

{kind=link}

|
Organizations face a difficult trade-off when adapting AI fashions to their particular enterprise wants: accept generic fashions that produce common outcomes, or deal with the complexity and expense of superior mannequin customization. Conventional approaches drive a alternative between poor efficiency with smaller fashions or the excessive prices of deploying bigger mannequin variants and managing advanced infrastructure. Reinforcement fine-tuning is a complicated method that trains fashions utilizing suggestions as an alternative of large labeled datasets, however implementing it usually requires specialised ML experience, difficult infrastructure, and vital funding—with no assure of reaching the accuracy wanted for particular use circumstances.
At present, we’re asserting reinforcement fine-tuning in Amazon Bedrock, a brand new mannequin customization functionality that creates smarter, cheaper fashions that study from suggestions and ship higher-quality outputs for particular enterprise wants. Reinforcement fine-tuning makes use of a feedback-driven strategy the place fashions enhance iteratively primarily based on reward alerts, delivering 66% accuracy good points on common over base fashions.
Amazon Bedrock automates the reinforcement fine-tuning workflow, making this superior mannequin customization method accessible to on a regular basis builders with out requiring deep machine studying (ML) experience or massive labeled datasets.
How reinforcement fine-tuning works
Reinforcement fine-tuning is constructed on high of reinforcement studying ideas to handle a typical problem: getting fashions to constantly produce outputs that align with enterprise necessities and person preferences.
Whereas conventional fine-tuning requires massive, labeled datasets and costly human annotation, reinforcement fine-tuning takes a distinct strategy. As an alternative of studying from mounted examples, it makes use of reward capabilities to judge and choose which responses are thought of good for explicit enterprise use circumstances. This teaches fashions to grasp what makes a high quality response with out requiring large quantities of pre-labeled coaching knowledge, making superior mannequin customization in Amazon Bedrock extra accessible and cost-effective.
Listed below are the advantages of utilizing reinforcement fine-tuning in Amazon Bedrock:
- Ease of use – Amazon Bedrock automates a lot of the complexity, making reinforcement fine-tuning extra accessible to builders constructing AI purposes. Fashions will be educated utilizing current API logs in Amazon Bedrock or by importing datasets as coaching knowledge, eliminating the necessity for labeled datasets or infrastructure setup.
- Higher mannequin efficiency – Reinforcement fine-tuning improves mannequin accuracy by 66% on common over base fashions, enabling optimization for worth and efficiency by coaching smaller, sooner, and extra environment friendly mannequin variants. This works with Amazon Nova 2 Lite mannequin, bettering high quality and worth efficiency for particular enterprise wants, with help for extra fashions coming quickly.
- Safety – Information stays throughout the safe AWS surroundings all through the whole customization course of, mitigating safety and compliance issues.
The aptitude helps two complementary approaches to supply flexibility for optimizing fashions:
- Reinforcement Studying with Verifiable Rewards (RLVR) makes use of rule-based graders for goal duties like code technology or math reasoning.
- Reinforcement Studying from AI Suggestions (RLAIF) employs AI-based judges for subjective duties like instruction following or content material moderation.
Getting began with reinforcement fine-tuning in Amazon Bedrock
Let’s stroll by means of making a reinforcement fine-tuning job.
First, I entry the Amazon Bedrock console. Then, I navigate to the Customized fashions web page. I select Create after which select Reinforcement fine-tuning job.
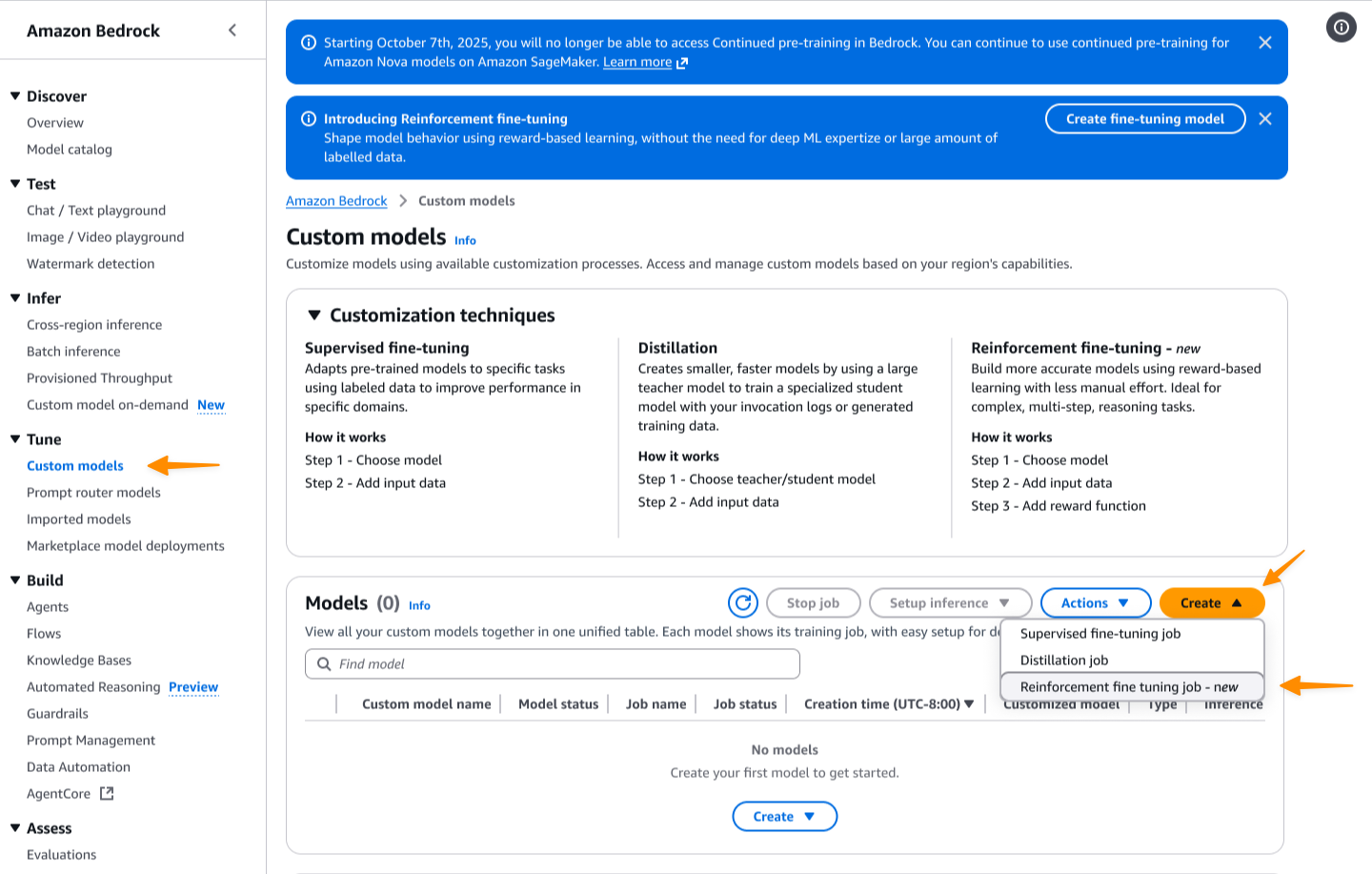
I begin by coming into the title of this customization job after which choose my base mannequin. At launch, reinforcement fine-tuning helps Amazon Nova 2 Lite, with help for extra fashions coming quickly.
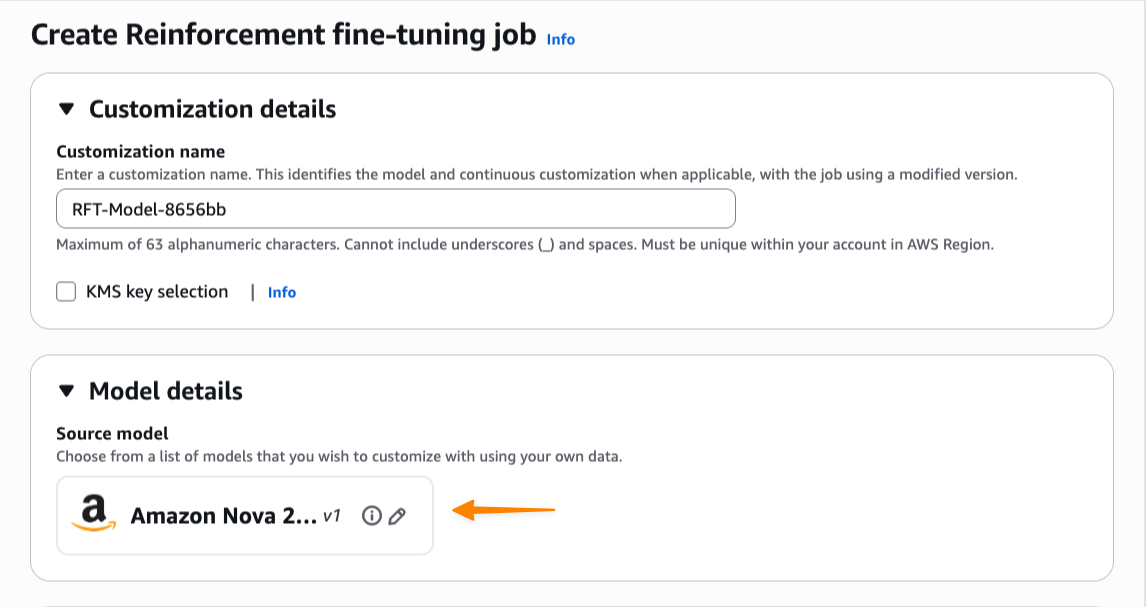
Subsequent, I want to supply coaching knowledge. I can use my saved invocation logs straight, eliminating the necessity to add separate datasets. I may also add new JSONL recordsdata or choose current datasets from Amazon Easy Storage Service (Amazon S3). Reinforcement fine-tuning mechanically validates my coaching dataset and helps the OpenAI Chat Completions knowledge format. If I present invocation logs within the Amazon Bedrock invoke or converse format, Amazon Bedrock mechanically converts them to the Chat Completions format.
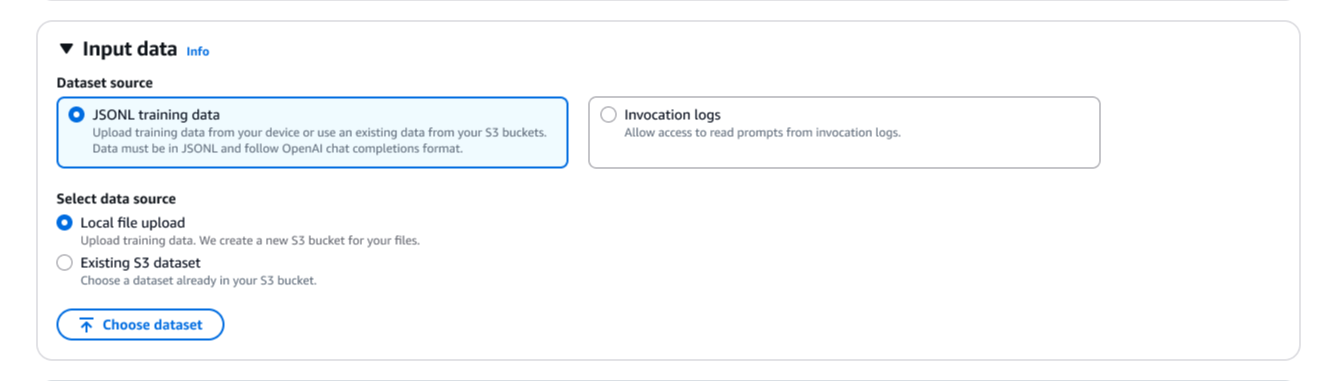
The reward operate setup is the place I outline what constitutes an excellent response. I’ve two choices right here. For goal duties, I can choose Customized code and write customized Python code that will get executed by means of AWS Lambda capabilities. For extra subjective evaluations, I can choose Mannequin as choose to make use of basis fashions (FMs) as judges by offering analysis directions.
Right here, I choose Customized code, and I create a brand new Lambda operate or use an current one as a reward operate. I can begin with one of many supplied templates and customise it for my particular wants.
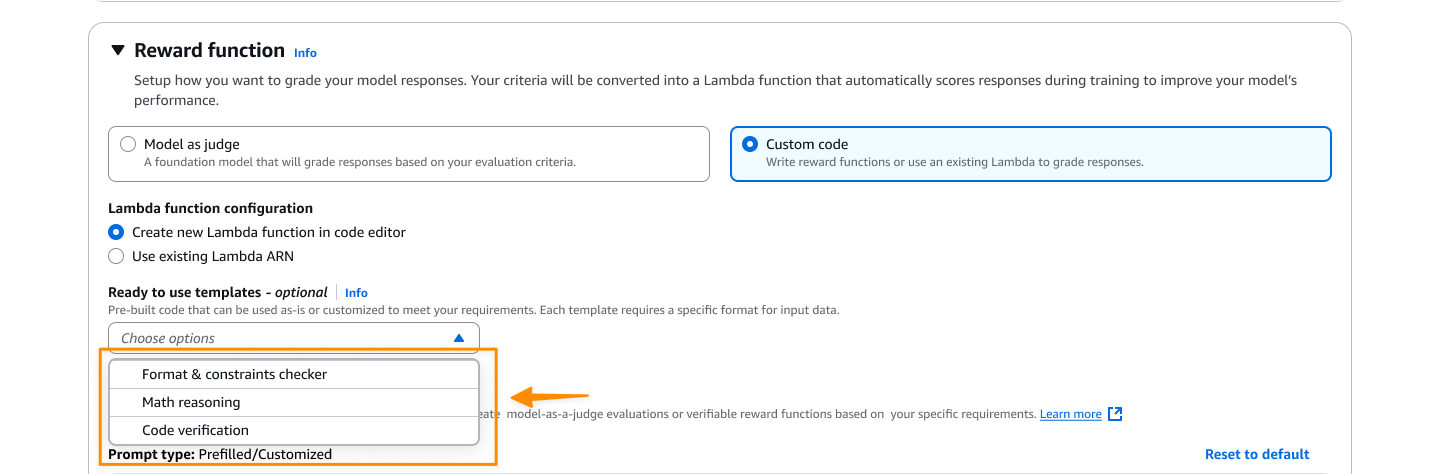
I can optionally modify default hyperparameters like studying price, batch measurement, and epochs.

For enhanced safety, I can configure digital personal cloud (VPC) settings and AWS Key Administration Service (AWS KMS) encryption to fulfill my group’s compliance necessities. Then, I select Create to begin the mannequin customization job.
Through the coaching course of, I can monitor real-time metrics to grasp how the mannequin is studying. The coaching metrics dashboard exhibits key efficiency indicators together with reward scores, loss curves, and accuracy enhancements over time. These metrics assist me perceive whether or not the mannequin is converging correctly and if the reward operate is successfully guiding the training course of.

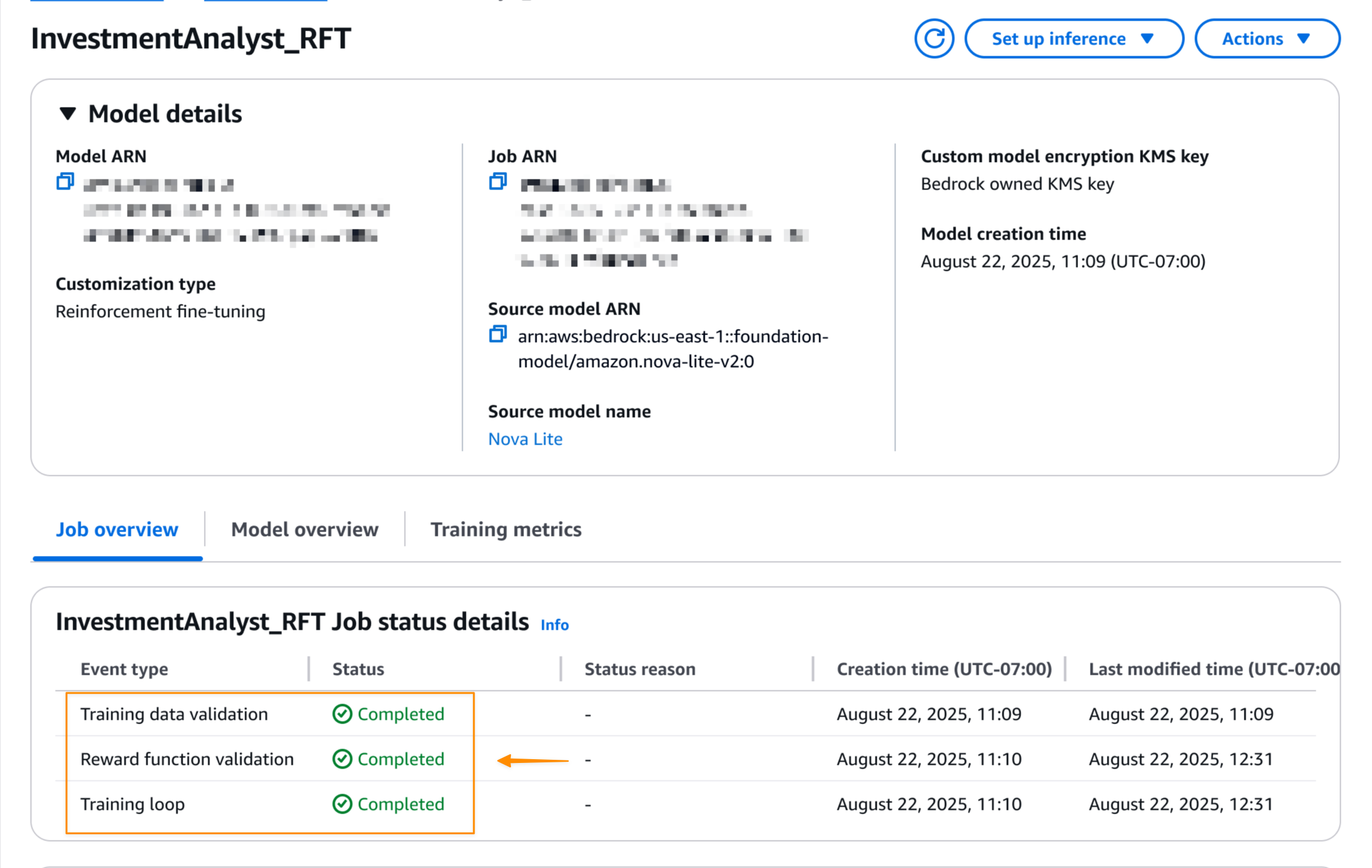
When the reinforcement fine-tuning job is accomplished, I can see the ultimate job standing on the Mannequin particulars web page.
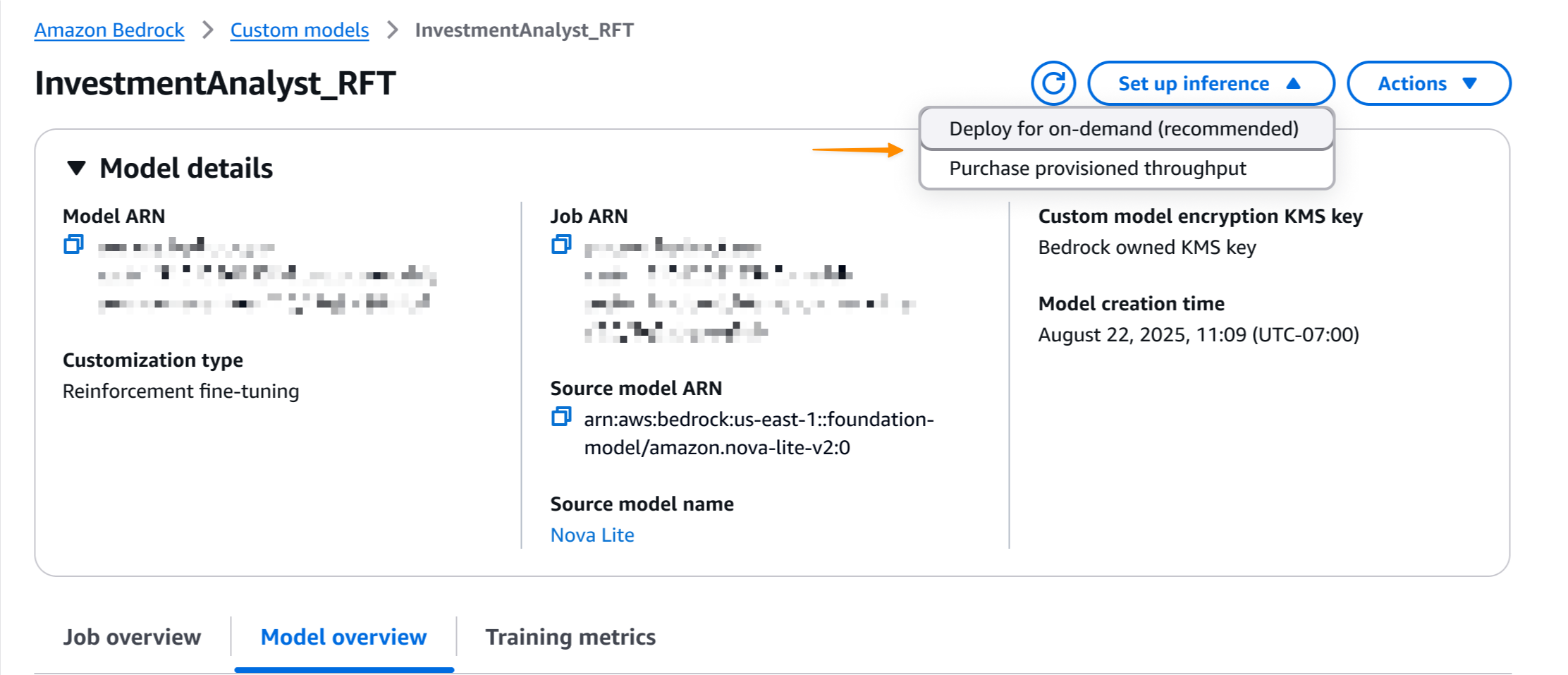
As soon as the job is accomplished, I can deploy the mannequin with a single click on. I choose Arrange inference, then select Deploy for on-demand.
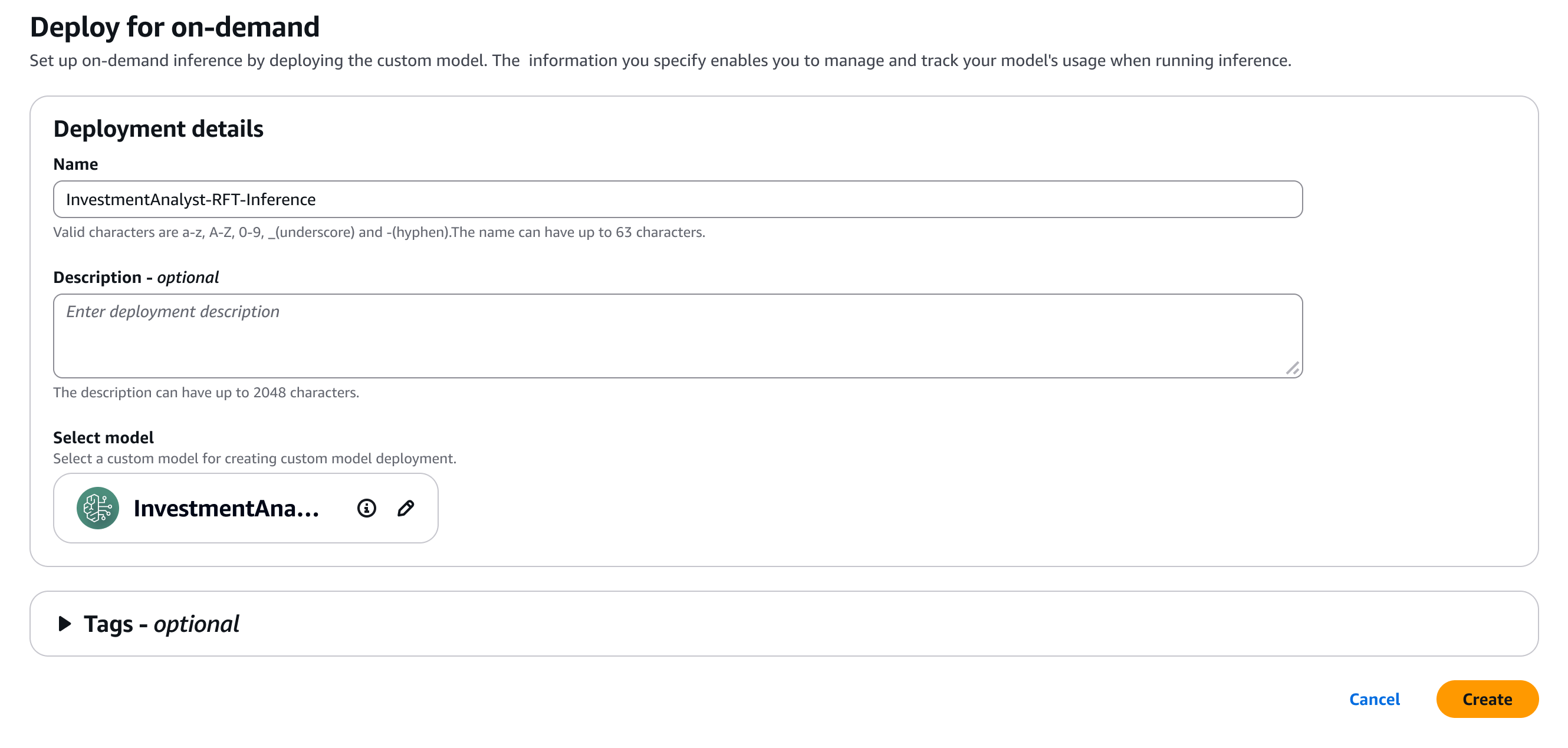
Right here, I present just a few particulars for my mannequin.
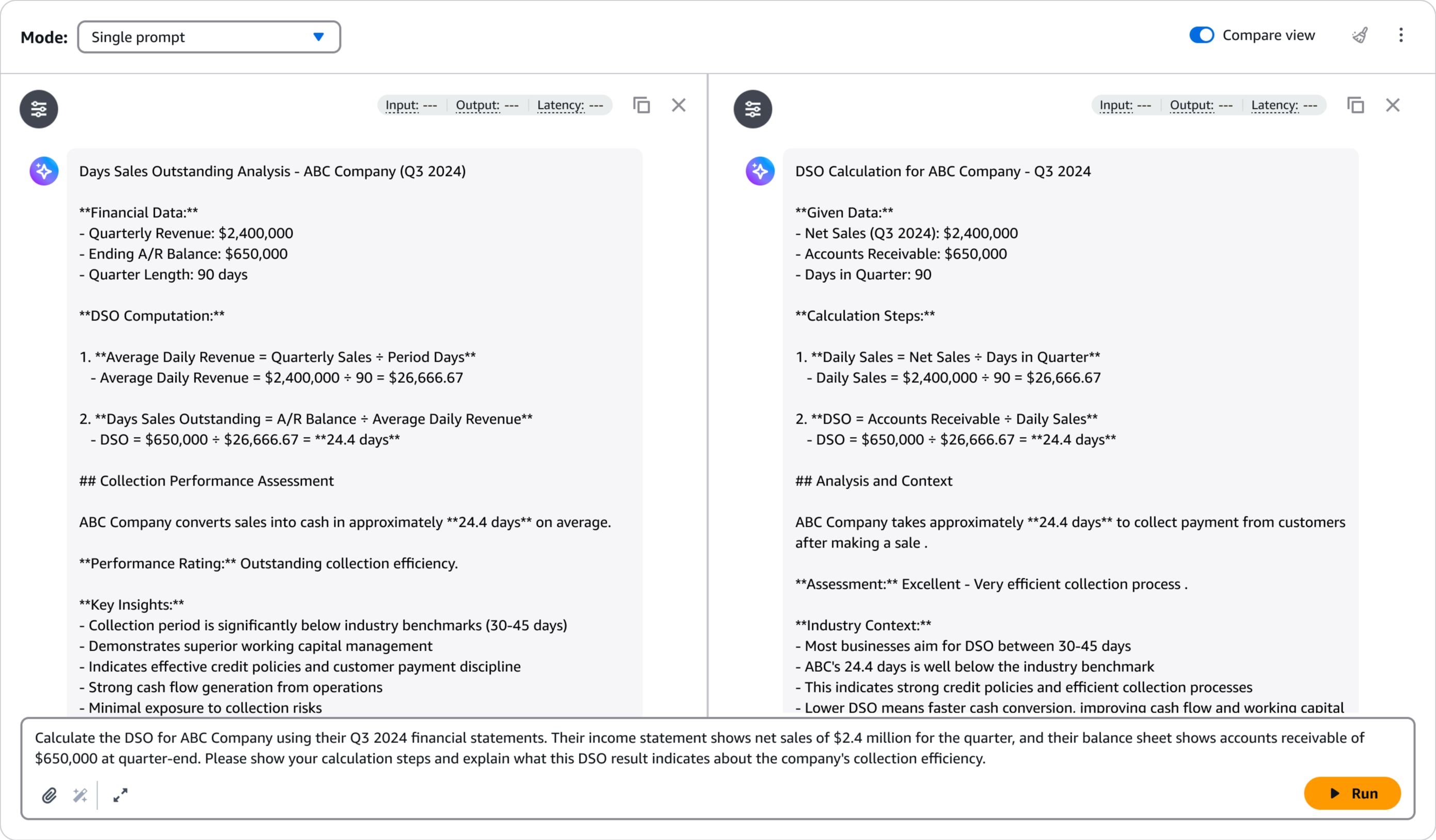
After deployment, I can rapidly consider the mannequin’s efficiency utilizing the Amazon Bedrock playground. This helps me to check the fine-tuned mannequin with pattern prompts and examine its responses in opposition to the bottom mannequin to validate the enhancements. I choose Take a look at in playground.
The playground gives an intuitive interface for fast testing and iteration, serving to me verify that the mannequin meets my high quality necessities earlier than integrating it into manufacturing purposes.
Interactive demo
Study extra by navigating an interactive demo of Amazon Bedrock reinforcement fine-tuning in motion.

Extra issues to know
Listed below are key factors to notice:
- Templates — There are seven ready-to-use reward operate templates masking widespread use circumstances for each goal and subjective duties.
- Pricing — To study extra about pricing, check with the Amazon Bedrock pricing web page.
- Safety — Coaching knowledge and customized fashions stay personal and aren’t used to enhance FMs for public use. It helps VPC and AWS KMS encryption for enhanced safety.
Get began with reinforcement fine-tuning by visiting the reinforcement fine-tuning documentation and by accessing the Amazon Bedrock console.
Glad constructing!
— Donnie