

{kind=link}
Serps like Google Pictures, Bing Visible Search, and Pinterest’s Lens make it appear very simple after we kind in a number of phrases or add an image, and immediately, we get again essentially the most related related pictures from billions of prospects.
Below the hood, these methods use big stacks of knowledge and superior deep studying fashions to rework each pictures and textual content into numerical vectors (known as embeddings) that stay in the identical “semantic area.”
On this article, we’ll construct a mini model of that type of search engine, however with a a lot smaller animal dataset with pictures of tigers, lions, elephants, zebras, giraffes, pandas, and penguins.
You may observe the identical method with different datasets like COCO, Unsplash photographs, and even your private picture assortment.
What We’re Constructing
Our picture search engine will:
- Use BLIP to routinely generate captions (descriptions) for each picture.
- Use CLIP to transform each pictures and textual content into embeddings.
- Retailer these embeddings in a vector database (ChromaDB).
- Permits you to search by textual content question and retrieve essentially the most related pictures.
Why BLIP and CLIP?
BLIP (Bootstrapping Language-Picture Pretraining)
BLIP is a deep studying mannequin able to producing textual descriptions for photographs (also called picture captioning). If our dataset doesn’t have already got an outline, BLIP can create one by taking a look at a picture, akin to a tiger, and producing one thing like “a big orange cat with black stripes mendacity on grass.”
This helps particularly the place:
- The dataset is only a folder of pictures with none labels assigned to them.
- And in order for you richer, extra pure generalised descriptions to your pictures.
Learn extra: Picture Captioning Utilizing Deep Studying
CLIP (Contrastive Language–Picture Pre-training)
CLIP, by OpenAI, learns to attach textual content and pictures inside a shared vector area.
It might probably:
- Convert a picture into an embedding.
- Convert textual content into an embedding.
- Examine the 2 immediately; in the event that they’re shut on this area, it means they match semantically.
Instance:
- Textual content: “a tall animal with a protracted neck” → vector A
- Picture of a giraffe → vector B
- If vectors A and B are shut, CLIP says, “Sure, that is most likely a giraffe.”

Step-by-Step Implementation
We’ll do every part inside Google Colab, so that you don’t want any native setup. You may entry the pocket book from this hyperlink: Embedding_Similarity_Animals
1. Set up Dependencies
We’ll set up PyTorch, Transformers (for BLIP and CLIP), and ChromaDB (vector database). These are the primary dependencies for our mini undertaking.
!pip set up transformers torch -q
!pip set up chromadb -q2. Obtain the Dataset
For this demo, we’ll use the Animal Dataset from Kaggle.
import kagglehub
# Obtain the most recent model
path = kagglehub.dataset_download("likhon148/animal-data")
print("Path to dataset recordsdata:", path)Transfer to the /content material listing in Colab:
!mv /root/.cache/kagglehub/datasets/likhon148/animal-data/variations/1 /content material/Examine what courses we now have:
!ls -l /content material/1/animal_dataYou’ll see folders like:
3. Depend Pictures per Class
Simply to get an thought of our dataset.
import os
base_path = "/content material/1/animal_data"
for folder in sorted(os.listdir(base_path)):
folder_path = os.path.be part of(base_path, folder)
if os.path.isdir(folder_path):
rely = len([f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))])
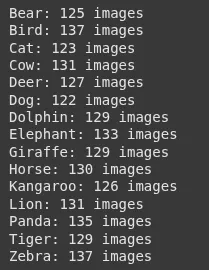
print(f"{folder}: {rely} pictures")Output:
4. Load CLIP Mannequin
We’ll use CLIP for embeddings.
from transformers import CLIPProcessor, CLIPModel
import torch
model_id = "openai/clip-vit-base-patch32"
processor = CLIPProcessor.from_pretrained(model_id)
mannequin = CLIPModel.from_pretrained(model_id)
gadget="cuda" if torch.cuda.is_available() else 'cpu'
mannequin.to(gadget)5. Load BLIP Mannequin for Picture Captioning
BLIP will create a caption for every picture.
from transformers import BlipProcessor, BlipForConditionalGeneration
blip_model_id = "Salesforce/blip-image-captioning-base"
caption_processor = BlipProcessor.from_pretrained(blip_model_id)
caption_model = BlipForConditionalGeneration.from_pretrained(blip_model_id).to(gadget)6. Put together Picture Paths
We’ll collect all picture paths from the dataset.
image_paths = []
for root, _, recordsdata in os.stroll(base_path):
for f in recordsdata:
if f.decrease().endswith((".jpg", ".jpeg", ".png", ".bmp", ".webp")):
image_paths.append(os.path.be part of(root, f))7. Generate Descriptions and Embeddings
For every picture:
- BLIP generates an outline for that picture.
- CLIP generates a picture embedding based mostly on the pixels of the picture.
import pandas as pd
from PIL import Picture
data = []
for img_path in image_paths:
picture = Picture.open(img_path).convert("RGB")
# BLIP: Generate caption
caption_inputs = caption_processor(picture, return_tensors="pt").to(gadget)
with torch.no_grad():
out = caption_model.generate(**caption_inputs)
description = caption_processor.decode(out[0], skip_special_tokens=True)
# CLIP: Get picture embeddings
inputs = processor(pictures=picture, return_tensors="pt").to(gadget)
with torch.no_grad():
image_features = mannequin.get_image_features(**inputs)
image_features = image_features.cpu().numpy().flatten().tolist()
data.append({
"image_path": img_path,
"image_description": description,
"image_embeddings": image_features
})
df = pd.DataFrame(data)8. Retailer in ChromaDB
We push our embeddings right into a vector database.
import chromadb
shopper = chromadb.Consumer()
assortment = shopper.create_collection(title="animal_images")
for i, row in df.iterrows():
assortment.add( # upserting to our chroma assortment
ids=[str(i)],
paperwork=[row["image_description"]],
metadatas=[{"image_path": row["image_path"]}],
embeddings=[row["image_embeddings"]]
)
print("✅ All pictures saved in Chroma")9. Create a Search Perform
Given a textual content question:
- CLIP encodes it into an embedding.
- ChromaDB finds the closest picture embeddings.
- We show the outcomes.
import matplotlib.pyplot as plt
def search_images(question, top_k=5):
inputs = processor(textual content=[query], return_tensors="pt", truncation=True).to(gadget)
with torch.no_grad():
text_embedding = mannequin.get_text_features(**inputs)
text_embedding = text_embedding.cpu().numpy().flatten().tolist()
outcomes = assortment.question(
query_embeddings=[text_embedding],
n_results=top_k
)
print("High outcomes for:", question)
for i, meta in enumerate(outcomes["metadatas"][0]):
img_path = meta["image_path"]
print(f"{i+1}. {img_path} ({outcomes['documents'][0][i]})")
img = Picture.open(img_path)
plt.imshow(img)
plt.axis("off")
plt.present()
return outcomes10. Check the Search Engine
Attempt some queries:
search_images("a big wild cat with stripes")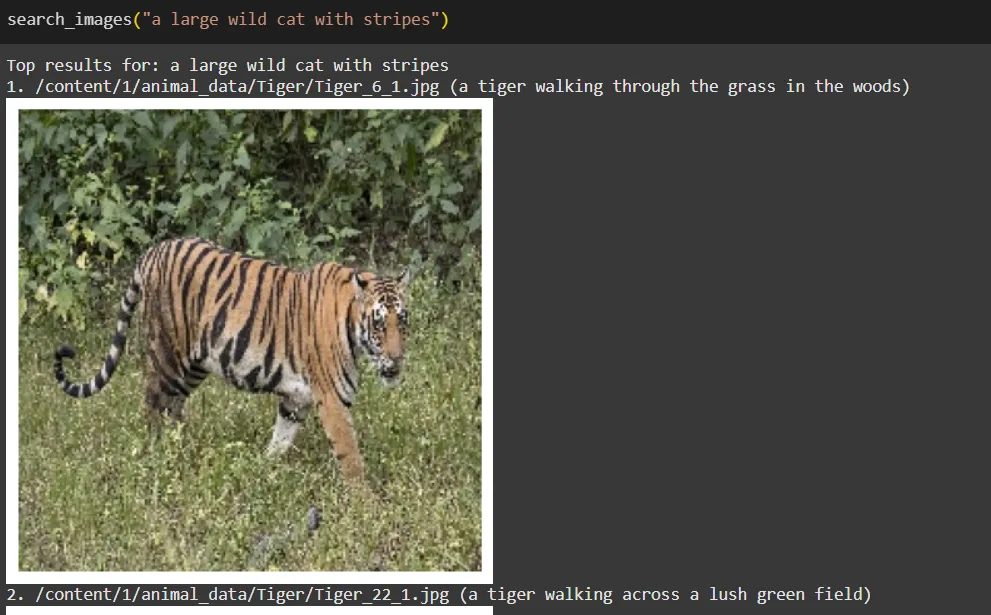
search_images("predator with a mane")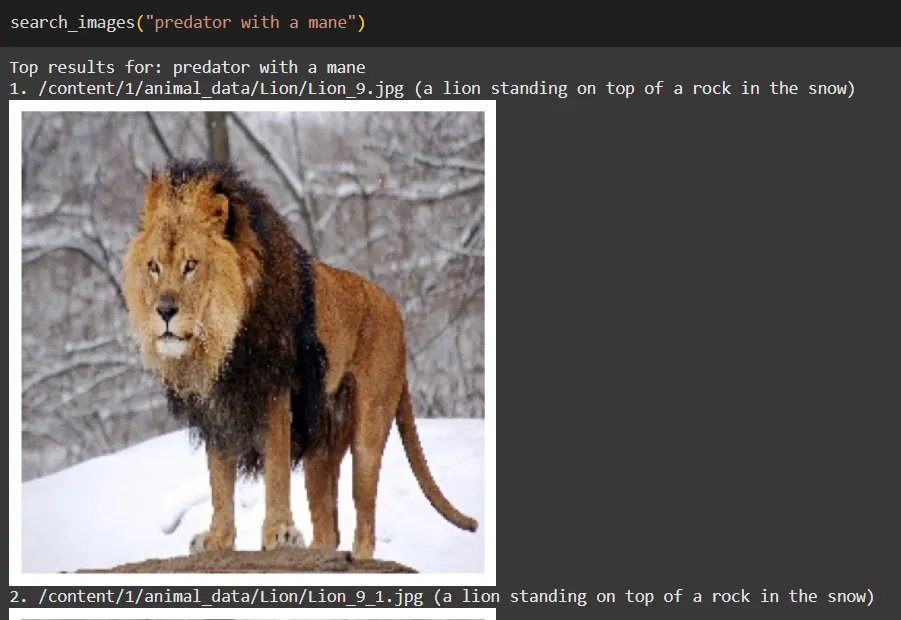
search_images("striped horse-like animal")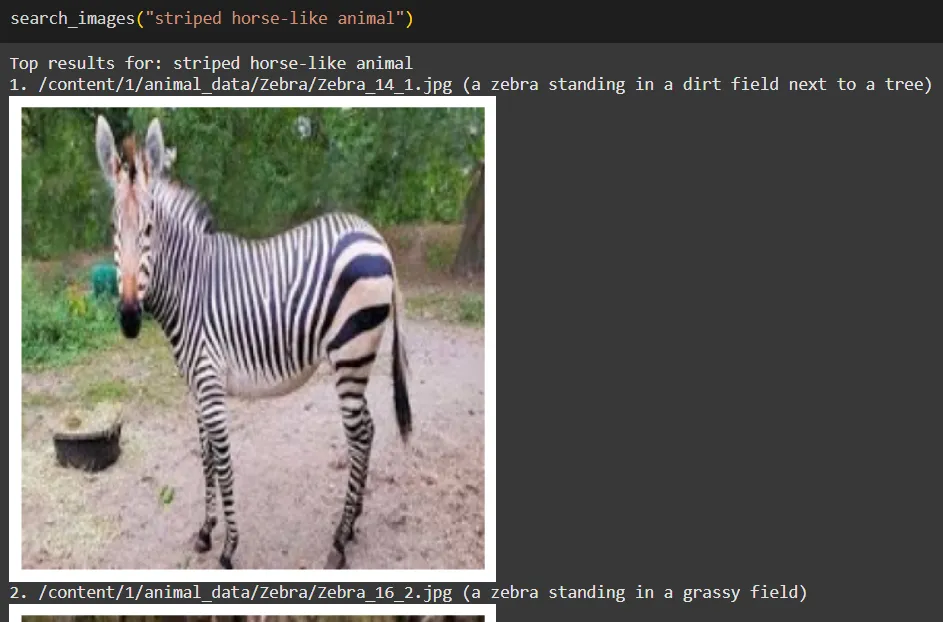
How It Works in Easy Phrases
- BLIP: Seems to be at every picture and writes a caption (this turns into our “textual content” for the picture).
- CLIP: Converts each captions and pictures into embeddings in the identical area.
- ChromaDB: Shops these embeddings and finds the closest match after we search.
- Search Perform(Retriever): Turns your question into an embedding and asks ChromaDB: “Which pictures are closest to this question embedding?”
Keep in mind, this Search Engine can be more practical if we had a a lot bigger dataset, and if we utilised a greater description for every picture would make a lot efficient embeddings inside our unified illustration area.
Limitations
- BLIP captions is likely to be generic for some pictures.
- CLIP’s embeddings work effectively for common ideas, however would possibly battle with very domain-specific or fine-grained variations until educated on related knowledge.
- Search high quality relies upon closely on the dataset measurement and variety.
Conclusion
In abstract, making a miniature picture search engine utilizing vector representations of textual content and pictures presents thrilling alternatives for enhancing picture retrieval. By utilising BLIP for captioning and CLIP for embedding, we are able to construct a flexible instrument that adapts to varied datasets, from private photographs to specialised collections.
Trying forward, options like image-to-image search can additional enrich person expertise, permitting for simple discovery of visually related pictures. Moreover, leveraging bigger CLIP fashions and fine-tuning them on particular datasets can considerably enhance search accuracy.
This undertaking not solely serves as a stable basis for AI-driven picture search but additionally invitations additional exploration and innovation. Embrace the potential of this know-how, and rework the way in which we interact with pictures.
Continuously Requested Questions
A. BLIP generates captions for pictures, creating textual descriptions that may be embedded and in contrast with search queries. That is helpful when the dataset doesn’t have already got labels.
A. CLIP converts each pictures and textual content into embeddings inside the identical vector area, permitting direct comparability between them to search out semantic matches.
A. ChromaDB shops the embeddings and retrieves essentially the most related pictures by discovering the closest matches to a search question’s embedding.
GenAI Intern @ Analytics Vidhya | Closing Yr @ VIT Chennai
Enthusiastic about AI and machine studying, I am desperate to dive into roles as an AI/ML Engineer or Knowledge Scientist the place I could make an actual influence. With a knack for fast studying and a love for teamwork, I am excited to carry revolutionary options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout varied fields and take the initiative to delve into knowledge engineering, making certain I keep forward and ship impactful tasks.
Login to proceed studying and revel in expert-curated content material.