

{kind=link}
A part of Flutter Leisure, the world’s largest on-line sports activities betting and iGaming operator, tombola is the world’s largest on-line bingo neighborhood and has been utilizing Amazon Redshift to run its knowledge analytics workloads. Based in Sunderland, UK, the corporate traces its roots to the Fifties, when it started printing bingo tickets through the golden age of the sport. tombola launched on-line in 2006 and has since expanded to Italy, Spain, Denmark, and Sweden. The corporate builds all of its video games in-house, holds essentially the most prestigious Safer Playing award, and just lately partnered with Flutter sibling model Sisal to deliver its bingo software to Italian gamers.
On this submit, you learn the way tombola adopted a strict engineering precept: no adjustments to manufacturing with out proof. That meant a head-to-head comparability of RA3 versus RG on their precise workload. You additionally see benchmark outcomes on Amazon S3 Tables and the migration from RA3 to RG cases.
Present knowledge structure
Amazon Redshift sits on the middle of tombola’s knowledge structure. The manufacturing cluster runs on RA3 nodes and serves a number of schemas with lots of of tables, supporting each analytical workload the enterprise runs, from sub-second software lookups to multi-minute extract, rework, load (ETL) transforms. What makes tombola’s Amazon Redshift workload distinctive is the breadth of what flows by it. Amazon Managed Workflows for Apache Airflow (Amazon MWAA) DAGs orchestrate pipelines throughout over 14 enterprise domains, together with segmentation, fraud detection, advertising, finance, and SafePlay responsible-gaming. Configuration-driven ingestion pipelines land knowledge from SQL Server, Amazon DynamoDB, Amazon OpenSearch Service, Postgres, and exterior APIs into Bronze and Silver layers on Amazon Easy Storage Service (Amazon S3), earlier than loading it into Amazon Redshift. From there, over 250 dbt fashions operating on Amazon Elastic Container Service (Amazon ECS) rework the info into analytical gold layers. Outputs feed a number of downstream shoppers: Amazon SageMaker for fraud scoring and churn prediction, Amazon DynamoDB for low-latency APIs, and region-specific pipelines spanning the UK, Italy, Spain, Denmark, and Sweden. As the appliance grew, with extra domains, extra DAGs, and extra concurrent customers, the workforce started evaluating methods to scale back steady-state question latency and decrease compute price with out rearchitecting the system. When AWS made Graviton-powered RG nodes accessible for Amazon Redshift, the timing was proper.
Benchmark efficiency outcomes
The benchmark infrastructure was absolutely outlined as infrastructure as code (IaC), ensuring each take a look at run was reproducible. The workforce deployed two take a look at benchmark clusters (one RA3 and one RG) in a like-for-like configuration. They mirrored the settings (Amazon Digital Personal Cloud (Amazon VPC), safety teams, AWS Key Administration Service (AWS KMS), AWS Id and Entry Administration (IAM) roles, and parameter teams) from the manufacturing atmosphere to take away configuration drift. The benchmark runner was containerized as an Amazon ECS process (python:3.11-slim-bookworm ARM64 base), offering repeatable, remoted execution for every take a look at spherical. Benchmark workloads had been chosen by analyzing manufacturing cluster logs and metrics, then categorized into three tiers:
- Heavy: ETL queries with multi-table CTE chains, full-table scans, and aggregation home windows.
- Medium: Enterprise intelligence (BI) queries driving reporting and analytics dashboards.
- Gentle: Utility queries with sub-second response occasions.
Structure
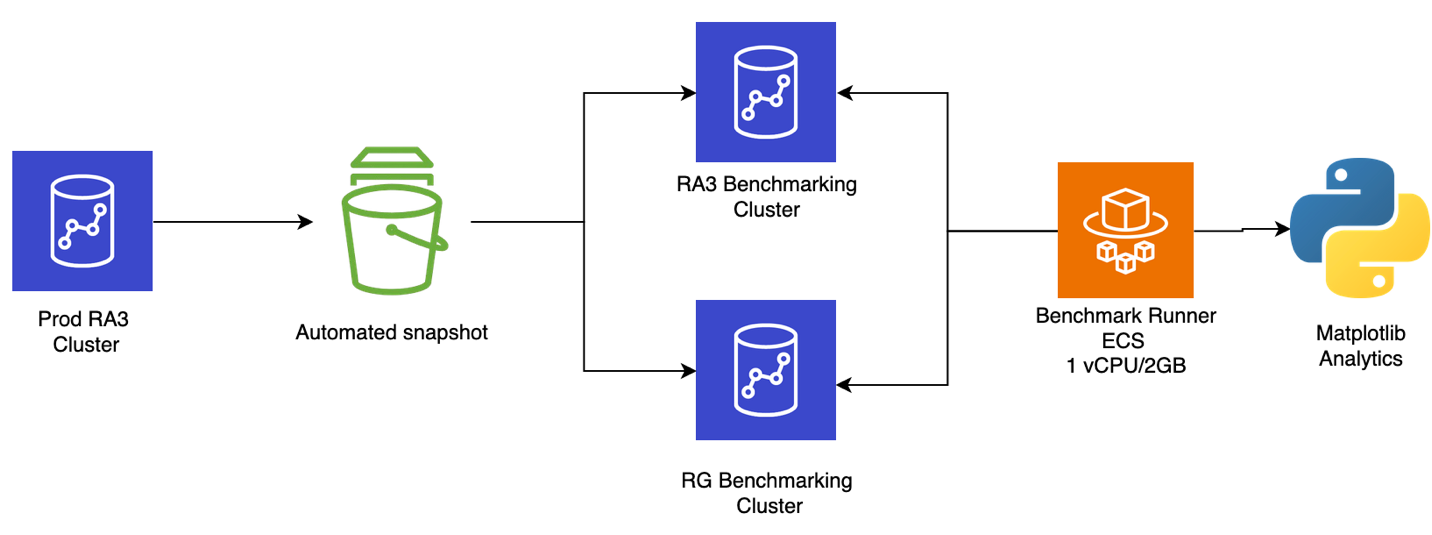
Situations examined
To validate the efficiency of Graviton-powered RG cases in opposition to the prevailing RA3 nodes, tombola designed 4 benchmark eventualities that progressively improve in complexity and realism. Collectively, these eventualities present a complete view of efficiency from remoted question execution by to sustained, real-world analytical workloads.
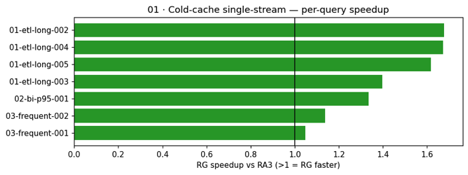
Situation 01: Chilly-cache, single-stream execution. This situation isolates uncooked compute efficiency by operating queries in opposition to a chilly cache in a single stream, avoiding caching and concurrency as variables.
Per-query speedups ranged from 1.05× (mild lookup queries) to 1.68× (heavy ETL transforms). Zero errors on each clusters (28 makes an attempt every).
| Weight Class | RA3 p50 (ms) | RG p50 (ms) | Speedup |
| Heavy (ETL) | 210,372 | 133,855 | 1.57× |
| Medium (BI) | 2,193 | 1,642 | 1.34× |
| Gentle (App) | 3.20 | 2.76 | 1.16× |
The next chart reveals per-query speedup ratios for the cold-cache situation. Heavy ETL queries (left) present the biggest positive aspects, with speedups of 1.57–1.68×, and lighter queries nonetheless profit at 1.05–1.16×. The sample is constant: RG’s benefit scales with question complexity.
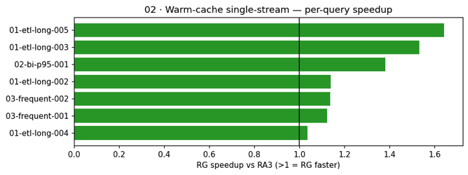
Situation 02: Heat-cache, single-stream execution. This situation repeats Situation 01 with the outcome cache enabled to substantiate that RG maintains its latency benefit even when cached outcomes are in play.
Per-query speedups ranged from 1.04× to 1.64×. Zero errors on each clusters (35 makes an attempt every).
| Weight Class | RA3 p50 (ms) | RG p50 (ms) | Speedup |
| Heavy (ETL) | 93,636 | 61,691 | 1.52× |
| Medium (BI) | 2,189 | 1,584 | 1.38× |
| Gentle (App) | 3.08 | 2.58 | 1.19× |
With outcome caching enabled, the speedup sample holds for non-cached queries. Cache hits on each clusters land in 118–185 ms, confirming the caching subsystem operates identically no matter node kind. The RG benefit seems completely on execution paths that bypass the cache.
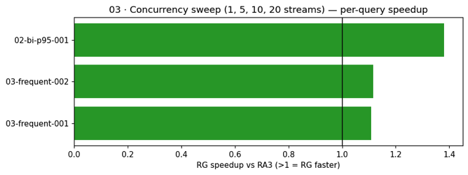
Situation 03: Concurrency sweep. This situation introduces parallel load by sweeping by 1, 5, 10, and 20 concurrent streams, testing how every node kind handles competition and queuing below stress.
Each clusters used the identical Concurrency Scaling configuration (max_concurrency_scaling_clusters=1, WLM-only). RG accomplished 482 extra queries in the identical wall-clock window.
| Metric | RA3 | RG | Enchancment |
| Complete queries accomplished | 1,438 | 1,920 | +33% throughput |
| Gentle p50 (ms) | 3.44 | 3.04 | 1.13× |
| Medium p50 (ms) | 20,784 | 15,055 | 1.38× |
| Errors | 0 | 0 | — |
Beneath growing parallel load (1, 5, 10, and 20 concurrent streams), RG maintained decrease latencies and accomplished 33 % extra queries in the identical wall-clock window. Each clusters used the identical Concurrency Scaling configuration, so the throughput distinction is attributable to per-node compute effectivity.
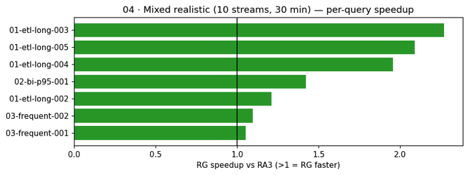
Situation 04: Blended real looking workload. This situation combines the earlier components right into a blended real looking workload, operating 10 streams concurrently for half-hour with a weighted distribution of heavy, medium, and lightweight queries to simulate precise manufacturing situations.
This situation greatest simulates manufacturing. The headline discovering: heavy ETL queries noticed speedups of as much as 2.27× below concurrent load, and RG accomplished 46 % extra whole queries in the identical 30-minute window. Zero errors on each clusters.
| Metric | RA3 | RG | Enchancment |
| Complete queries accomplished | 405 | 593 | +46% throughput |
| Heavy p50 (ms) | 1,186,572 | 642,294 | 1.85× |
| Medium p50 (ms) | 2,319 | 1,631 | 1.42× |
| Gentle p50 (ms) | 3.12 | 2.90 | 1.08× |
| Errors | 0 | 0 | — |
The mixed-realistic situation greatest simulates manufacturing. Beneath 10 concurrent streams over half-hour, heavy ETL queries confirmed speedups of as much as 2.27×. RG’s per-vCPU throughput benefit compounds below competition, precisely the situation the place manufacturing clusters spend most of their time.
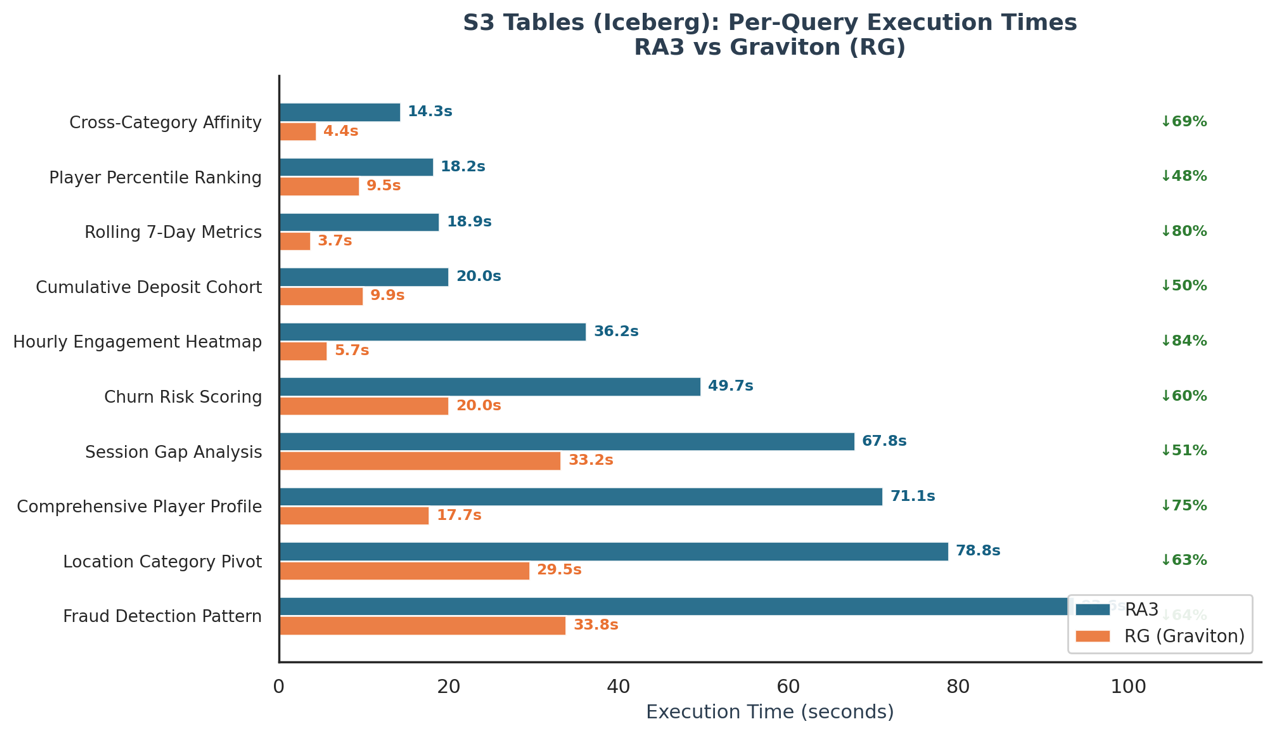
Prolonged benchmark: Amazon S3 Tables (Iceberg) efficiency
tombola’s future knowledge structure will combine with brokers and revolves round Apache Iceberg, backed by Amazon S3 Tables. Amazon S3 Tables supply Amazon S3 storage that’s particularly tuned for analytics, with built-in capabilities that maintain making queries quicker and serving to decrease storage prices for desk knowledge. They’re purpose-built to carry tabular datasets, akin to day by day buy logs, streaming sensor readings, or advert impression occasions. On this mannequin, knowledge is organized into rows and columns, just like how data is structured in a conventional database desk. With that route in thoughts, tombola additionally benchmarked Graviton’s efficiency querying Iceberg tables instantly. The dataset consists of participant profiles, sport session historical past, and geolocation knowledge: a mixture of huge tables and high-cardinality columns that stress each compute and I/O.
To guage efficiency throughout totally different eventualities, tombola generated queries at various ranges of complexity. Medium queries contain customary analytical features like rating and aggregation, and Medium-Excessive queries introduce multi-step transformations with joins and cumulative calculations. On the Excessive tier, queries mix distinct counting, conditional pivoting, and time-window aggregations. Very Excessive queries are essentially the most demanding: self-joins throughout the complete dataset, multi-signal scoring logic, and superior statistical features. This tiered strategy captures how every node kind performs as computational calls for improve.
As with the earlier benchmarks, the workforce saved the take a look at as comparable as doable: a real like-for-like analysis between RG (powered by Graviton) and RA3 nodes of equal dimension.
Testing was break up into two phases:
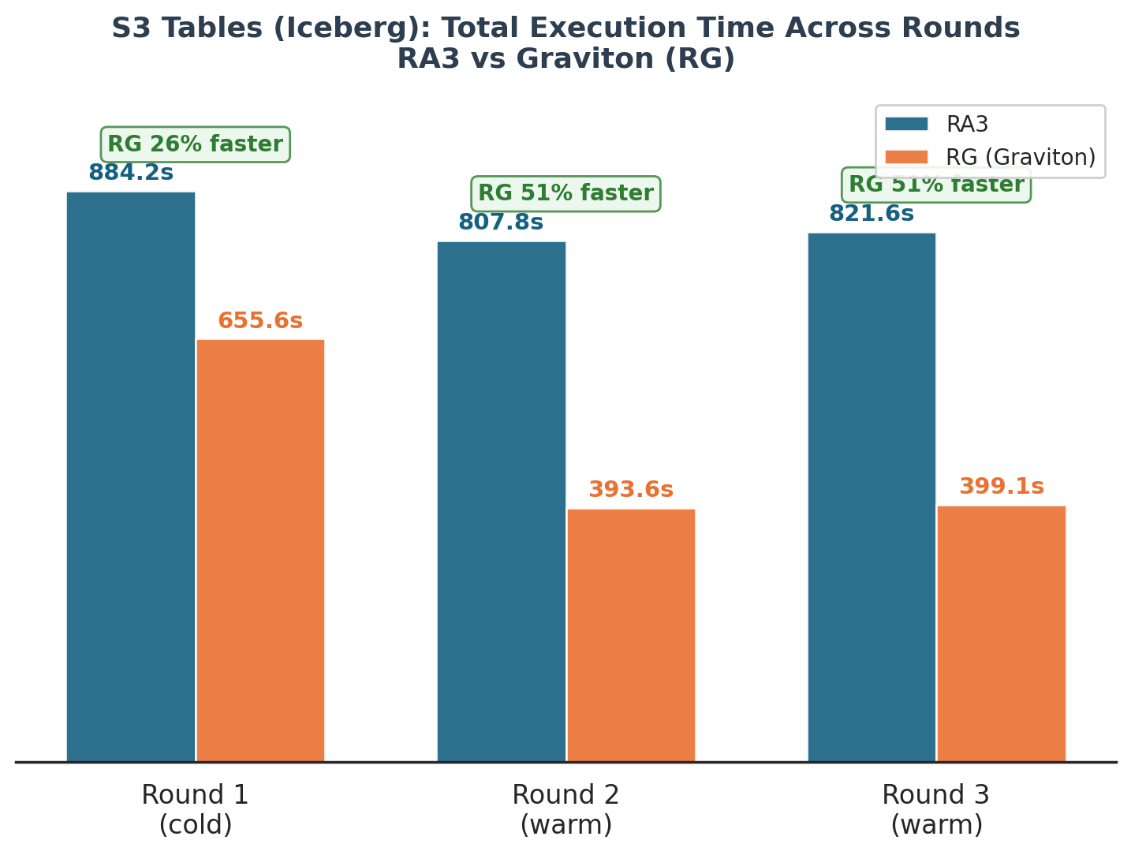
Part 1: Concurrency. All queries had been submitted concurrently to measure how effectively every node kind handles concurrent workloads. The objective was to know throughput variations: how rather more work RG nodes can push by below stress in comparison with equally sized RA3 nodes.
All queries had been run concurrently throughout a number of rounds:
Part 2: Sequential execution. Every question was run in isolation with full compute sources accessible. This eliminated concurrency as a variable and gave a clear learn on uncooked question efficiency. The outcomes had been clear: RG outperformed RA3 throughout a number of question sorts, exhibiting constant positive aspects when given devoted compute.
In sequential execution, Graviton (RG) delivered constant efficiency positive aspects throughout all question complexity ranges: Medium-complexity queries ran 45–73 % quicker (common 58 %), Medium-Excessive queries improved by 42 %, Excessive-complexity queries achieved 57–66 % quicker execution (common 62 %), and Very Excessive-complexity queries noticed positive aspects of 60–67 % (common 63 %). The outcomes show that RG’s benefit scales with workload complexity, delivering the biggest enhancements on essentially the most demanding analytical queries.
tombola’s modernization strategy
tombola is modernizing its Amazon Redshift cluster utilizing the Elastic Resize path to alter from RA3 to RG node sorts. The operation snapshots the prevailing cluster, provisions a brand new RG cluster from that snapshot, and transfers knowledge within the background. Throughout this switch interval, the supply cluster stays accessible in read-only mode. When the resize nears completion, Amazon Redshift mechanically updates the endpoint to level to the brand new RG cluster and drops connections to the supply. The workforce selected this strategy as a result of it aligns with their engineering precept of evidence-based adjustments: no manufacturing cutover with out proof. The benchmark outcomes, with zero errors throughout all eventualities in opposition to production-representative workloads, offered the boldness wanted to proceed. After the resize is full, the exterior tables, schemas, and question syntax stay unchanged. With RG’s built-in knowledge lake question engine, tombola additionally removes its dependency on Amazon Redshift Spectrum. Knowledge lake queries now run instantly on cluster nodes inside the Amazon VPC boundary, utilizing current IAM roles, with zero per-TB scanning prices.
Conclusion
The benchmark outcomes make a compelling case for migrating tombola’s Amazon Redshift infrastructure from RA3 (Intel Xeon) to RG (Graviton4) cases. Throughout each situation examined, RG delivered vital and constant efficiency positive aspects:
- Chilly-cache efficiency: 1.57× quicker on heavy ETL queries, with per-query speedups as much as 1.68×.
- Heat-cache efficiency: 1.52× quicker on heavy workloads, sustaining benefit even with outcome caching enabled.
- Concurrency: 33 % greater throughput below parallel load, with RG sustaining decrease latencies as streams elevated from 1 to twenty.
- Blended real looking workload: 1.85× quicker on heavy ETL queries and 46 % extra whole queries accomplished, the situation closest to manufacturing site visitors patterns.
- Amazon S3 Tables (Iceberg): As much as 51 % quicker below concurrent load and 57 % quicker in sequential execution, vital for tombola’s future lakehouse structure.
Past uncooked efficiency, RG delivers architectural advantages that align with tombola’s strategic route. The built-in knowledge lake question engine removes Amazon Redshift Spectrum overhead and per-TB scan prices. The 4:3 node mapping (4 ra3.4xlarge nodes to three rg.4xlarge nodes) reduces infrastructure prices by 25 %.
Based mostly on these outcomes, tombola are modernizing their manufacturing Amazon Redshift cluster to Graviton4-based RG cases. The work has already began and comparable outcomes as above are seen. The prevailing RA3 options, together with concurrency scaling, knowledge sharing, and system views, are absolutely supported on RG. This positions tombola to deal with rising knowledge volumes and consumer concurrency with higher efficiency, higher price effectivity, and a predictable pricing mannequin as the appliance scales.
The outcomes and advantages described on this submit are particular to tombola’s workload and atmosphere. Though Amazon Redshift RG cases powered by AWS Graviton4 processors can ship vital efficiency enhancements, precise outcomes will differ based mostly on elements together with workload traits, knowledge volumes, cluster configuration, and question complexity. We encourage you to guage RG cases with your personal workloads to find out the advantages in your atmosphere. To study extra, go to the Amazon Redshift advertising web page and the Amazon Redshift documentation, or get began within the Amazon Redshift console.
In regards to the authors