

{kind=link}
Onboard analytics workloads at scale with Amazon Redshift’s improved distant desk information definition language (DDL), materialized view enhancements, and concurrency scaling enhancements for zero-ETL and auto-copy.
As organizations scale their analytics capabilities, they want the power so as to add workloads with out disrupting manufacturing operation or being constrained by the sources of a single information warehouse. On this submit, we introduce new capabilities of Amazon Redshift that improve our multi-warehouse and scaling capabilities: distant materialized view (MV) operations, distant desk DDL assist, and concurrency scaling enhancements for zero-ETL and S3 occasion integration. These options provide help to construct extra scalable, performant decentralized analytics architectures on Amazon Redshift.
Allow us to evaluation how these new options allow you to run analytics at scale.
New distant materialized view operations
New distant desk DDL operations
ALTER TABLE ALTER DISTSTYLEoperations now work on distant warehouses by concurrency scaling and information sharing. You may dynamically optimize information distribution throughout distributed environments, bettering question efficiency and useful resource utilization with out requiring information migration. That is particularly worthwhile for information engineers fine-tuning efficiency throughout a number of warehouses and directors adapting to altering question patterns.ALTER TABLE APPENDoperations now lengthen to distant warehouses by concurrency scaling and information sharing. This consolidates information throughout distributed environments, so you’ll be able to effectively mix tables with out advanced information motion or extract, rework, and cargo (ETL) processes. Organizations managing dynamic desk operations throughout a number of environments can keep information consistency whereas lowering operational overhead.
Concurrency scaling enhancements
With these new concurrency scaling capabilities, you’ll be able to keep constant information freshness with out compromising current warehouse efficiency. This eliminates the standard trade-off between analytics and information loading. Other than turning on concurrency scaling, no further adjustments are required to benefit from these options.
Buyer use circumstances
This part covers two trade use circumstances: the primary for a monetary companies buyer and the second for a gaming trade buyer.
Monetary companies use case
The next is a pattern structure for a big monetary companies buyer with international operations. This buyer makes use of a multi-warehouse structure constructed on Amazon Redshift.
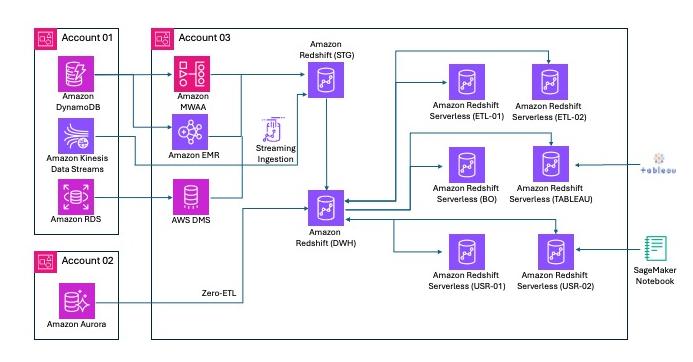
The staging (STG) warehouse serves as a uncooked zone for information from varied sources, just like the bronze layer of a medallion structure. This warehouse additionally cleanses and standardizes the uncooked information to the silver layer and makes it accessible for additional processing. The STG warehouse makes use of MVs to course of tens of millions of nested JSON messages and extract attributes into scalar columnar Amazon Redshift tables.
The DWH warehouse serves as the first Amazon Redshift occasion and gold layer, offering information to consuming functions like Enterprise Objects and Tableau. The zero-ETL concurrency scaling enhancements present constant information freshness even when zero-ETL ingestion spikes happen alongside heavy DWH workloads. The DWH MVs present quick entry to aggregated information for Tableau extracts and Enterprise Objects reside stories. The DWH warehouse takes benefit of concurrency scaling when a number of MVs should be refreshed on the DWH occasion.
The ETL01/02 warehouses function devoted compute environments for operating project-specific ETL jobs, whereas the USR01/02 warehouses deal with consumer workloads reminiscent of ad-hoc evaluation or mannequin constructing from dbt. When new objects are required by consumer workloads, they’re created and maintained on the distant producer warehouse (DWH).
Gaming trade use case
A number one gaming firm has constructed their total analytics infrastructure on AWS, with their analytics staff managing information streaming from video games, information warehousing, and enterprise intelligence instruments. They standardized Amazon Redshift throughout the group, migrating off Vertica operating on Amazon Elastic Compute Cloud (Amazon EC2). After overcoming early challenges with cluster resize operations, the staff grew to become sturdy advocates for Amazon Redshift and now runs their major manufacturing cluster on 32 ra3.16xlarge nodes.
As their information ingestion pipeline grew, question workloads started competing with information ingestion processes, creating efficiency bottlenecks. Relatively than scaling up their major cluster, they carried out a workload isolation technique utilizing Amazon Redshift information sharing. The client launched a second 16-node ra3.4xlarge cluster as an information share client, with the first cluster serving because the producer. This structure allowed them emigrate consumption workloads to the buyer cluster whereas the producer centered on information ingestion, successfully supporting development with out growing the first cluster measurement.
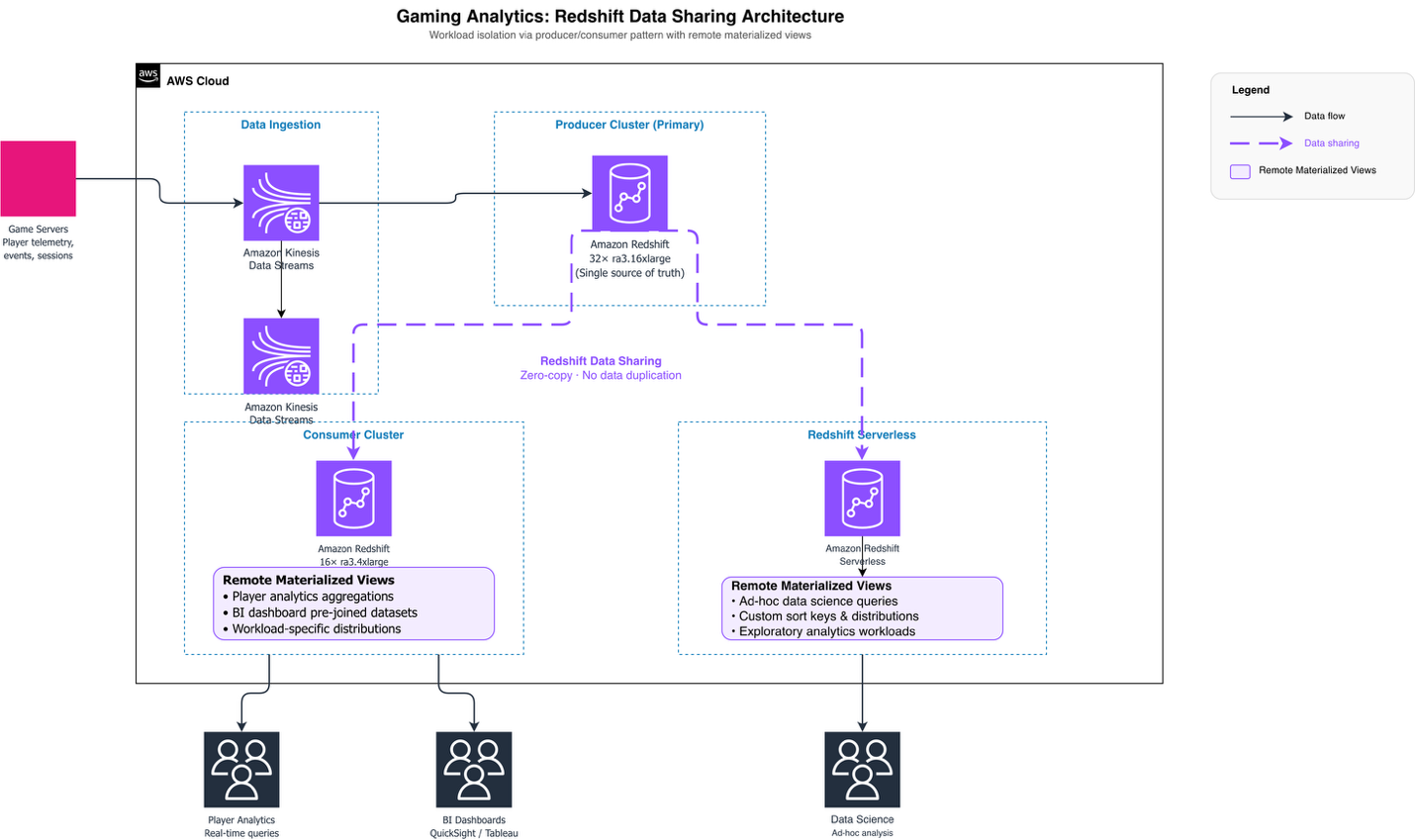
Recognizing the benefits of this distributed structure, the gaming firm expanded their method by migrating workloads to Amazon Redshift Serverless, additional utilizing the information sharing mannequin for workload isolation. Amazon Redshift’s distant materialized view functionality allowed the gaming firm to create materialized views immediately on the information shared by the producer cluster. Every client cluster may now construct materialized views optimized for its particular workload patterns. This created pre-aggregated datasets, customized be a part of methods, and workload-specific information distributions, with out impacting the producer cluster’s efficiency or requiring information duplication. The producer warehouse maintains information distribution and sorting methods designed for generic enterprise wants, offering constant information high quality throughout all shoppers. In the meantime, client warehouses used distant materialized views to fine-tune question efficiency for his or her distinct analytical necessities, whether or not supporting real-time participant analytics, enterprise intelligence dashboards, or ad-hoc information science workloads. This distributed method to information consumption optimization proved important for the gaming firm. It delivered quick question efficiency throughout various analytical workloads whereas sustaining a single supply of fact within the producer cluster and avoiding the operational overhead of managing redundant information copies.
Finest practices
To get probably the most out of those new capabilities, take into account the next greatest practices:
- Allow concurrency scaling in your Amazon Redshift clusters and Serverless workgroups to permit ETLs and consumer queries to run even sooner, offering constant report and dashboard efficiency.
- Arrange utilization limits for concurrency scaling on each Amazon Redshift provisioned clusters and Serverless workgroups by configuring an applicable
MaxRPUsetting. This helps you keep away from sudden further prices. For extra info, see the Amazon Redshift utilization limits documentation. - Use distant MVs to dump resource-intensive MV creation and refresh operations out of your major warehouse to distant information share clusters.
Conclusion
On this submit, we walked by the brand new MV refresh options, distant desk DDL capabilities, and expanded concurrency scaling assist for zero-ETL and S3 auto-copy. These options provide help to transfer past the constraints of a single warehouse. They’re significantly worthwhile for organizations managing distributed information architectures that require dynamic desk administration throughout a number of environments whereas sustaining information consistency and adapting shortly to altering workloads. To get began, ensure you are operating the newest Amazon Redshift model. Then go to the Amazon Redshift documentation to be taught extra about concurrency scaling, information sharing, and materialized views.
Concerning the authors