresses this hole by enabling automated, multi-objective analysis throughout total workflows.
It captures nuanced tradeoffs that emerge solely when parts work together inside a broader pipeline, and systematically explores configuration areas which are in any other case impractical to guage manually.
syftr is the primary open-source framework particularly designed to mechanically establish Pareto-optimal generative AI workflows that steadiness a number of competing goals concurrently — not simply accuracy, however latency and value as properly.
It attracts inspiration from present analysis, together with:
- AutoRAG, which focuses solely on optimizing for accuracy
- Kapoor et al. ‘s work, AI Brokers That Matter, which emphasizes cost-controlled analysis to stop incentivizing overly expensive, leaderboard-focused brokers. This precept serves as one in every of our core analysis inspirations.
Importantly, syftr can also be orthogonal to LLM-as-optimizer frameworks like Hint and TextGrad, and generic move optimizers like DSPy. Such frameworks could be mixed with syftr to additional optimize prompts in workflows.
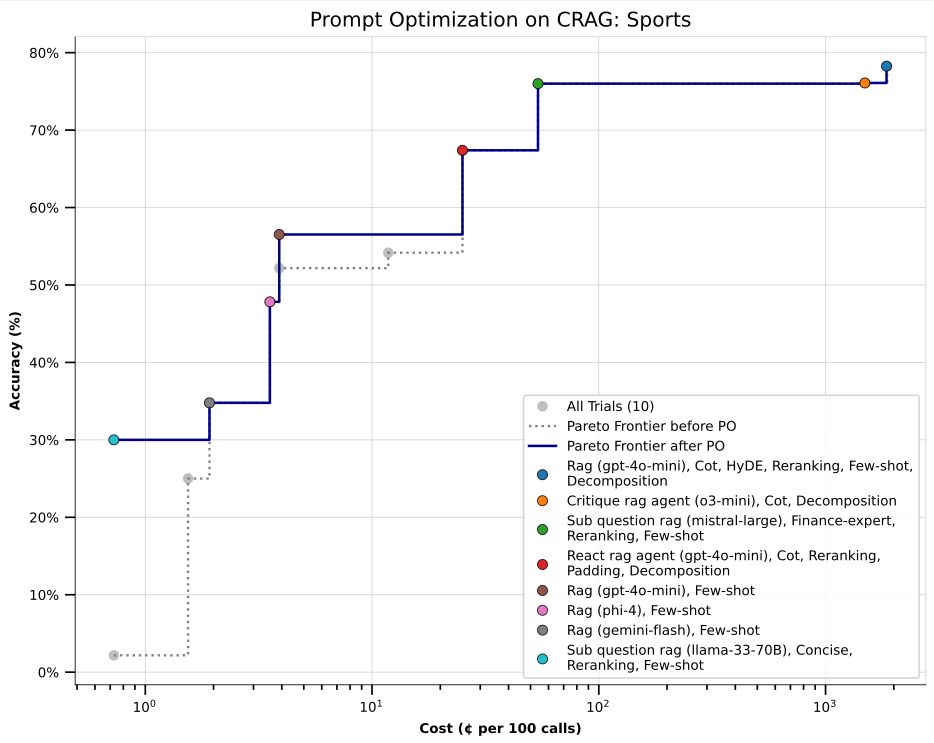
In early experiments, syftr first recognized Pareto-optimal workflows on the CRAG Sports activities benchmark.
We then utilized Hint to optimize prompts throughout all of these configurations — taking a two-stage method: multi-objective workflow search adopted by fine-grained immediate tuning.
The outcome: notable accuracy enhancements, particularly in low-cost workflows that originally exhibited decrease accuracy (these clustered within the lower-left of the Pareto frontier). These positive aspects recommend that post-hoc immediate optimization can meaningfully enhance efficiency, even in extremely cost-constrained settings.
This two-stage method — first multi-objective configuration search, then immediate refinement — highlights the advantages of mixing syftr with specialised downstream instruments, enabling modular and versatile workflow optimization methods.
Constructing and increasing syftr’s search area
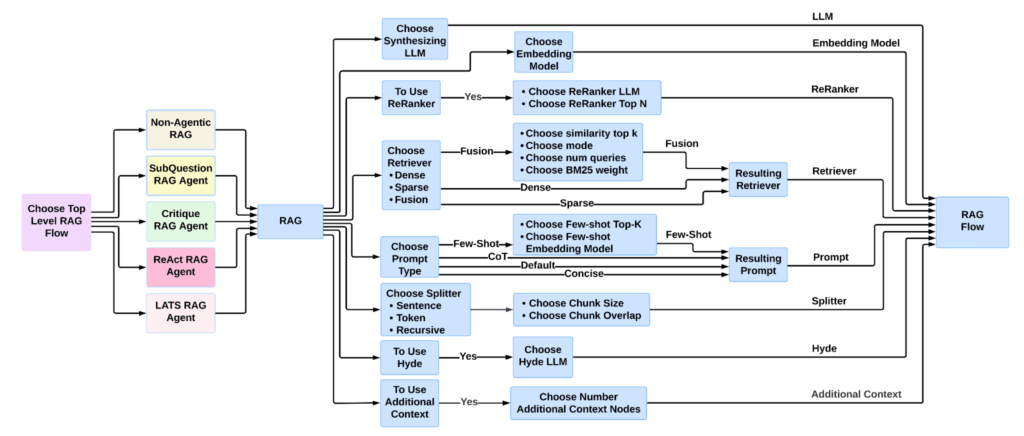
Syftr cleanly separates the workflow search area from the underlying optimization algorithm. This modular design permits customers to simply lengthen or customise the area, including or eradicating flows, fashions, and parts by modifying configuration recordsdata.
The default implementation makes use of Multi-Goal Tree-of-Parzen-Estimators (MOTPE), however syftr helps swapping in different optimization methods.
Contributions of latest flows, modules, or algorithms are welcomed through pull request at github.com/datarobot/syftr.
Constructed on the shoulders of open supply
syftr builds on various highly effective open supply libraries and frameworks:
- Ray for distributing and scaling search over giant clusters of CPUs and GPUs
- Ray Serve for autoscaling mannequin internet hosting
- Optuna for its versatile define-by-run interface (much like PyTorch’s keen execution) and assist for state-of-the-art multi-objective optimization algorithms
- LlamaIndex for constructing subtle agentic and non-agentic RAG workflows
- HuggingFace Datasets for quick, collaborative, and uniform dataset interface
- Hint for optimizing textual parts inside workflows, similar to prompts
syftr is framework-agnostic: workflows could be constructed utilizing any orchestration library or modeling stack. This flexibility permits customers to increase or adapt syftr to suit all kinds of tooling preferences.
Case examine: syftr on CRAG Sports activities
Benchmark setup
The CRAG benchmark dataset was launched by Meta for the KDD Cup 2024 and contains three duties:
- Process 1: Retrieval summarization
- Process 2: Information graph and internet retrieval
- Process 3: Finish-to-end RAG
syftr was evaluated on Process 3 (CRAG3), which incorporates 4,400 QA pairs spanning a variety of matters. The official benchmark performs RAG over 50 webpages retrieved for every query.
To extend issue, we mixed all webpages throughout all questions right into a single corpus, making a extra reasonable, difficult retrieval setting.
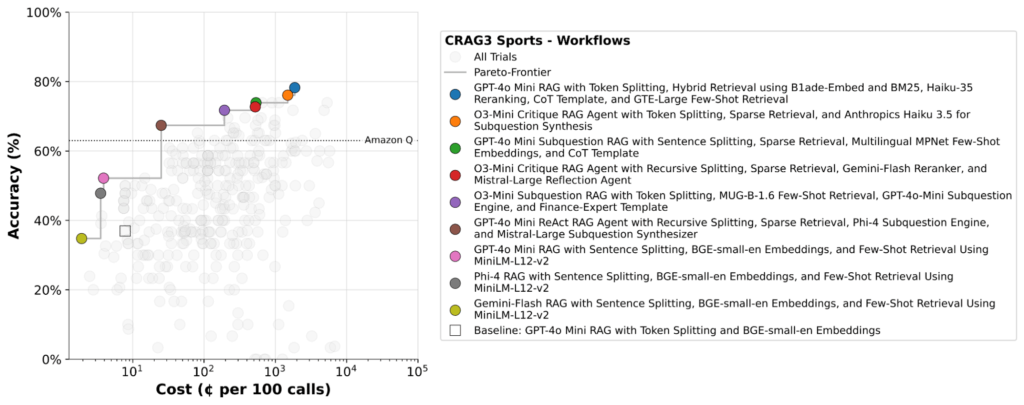
Notice: Amazon Q pricing makes use of a per-user/month pricing mannequin, which differs from the per-query token-based value estimates used for syftr workflows.
Key observations and insights
Throughout datasets, syftr persistently surfaces significant optimization patterns:
- Non-agentic workflows dominate the Pareto frontier. They’re quicker and cheaper, main the optimizer to favor these configurations extra steadily than agentic ones.
- GPT-4o-mini steadily seems in Pareto-optimal flows, suggesting it affords a powerful steadiness of high quality and value as a synthesizing LLM.
- Reasoning fashions like o3-mini carry out properly on quantitative duties (e.g., FinanceBench, InfiniteBench), possible attributable to their multi-hop reasoning capabilities.
- Pareto frontiers ultimately flatten after an preliminary rise, with diminishing returns in accuracy relative to steep value will increase, underscoring the necessity for instruments like syftr that assist pinpoint environment friendly working factors.
We routinely discover that the workflow on the knee level of the Pareto frontier loses just some proportion factors in accuracy in comparison with probably the most correct setup — whereas being 10x cheaper.
syftr makes it simple to search out that candy spot.
Price of working syftr
In our experiments, we allotted a funds of ~500 workflow evaluations per activity. Though precise prices range based mostly on the dataset and search area complexity, we persistently recognized robust Pareto frontiers with a one-time search value of roughly $500 per use case.
We anticipate this value to lower as extra environment friendly search algorithms and area definitions are developed.
Importantly, this preliminary funding is minimal relative to the long-term positive aspects from deploying optimized workflows, whether or not by decreased compute utilization, improved accuracy, or higher person expertise in high-traffic programs.
For detailed outcomes throughout six benchmark duties, together with datasets past CRAG, seek advice from the full syftr paper.
Getting began and contributing
To get began with syftr, clone or fork the repository on GitHub. Benchmark datasets can be found on HuggingFace, and syftr additionally helps user-defined datasets for customized experimentation.
The present search area contains:
- 9 proprietary LLMs
- 11 embedding fashions
- 4 basic immediate methods
- 3 retrievers
- 4 textual content splitters (with parameter configurations)
- 4 agentic RAG flows and 1 non-agentic RAG move, every with related hierarchical hyperparameters
New parts, similar to fashions, flows, or search modules, could be added or modified through configuration recordsdata. Detailed walkthroughs can be found to assist customization.
syftr is developed absolutely within the open. We welcome contributions through pull requests, function proposals, and benchmark studies. We’re significantly focused on concepts that advance the analysis route or enhance the framework’s extensibility.
What’s forward for syftr
syftr continues to be evolving, with a number of lively areas of analysis designed to increase its capabilities and sensible impression:
- Meta-learning
At present, every search is carried out from scratch. We’re exploring meta-learning methods that leverage prior runs throughout comparable duties to speed up and information future searches. - Multi-agent workflow analysis
Whereas multi-agent programs are gaining traction, they introduce further complexity and value. We’re investigating how these workflows examine to single-agent and non-agentic pipelines, and when their tradeoffs are justified. - Composability with immediate optimization frameworks
syftr is complementary to instruments like DSPy, Hint, and TextGrad, which optimize textual parts inside workflows. We’re exploring methods to extra deeply combine these programs to collectively optimize construction and language. - Extra agentic duties
We began with question-answer duties, a crucial manufacturing use case for brokers. Subsequent, we plan to quickly increase syftr’s activity repertoire to code technology, knowledge evaluation, and interpretation. We additionally invite the neighborhood to recommend further duties for syftr to prioritize.
As these efforts progress, we purpose to increase syftr’s worth as a analysis software, a benchmarking framework, and a sensible assistant for system-level generative AI design.
If you happen to’re working on this area, we welcome your suggestions, concepts, and contributions.
Attempt the code, learn the analysis
To discover syftr additional, take a look at the GitHub repository or learn the complete paper on ArXiv for particulars on methodology and outcomes.
Syftr has been accepted to look on the Worldwide Convention on Automated Machine Studying (AutoML) in September, 2025 in New York Metropolis.
We look ahead to seeing what you construct and discovering what’s subsequent, collectively.