

{kind=link}
With particular due to Arkaprabho Ghosh and David Reed.
As AI continues to remodel the enterprise panorama, the problem for big organizations isn’t simply adopting the know-how—it’s scaling it successfully. At Cisco, we acknowledged that whereas our groups have been keen to construct Retrieval-Augmented Technology (RAG) functions, the method was typically fragmented. Builders have been spending months stitching collectively completely different parts of a RAG pipeline—similar to loaders, splitters, embedding fashions, and vector databases. Every part carried its personal studying curve and operational overhead. The burden of evaluating an amazing variety of open-source instruments and endlessly experimenting with numerous configurations to search out the correct match for particular use instances finally led to inconsistent requirements, technical debt, and widespread “know-how fatigue”.
To unravel this, Cisco IT created DRIFT (Doc Retrieval and Ingestion Framework Toolkit), a standardized, scalable platform that helps fast improvement and experimentation in RAG workflows with the power to scale to satisfy enterprise-standard workloads.
Simplifying the AI Journey
DRIFT was constructed with a easy premise: software groups ought to give attention to constructing AI-first experiences and enterprise logic, not on the heavy lifting of infrastructure. We’re eradicating the limitations to entry by offering a platform that handles the complexity of knowledge pipeline orchestration, permitting groups to fast-track their AI journey with out the necessity for intensive ramp-up time on underlying, complicated applied sciences.
Whether or not you’re a hard-core developer requiring deep API-level management or a enterprise consumer on the lookout for an intuitive interface, DRIFT offers a real end-to-end improvement and experimentation setting.
The Cisco-on-Cisco Benefit: Constructed for Scale & Safety
DRIFT is a robust instance of the Cisco-on-Cisco benefit—the place Cisco software program is constructed to run on Cisco’s personal AI infrastructure. Constructed on a cloud-native microservices structure and deployed on Kubernetes, DRIFT is engineered for agility, resilience, and enterprise-scale efficiency. Its asynchronous ingestion and file add structure is designed to deal with massive volumes of enterprise information effectively, enabling high-throughput pipelines with out sacrificing reliability.
On the coronary heart of this basis are Cisco AI PODs powered by Cisco UCS-C885A {hardware}. This provides DRIFT the high-performance compute spine wanted for demanding AI workloads similar to inferencing, embeddings, and reranking. By working on-premise throughout a number of Cisco Information Facilities, DRIFT combines scale, sturdy safety, excessive availability, and operational management in a approach that meets the wants of enterprise AI.
The result’s greater than only a trendy AI platform—it’s a clear demonstration of how Cisco AI software program and Cisco AI infrastructure come collectively to ship production-ready efficiency at scale. With DRIFT working on Cisco AI PODs constructed on UCS-C885A, Cisco is showcasing an end-to-end AI stack that’s scalable, safe, and purpose-built for enterprise innovation.
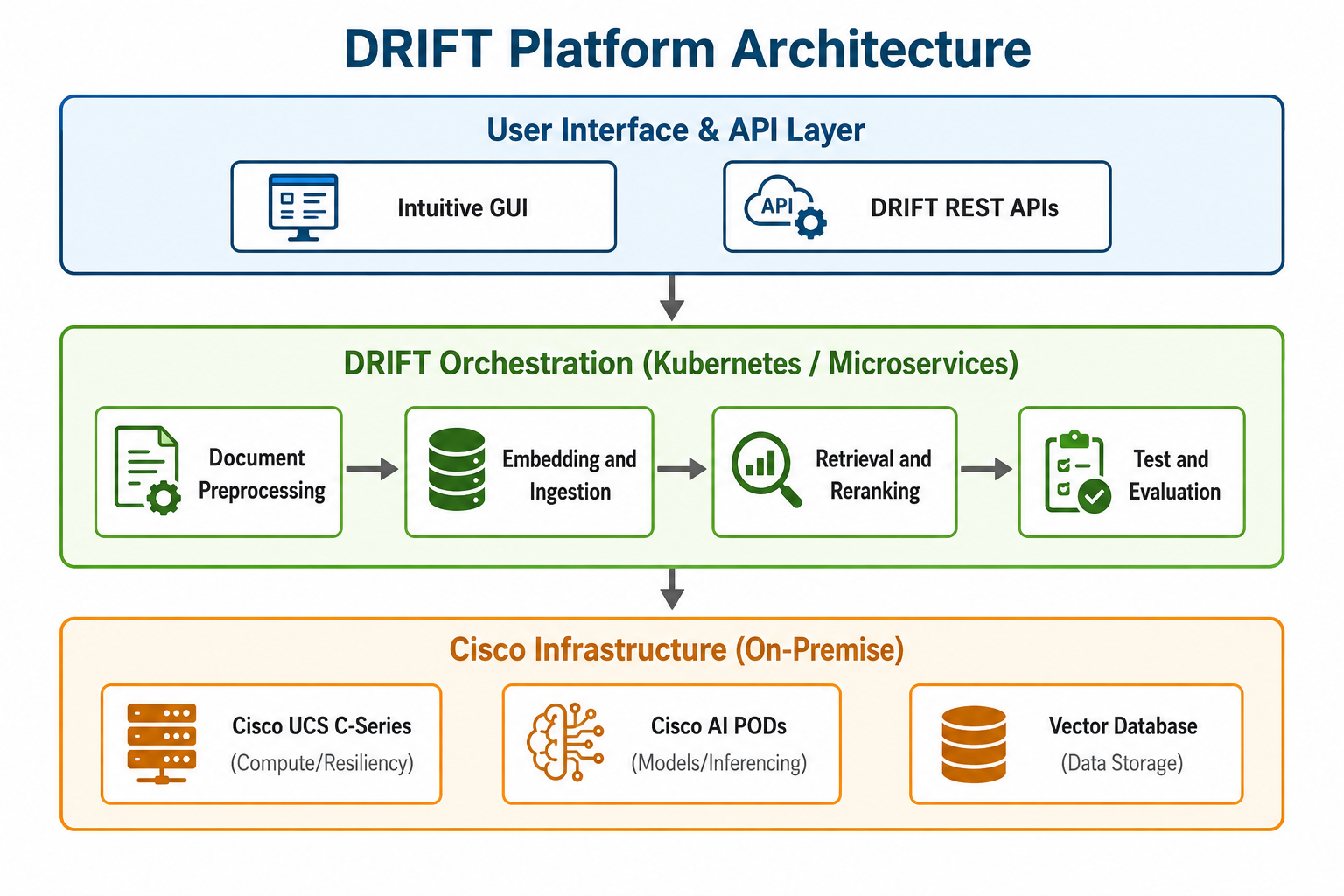
The DRIFT Methodology: Powering Safe RAG
DRIFT streamlines the trail from uncooked doc to clever assistant by a sturdy, modular pipeline structure:
- Doc Preprocessing: We help various doc sources and codecs, standardizing various enterprise information right into a constant, model-ready format. We even leverage Imaginative and prescient Language Fashions (VLM) to transform pictures inside paperwork into textual content representations.
- Clever Splitting and Hybrid Processing: DRIFT helps a wide range of splitting algorithms, together with the power to protect a doc’s structural formatting throughout the splitting course of. For paperwork with combined content material, it additionally allows a hybrid method that selectively processes pictures—serving as a extremely efficient value optimization method.
- Embedding and Ingestion: Groups can select from a set of normal embedding fashions or deliver their very own. We provide seamless integration with each shared multi-tenant in addition to devoted Vector databases to go well with a wide range of enterprise use instances. Our platform helps each key phrase and semantic search algorithms, guaranteeing environment friendly ingestion and retrieval that meet enterprise SLAs.
- Retrieval and Reranking: DRIFT permits for configurable hybrid search and metadata filtering, guaranteeing that retrieved information is exact. Our reranking capabilities additional refine outcomes based mostly on relevance, considerably growing accuracy.
- Adaptive Structure: Designed for the longer term, DRIFT helps evolving use instances, together with Agentic RAG and Graph RAG, guaranteeing enterprise functions can scale as AI architectures advance.
- Constructed-in Testing and Analysis: Builders can take a look at retrievers in opposition to pattern queries and work together with LLMs immediately inside the platform to validate generative summaries earlier than deployment.
Why is DRIFT a Sport-Changer:
- API-First Structure: DRIFT was constructed from the bottom up with an API-first method. We offer complete, ready-to-use APIs for each step of the lifecycle—together with doc add, ingestion, retrieval, and configuration—enabling seamless integration into present enterprise functions and workflows.
- Full Transparency and Experimentation: We’ve got moved away from the “black-box” method to a real end-to-end improvement and experimentation platform that empowers builders with full visibility. Groups have full management over configuration selections for all parts of their pipelines, permitting them to fine-tune, take a look at, and optimize for optimum accuracy.
- Curated, Accountable AI: We eradicate the guesswork of evaluating open-source libraries. DRIFT offers fashions which might be already vetted and accredited by Cisco’s Accountable AI (RAI) and governance groups.
- Decreased Know-how Fatigue: By offering a curated suite of industry-standard parts, we save groups from “evaluation paralysis.” We deal with the combination to allow them to give attention to innovation.
- Flexibility and Scalability: Whereas we offer customary, high-quality choices, DRIFT stays absolutely versatile. Groups can combine their very own customized Vector Databases or fine-tuned fashions—similar to these specialised for Cisco-specific monetary or technical terminology.
Driving Actual-World Impression
Since its MVP launch in January 2025, the adoption of DRIFT has been extraordinary. Inside the first 12 months, now we have seen vital adoption with over 600 builders having constructed greater than 1,500 pipelines throughout various enterprise models, together with Finance, Provide Chain, Engineering, Authorized, IT Operations, and Folks and Communities.
By lowering the time required to construct an information pipeline from months to minutes, DRIFT has turn out to be a essential engine for Cisco’s AI technique, enabling groups to experiment quickly and ship high-accuracy, AI-first options at scale.
Trying Forward
The success of DRIFT is a testomony to the collaborative spirit at Cisco. By working throughout groups—from IT & Operations to our numerous enterprise models—now we have created a instrument that not solely powers inner AI assistants (like our company-wide HR assistant) but in addition offers a basis for future product integrations.
As we proceed to iterate, DRIFT stays dedicated to serving to Cisco groups transfer sooner, experiment extra, and ship the subsequent era of AI-powered options to our staff, clients and companions.