

{kind=link}

|
Immediately, we’re saying a brand new metadata functionality for Amazon Easy Storage Service (Amazon S3) known as annotations, enabling you to connect wealthy, large-scale enterprise context on to your objects. You may retailer as much as 1,000 named annotations per object, every as much as 1 MB in measurement, totaling as much as 1 GB per object, in versatile codecs like JSON, XML, YAML, or plain textual content. You may modify or delete an annotation at any time, with out re-writing your objects, making it simple to maintain your object context present.
Organizations are constructing AI brokers and autonomous workflows that want to search out, perceive, and act on knowledge with out human intervention. To help these agentic workflows, you want metadata that may evolve alongside the info, scale to petabytes of objects, and stay queryable with out costly retrieval.
With S3 annotations, you may retailer context equivalent to AI-generated transcripts, content material rankings, or technical specs immediately alongside your objects. Your context strikes routinely with the article throughout copy, replication, and cross-region transfers, and S3 removes it once you delete the article. Once you allow S3 Metadata, annotations routinely move into totally managed annotation tables you can question with Amazon Athena and different analytics engines.
Widespread use circumstances
Annotations clear up advanced metadata challenges throughout industries:
- Media & Leisure: Monitor transcripts, content material moderation outcomes, subtitle recordsdata, and licensing metadata as separate annotations on video belongings, eliminating the necessity to synchronize metadata throughout a number of media asset administration techniques.
- Monetary Providers: Connect AI-generated funding summaries and sentiment evaluation to analysis paperwork, enabling autonomous analysis brokers to find related datasets by means of natural-language queries with out sustaining separate metadata databases.
- Life Sciences: Annotate scientific trial knowledge with regulatory standing, affected person cohort particulars, and approval chains, making compliance audits quicker whereas protecting full context accessible for archived knowledge in Amazon S3 Glacier storage lessons with out retrieval prices.
How annotations deal with metadata challenges
Amazon S3 already helps a number of methods to explain your objects. System-defined metadata captures properties like measurement and storage class. Object tags help operational duties like entry management and lifecycle administration. Person-defined metadata helps you to add small quantities of customized data at add time.
Whereas these capabilities work nicely for his or her meant functions, they’ve limitations when you might want to connect a lot richer context with out constructing and sustaining separate metadata techniques. Annotations deal with these wants by offering metadata capabilities at a essentially totally different scale and suppleness, providing mutable, queryable context per object in comparison with 10 immutable tags or 2 KB of headers.
| Functionality | Max measurement | Mutable? | Finest for |
| System-defined metadata | Mounted | No | Object properties (measurement, storage class, creation time) |
| Person-defined metadata | 2 KB | No (set at add) | Small customized key-value pairs |
| Object tags | 10 tags, 128/256 characters per key/worth | Sure | Entry management, lifecycle guidelines, price allocation |
| Annotations | 1 GB (1,000 × 1 MB) | Sure | Wealthy enterprise context (JSON, XML, YAML, plain textual content) |
Immediately, metadata describing S3 objects usually lives in separate databases or sidecar recordsdata, requiring advanced synchronization workflows that may exceed knowledge storage prices. Once you allow S3 Metadata annotation tables, this context turns into queryable at scale by means of Amazon Athena. AI brokers can uncover your knowledge by means of pure language with the S3 Tables MCP server, which supplies a standardized interface for AI fashions to question your annotations. You may question annotations for objects in any storage class, with out restoring the objects or paying retrieval prices.
Getting began with annotations
To begin utilizing annotations, be certain that your AWS Id and Entry Administration (IAM) coverage or bucket coverage grants permissions for the s3:PutObjectAnnotation and s3:GetObjectAnnotation actions. You may then add annotations to any present or new S3 object utilizing the PutObjectAnnotation API.
For instance, a media firm can connect technical specs and AI-produced summaries to a video asset utilizing the AWS Command Line Interface (AWS CLI):
# Create a JSON file with technical metadata
cat > mediainfo.json << 'EOF'
{"codec":"H.265","decision":"3840x2160","audio_tracks":8,"frame_rate":29.97}
EOF
# Connect it as an annotation
aws s3api put-object-annotation
--bucket my-media-bucket
--key movies/documentary-2026.mp4
--annotation-name mediainfo
--annotation-payload ./mediainfo.json
# Connect a plain-text AI-generated abstract as a separate annotation
echo "A 90-minute nature documentary overlaying wildlife migration patterns throughout three continents, that includes aerial footage and underwater sequences. Languages: English, Spanish, Portuguese." > ai_summary.txt
aws s3api put-object-annotation
--bucket my-media-bucket
--key movies/documentary-2026.mp4
--annotation-name ai_summary
--annotation-payload ./ai_summary.txt
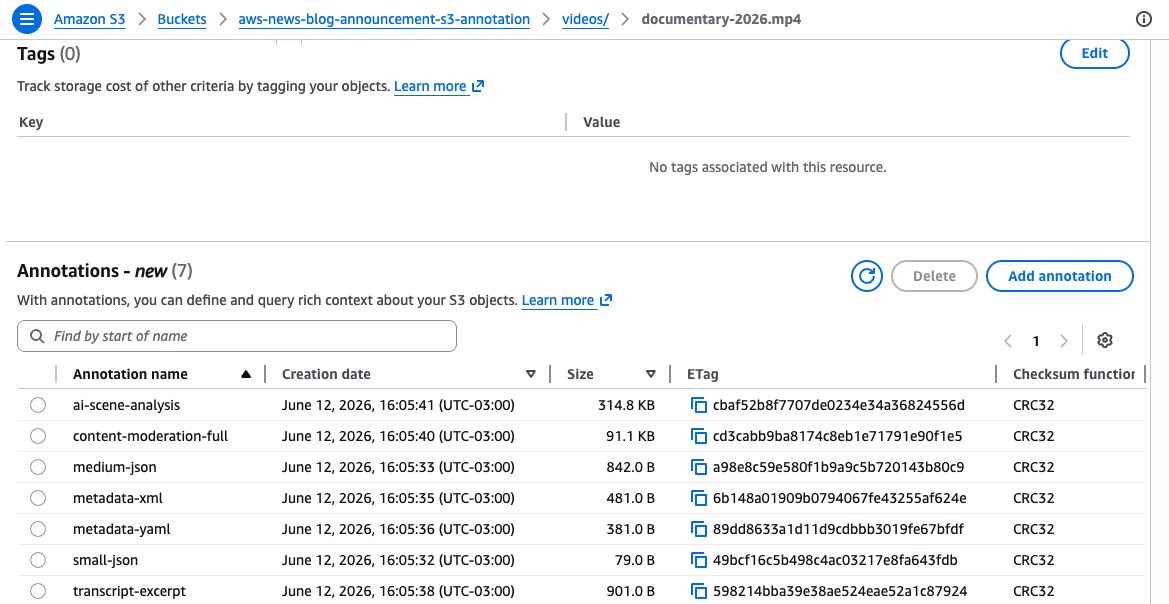
These instructions connect two separate annotations to the identical video object. The mediainfo annotation shops structured technical specs as JSON, whereas the ai_summary annotation shops a textual content description. Every annotation is recognized by a novel identify, and you may learn and modify each independently. With distinctive names for every annotation, you should use totally different annotations to help a number of concurrent enrichment workflows, for instance, one workforce including technical metadata whereas one other workforce provides content material classifications, with out interfering with one another.
Retrieve a selected annotation utilizing the GetObjectAnnotation API:
aws s3api get-object-annotation
--bucket my-media-bucket
--key movies/documentary-2026.mp4
--annotation-name mediainfo
./mediainfo-output.json
To see all annotations hooked up to an object, use the ListObjectAnnotations API:
aws s3api list-object-annotations
--bucket my-media-bucket
--key movies/documentary-2026.mp4
Once you not want a selected annotation, take away it utilizing the DeleteObjectAnnotation API:
aws s3api delete-object-annotation
--bucket my-media-bucket
--key movies/documentary-2026.mp4
--annotation-name mediainfo
You may replace an present annotation at any time by calling PutObjectAnnotation once more with the identical annotation identify. For giant objects uploaded utilizing multipart add, connect annotations after finishing the multipart add utilizing the PutObjectAnnotation API.
Querying annotations at scale with S3 Metadata tables
Attaching annotations to particular person objects is helpful, however the actual energy comes once you question throughout all of your annotations at scale. Once you allow S3 Metadata annotation tables in your bucket, S3 routinely indexes your annotations into a completely managed Apache Iceberg desk, known as an annotation desk. You may question annotation tables with Amazon Athena or any Iceberg-compatible engine.
To allow annotation tables, use the S3 console or the CreateBucketMetadataConfiguration API. The next instance creates a brand new metadata configuration with annotation tables enabled whereas protecting journal tables for change monitoring and disabling the stay stock desk:
{
"JournalTableConfiguration": {
"RecordExpiration": { "Expiration": "DISABLED" }
},
"InventoryTableConfiguration": { "ConfigurationState": "DISABLED" },
"AnnotationTableConfiguration": {
"ConfigurationState": "ENABLED",
"Position": "arn:aws:iam::123456789012:position/S3MetadataAnnotationRole"
}
}
This configuration tells S3 to routinely seize all of your annotations in a queryable desk. As soon as utilized, any annotation you connect to things on this bucket will seem within the desk inside roughly one hour.
If the bucket already has a metadata configuration, use the UpdateBucketMetadataAnnotationTableConfiguration API:
aws s3api update-bucket-metadata-annotation-table-configuration
--bucket my-media-bucket
--annotation-table-configuration '{"ConfigurationState":"ENABLED","Position":"arn:aws:iam::123456789012:position/S3MetadataAnnotationRole"}'
As soon as enabled, your annotations routinely move into the annotation desk. Journal tables replace in close to actual time, whereas annotation tables refresh inside an hour. In contrast to conventional metadata tables that require predefined schemas, annotation tables routinely adapt to any JSON, XML, or YAML construction you write. Every annotation turns into a row within the desk with its content material saved in a text_value column, letting you question throughout all annotations with out schema migrations.
In case you allow annotation tables on a bucket that already has annotated objects, S3 routinely backfills present annotations into the desk. The backfill course of runs within the background and might take a number of hours to days relying on the variety of objects.
For instance, to search out all video belongings with greater than 8 audio tracks throughout your complete bucket utilizing Amazon Athena:
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE identify="mediainfo"
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8
This question scans the annotation desk for all annotations named mediainfo, extracts the audio_tracks discipline from the JSON content material, and returns objects the place the depend exceeds 8.
Or to search out all objects that obtained new annotations within the final 24 hours by means of the journal desk:
SELECT bucket, key, version_id, record_timestamp, annotation.identify
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."journal"
WHERE record_timestamp >= (current_date - interval '1' day)
AND annotation.identify IS NOT NULL
AND record_type IN ('CREATE_ANNOTATION', 'DELETE_ANNOTATION')
This question makes use of the journal desk to trace annotation adjustments in close to actual time, which is good for constructing event-driven workflows that reply to new or deleted annotations.
You too can use pure language to look objects by their annotations utilizing brokers in Amazon SageMaker Unified Studio or any IDE with the S3 Tables MCP server. For instance, asking “discover all PG-rated motion pictures with Spanish subtitles from 2023” returns ends in seconds as a substitute of the hours it might take querying a number of disconnected techniques.
Get began right this moment
You can begin utilizing Amazon S3 annotations right this moment in all AWS Areas, together with the AWS China Areas. Annotation tables can be found in all AWS Areas the place S3 Metadata is on the market.
Whether or not you’re constructing AI brokers that want to find knowledge autonomously, managing petabytes of media belongings with advanced metadata, or monitoring compliance context for archived datasets, annotations provide the scale and suppleness to connect wealthy metadata on to your objects with out managing separate techniques.
Annotation storage is at all times billed at S3 Customary charges, even when the guardian object is in S3 Glacier or one other storage class. For full pricing particulars, go to the Amazon S3 pricing web page.
To study extra and get began, go to the Amazon S3 Metadata overview web page and the Amazon S3 documentation. Ship suggestions to AWS re:Publish for S3 or by means of your normal AWS Help contacts.
Daniel Abib