

{kind=link}
On this article, you’ll learn the way immediate engineering adjustments basically when utilized to agentic AI programs, and what rules and patterns allow dependable agent conduct at scale.
Matters we’ll cowl embody:
- Why prompting brokers differs from prompting chatbots, and what context engineering means in observe.
- The 4 elements each agent immediate wants, together with system prompts, instruments, examples, and context state administration.
- The reasoning architectures that make brokers extra dependable, from chain of thought to ReAct and Reflexion.
Introduction
You’ve got most likely frolicked studying how one can immediate AI properly. Higher phrasing, clearer directions, extra context upfront. That information is genuinely helpful, and it’ll take you solely to date as soon as you progress into agentic AI.
The prompting abilities that work in a chat window break down the second the AI begins taking actions throughout a number of steps. A well-crafted query produces one good response. A well-designed agent immediate steers a system that reads recordsdata, calls APIs, makes selections, delegates to sub-agents, recovers from errors, and delivers a completed output, all with out you shepherding every step. These are two totally different disciplines. One is asking. The opposite is designing how a system thinks.
This text is in regards to the second factor. It’s written for builders and practitioners who’re shifting previous chat and into brokers, individuals who wish to know the way prompting really works inside autonomous programs, what the dependable patterns seem like, and the place most individuals go flawed.
Why Prompting an Agent is Completely different From Prompting a Chatbot
If you immediate a chatbot, your solely job is to supply a great subsequent response. You write one thing, the mannequin replies, you modify and go once more. The suggestions loop is brief and visual. If the output is flawed, you may see it instantly and re-prompt.
Brokers don’t work that manner. An agent receives a aim, builds a plan, executes it throughout many steps, makes use of instruments, generates intermediate outputs that feed into later steps, and finally delivers a closing end result. The issue is that an ambiguous instruction at the 1st step doesn’t visibly fail at the 1st step; it drifts. By step seven, the agent is technically doing what it inferred out of your immediate, which can be one thing you by no means meant. And by that time, you’ve already consumed important compute, time, and power calls getting there.
That is the core problem of agentic prompting: the results of your immediate are distributed throughout time and steps, not concentrated in a single response.
There may be additionally a structural situation that compounds this. Analysis on context degradation reveals that because the variety of tokens in an agent’s context window grows, the mannequin’s capacity to precisely recall and motive over that data decreases, a phenomenon researchers name context rot. Each software name end result, each intermediate output, each accomplished step provides tokens. By the center of an extended activity, an agent working on a poorly designed context might lose observe of constraints that had been clearly said initially.
That is precisely why Anthropic’s engineering staff launched the idea of context engineering because the pure evolution of immediate engineering. Their framing: immediate engineering asks “what are the correct phrases?” Context engineering asks “what’s the optimum set of data this mannequin ought to have at each level throughout execution?” That may be a larger, extra architectural query, and it’s the proper query for constructing brokers that behave reliably.
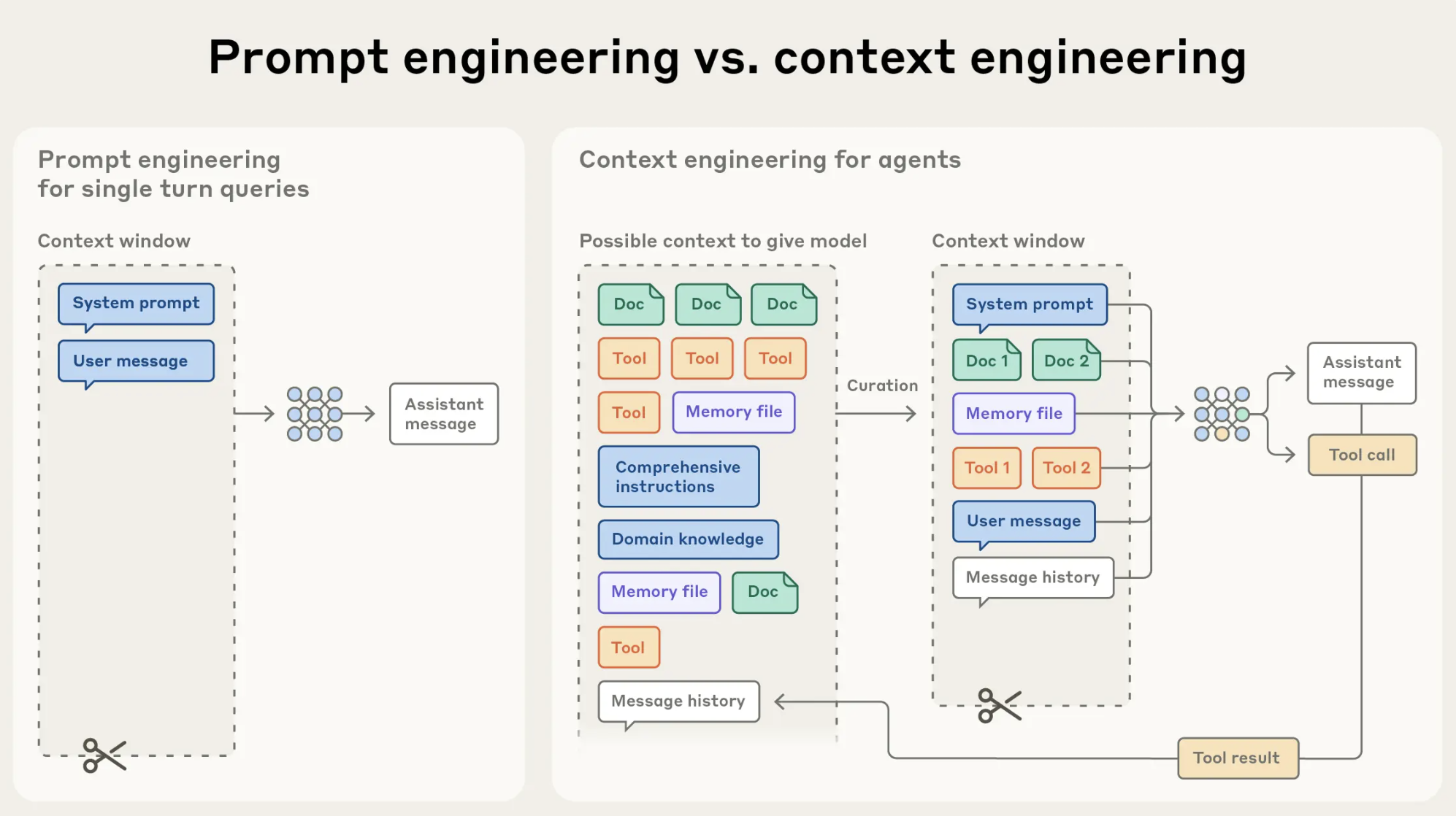
Anthropic’s context engineering (supply)
The 4 Parts Each Agent Immediate Wants
Primarily based on Lilian Weng’s foundational framework for LLM-powered brokers and Anthropic’s engineering steerage, a well-designed agent operates on 4 classes of context. Every one wants deliberate design. Leaving any of them to probability is the place most failures originate.
The System Immediate
The system immediate is the temporary your agent operates underneath for the complete activity. It defines the position the agent performs, the instruments accessible to it, the constraints it should respect, and the output it ought to ship. It’s the most consequential piece of textual content in your whole agent structure, and additionally it is the simplest one to write down badly.
Anthropic’s engineering staff describes two failure modes that bracket the flawed approaches. On one aspect: over-specification. Prompts full of brittle if-else logic that attempt to anticipate each attainable situation, hardcoding conduct that needs to be left to the mannequin’s judgment. These prompts are fragile — one edge case they didn’t anticipate, and the entire system misbehaves. On the opposite aspect: under-specification. Imprecise, high-level objectives that assume the mannequin shares context it doesn’t have. These prompts go away the agent to fill in blanks you didn’t know you had been leaving.
The suitable method is what Anthropic calls the proper altitude: particular sufficient to meaningfully constrain conduct, versatile sufficient to deal with conditions you didn’t explicitly script. Here’s what that appears like in observe.
Weak system immediate:
|
You are a useful analysis assistant. Assist the person with their analysis duties |
Robust system immediate:
|
You are a analysis assistant serving to a B2B SaaS product staff synthesize aggressive intelligence. You have entry to a internet search software and a file–writing software. Your work will be reviewed by a product supervisor earlier than any selections are made.
When given a analysis activity: 1. Make clear the scope if the aim is ambiguous earlier than beginning 2. Search for data from main sources first (firm web sites, official bulletins, earnings calls) earlier than secondary sources 3. Flag any data older than 12 months as doubtlessly outdated 4. Do not draw conclusions about competitor technique — report findings solely and let the human interpret them
Ship a structured report with: Govt Abstract (3–5 sentences), Findings by class, and a Sources part with URLs. Format as Markdown. |
The second model doesn’t over-specify each motion the agent would possibly take. It offers the agent a transparent position context, behavioral constraints, a supply precedence hierarchy, a scope on what it ought to and mustn’t conclude, and an output format. These are heuristics, not scripts, and that’s precisely what makes them sturdy.
Instruments
Each software you give an agent is a call level and a token value. Instrument descriptions eat consideration funds. Overlapping instruments create ambiguity. Based on Anthropic’s steerage, one of the crucial widespread failure modes in manufacturing brokers is bloated software units, the place the agent can’t reliably resolve which software to make use of in a given scenario.
The take a look at is easy: in case you, as a human trying on the agent’s scenario, can’t immediately resolve which software applies, the agent won’t reliably resolve both. Each software ought to have precisely one job, an outline that makes its goal unambiguous, and parameters which are descriptive sufficient to make use of with out exterior documentation.
Weak software description:
|
{ “title”: “search”, “description”: “Seek for data” } |
Robust software description:
|
{ “title”: “web_search”, “description”: “Search the general public internet for present data on a subject. Use this whenever you want info, information, or information which will have modified just lately or that’s not in your coaching information. Do NOT use this to retrieve paperwork already offered within the activity context.”, “parameters”: { “question”: “A particular, focused search question of 3-8 phrases”, “max_results”: “Variety of outcomes to return (default: 5, max: 10)” } } |
The stronger model tells the agent not simply what the software does, however when to make use of it and — critically — when to not. That boundary is what prevents the agent from defaulting to an internet seek for data that’s already in its context, losing tokens and time.
Examples (Few-Shot Prompting)
Analysis persistently reveals that examples outperform instruction lists for shaping agent conduct. When the mannequin sees two or three concrete input-output pairs, it prompts in-context studying, figuring out the sample and making use of the identical transformation logic to new inputs, usually extra reliably than pure language directions can obtain.
For brokers, examples serve a selected goal: they exhibit the anticipated reasoning format, output construction, and determination model — not simply the correct reply. A great few-shot instance for an agent reveals the pondering, not simply the end result.
Instance: Two-shot immediate for an information evaluation agent
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Instance 1: Enter: “Summarize the gross sales information in Q1_sales.csv” Thought: I want to learn the file first to perceive its construction earlier than summarizing something. Motion: read_file(“Q1_sales.csv”) Commentary: File comprises columns: Date, Area, Product, Income, Models. 547 rows protecting January–March 2025. Thought: Now I can summarize. I‘ll calculate totals by area and product, then determine the highest performer and any notable traits. Output: [Structured summary with totals, top performers, and one key trend]
Instance 2: Enter: “Evaluate our pricing to opponents” Thought: That is too obscure to behave on — I have to know which opponents and which merchandise earlier than I begin looking out. Output: “To check pricing precisely, I would like two issues: which opponents ought to I concentrate on, and which of your merchandise ought to I benchmark? Please make clear and I’ll proceed.“ |
Discover that instance two reveals the agent recognizing ambiguity and pausing to make clear — that could be a conduct you wish to exhibit explicitly, as a result of it’s not apparent from directions alone.
Message Historical past and Context State
The message historical past is each prior flip, software name end result, and intermediate output the agent has produced throughout the present activity. Additionally it is the primary supply of context rot in long-running brokers.
Anthropic’s analysis describes the transformer’s consideration mechanism as an consideration funds: each token within the context window competes for the mannequin’s focus, and that funds will get stretched as context grows. The mannequin stays succesful in longer contexts however reveals measurably decreased precision for data retrieval and long-range reasoning in comparison with shorter ones.
The sensible implication is that dumping the whole lot into the context window — each software end in full, each intermediate step — is a option to make your agent dumber because it will get additional right into a activity.
The higher method is just-in-time context: as a substitute of pre-loading all related information upfront, brokers keep light-weight references (file paths, saved question outcomes, URLs) and fetch what they want in the mean time they want it. That is how Claude Code handles massive codebases: it shops file paths and makes use of focused reads slightly than loading whole repositories into context. The mannequin sees solely the precise recordsdata related to the present step, maintaining the lively context lean and a focus targeted.
The Reasoning Architectures That Really Work
The way you construction an agent’s reasoning issues as a lot as what you place within the immediate. Analysis from Google’s staff printed in 2022 established the foundational proof: on Sport of 24 puzzles, a frontier mannequin went from 4% success to 74% success — not from a mannequin improve, however from giving it a structured option to motive via the issue. The mannequin didn’t get smarter; its reasoning structure did.
Chain of Thought (CoT)
Chain of thought prompting is the only architectural improve accessible and the inspiration on which the whole lot else builds. As an alternative of leaping from query to reply, the mannequin generates its reasoning steps explicitly earlier than committing to an output.
The unique analysis by Wei et al. confirmed that merely appending “Let’s assume step-by-step” to a immediate produced important accuracy beneficial properties on multi-step issues. That phrase prompts a reasoning mode. The mannequin externalizes its working, which each improves accuracy and makes the reasoning seen and auditable — precious for any high-stakes software.
Fundamental CoT immediate addition:
|
You are a monetary evaluation agent.
When given an evaluation activity, all the time assume via the following earlier than producing output: – What information do I have, and what information is lacking? – What assumptions am I making that might be flawed? – What is the most probably interpretation of this information? – What would change my conclusion?
Then produce your evaluation based mostly on that pondering. |
The secret is that CoT works greatest when the reasoning construction is matched to the duty kind. Monetary evaluation wants totally different reasoning steps than code debugging or aggressive analysis. Tailor the pondering framework to what your agent really does.
ReAct (Cause + Act)
ReAct is the dominant sample for brokers that use instruments. The title comes from the loop it implements: Thought → Motion → Commentary → Thought. The mannequin causes about what to do, takes an motion utilizing a software, observes the end result, after which causes once more based mostly on what it realized. This loop continues till the duty is full.
What makes ReAct highly effective is that it grounds the mannequin’s reasoning in precise proof. As an alternative of reasoning right into a vacuum and producing a assured however hallucinated reply, the mannequin is compelled to check its assumptions towards actual software outputs at every step.
ReAct immediate template:
|
You are a analysis agent with entry to web_search and save_file instruments.
Work via duties utilizing this loop:
Thought: [Reason about what you know and what you need to find out next] Motion: [Choose a tool and specify exactly what to do with it] Commentary: [This will be filled in with the tool result — do not write this yourself] Thought: [Reason about what the observation tells you and what to do next] ... repeat till full ... Remaining Reply: [Deliver the completed output]
By no means skip the Thought step. By no means take an Motion with out a Thought that justifies it. If an Commentary is surprising, motive about why earlier than deciding how to proceed. |
Instance of the ReAct loop in motion:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
Job: “Discover the present pricing for Notion’s Group plan and examine it to Coda’s Group plan.”
Thought: I want present pricing for each merchandise. I‘ll seek for every individually to get correct, up-to-date figures slightly than counting on my coaching information.
Motion: web_search(“Notion Group plan pricing 2025”) Commentary: Notion Group plan is $16/person/month billed yearly, $20/person/month billed month-to-month as of March 2025.
Thought: I’ve Notion’s pricing. Now I want Coda‘s.
Motion: web_search(“Coda Group plan pricing 2025”) Commentary: Coda Group plan is $30/person/month billed yearly.
Thought: I have each information factors. Notion is considerably cheaper at annual billing. I ought to observe when every value was verified.
Remaining Reply: [Structured comparison with pricing, billing options, and date of data retrieval] |
The loop forces the agent to decide to a selected motion, see an actual end result, and replace its reasoning slightly than producing a response based mostly purely on inner assumptions.
Reflexion (Self-Correction)
Reflexion takes ReAct one step additional. After finishing a activity or a significant step, the agent evaluates its personal output towards the unique aim, identifies particular failures or gaps, and generates a revised plan earlier than persevering with or delivering a closing end result. It’s the way you construct brokers that catch their very own errors with out requiring human intervention at each step.
Reflexion immediate addition:
|
After finishing every main activity step, earlier than shifting to the subsequent one, run a self–verify:
Reflection: – Does this output totally tackle what was requested? – Are there any claims I made that I can’t confirm from the information I retrieved? – Did I miss any constraints said in the unique activity? – If I had been the human reviewing this, what would I flag?
If you determine a hole or error, right it earlier than continuing. State what you discovered and what you modified. |
Reflexion in observe:
|
[Agent completes a first draft of a competitor analysis report]
Reflection: Reviewing towards the unique activity — the person requested for pricing, characteristic comparability, AND market positioning. I coated pricing and options, however I did not tackle how every competitor positions themselves in advertising supplies. That part is lacking.
Correcting: Operating an further search on every competitor‘s homepage and current press releases to seize positioning language earlier than delivering the closing report.
Motion: web_search(“Competitor A positioning messaging 2025”) ... |
Reflexion is most beneficial for duties the place high quality issues greater than velocity: studies, evaluation, and structured paperwork. The self-check loop provides latency however meaningfully reduces the speed of incomplete or inconsistent outputs reaching the top person.
Context Engineering in Follow
Understanding the idea is one factor. Translating it into agent prompts you really write is one other. These 4 patterns cowl probably the most impactful sensible strikes.
Hold the System Immediate on the Proper Altitude
Each failure modes value you. An over-specified immediate tries to script the agent’s each determination; it reads like a flowchart embedded in pure language, and it breaks the second actuality doesn’t match the script. An under-specified immediate fingers the agent a obscure aim and assumes it shares context it doesn’t.
The suitable altitude offers the agent a transparent position context, behavioral rules, and output expectations with out making an attempt to pre-answer each determination it would face. When you end up writing “if the person asks X, do Y; if the person asks Z, do W” in your system immediate, that could be a sign you’ve slipped into over-specification. Exchange the if-else with a precept: “Prioritize accuracy over velocity. When unsure, retrieve recent information slightly than counting on prior context.”
Write Final result Prompts, Not Process Lists
The identical precept applies right here as to agentic instruments extra broadly. Telling an agent what to ship produces higher outcomes than telling it every step to comply with. Process lists constrain the agent’s capacity to adapt when a step doesn’t go as anticipated, and in multi-step duties, steps hardly ever go precisely as anticipated.
Process checklist (fragile):
|
1. Open the CSV file 2. Discover the income column 3. Sum the values by area 4. Write a paragraph describing the outcomes 5. Save the output as report.docx |
Final result immediate (resilient):
|
Analyze the gross sales CSV in the working listing. Produce a Phrase doc with: whole income by area, the high–performing area with a temporary clarification of why it stands out, and any information high quality points you observed (lacking values, inconsistent formatting). Save as report.docx |
The end result model tells the agent what the completed product seems like. The agent figures out how one can get there and might adapt when the CSV has surprising columns or a area title is formatted inconsistently.
Use Simply-in-Time Context Over Pre-Loaded Context
Pre-loading the whole lot you assume the agent would possibly want into the context window is a pure intuition and a dependable option to degrade efficiency on lengthy duties. As an alternative, design your agent to take care of light-weight references and fetch particular data in the mean time it’s wanted.
In observe, this implies your system immediate ought to reference the place data lives, not comprise the data itself:
|
## Knowledge Entry
Buyer information is saved in /information/clients.csv. Product catalog is in /information/merchandise.json. Do not load these recordsdata upfront. Load solely the particular rows or fields related to the present step of the activity utilizing the read_file software with focused queries. |
This retains the lively context lean all through the duty, preserving consideration funds for the reasoning that issues at every step slightly than filling the window with information that can solely be related later.
Dynamic Persona Priming
A single agent structure can serve very totally different customers in case you inject context-specific persona data at runtime slightly than hardcoding it. That is helpful for brokers that serve each technical and non-technical audiences, or brokers that adapt tone and depth based mostly on the person’s position.
Runtime injection instance:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Injected based mostly on person position at session begin
# For a non-technical person: role_context = “”“ The person is a enterprise stakeholder with no technical background. Clarify findings in plain language. Keep away from jargon. Use analogies the place useful. By no means present uncooked information — all the time interpret it first. ““”
# For a technical person: role_context = “”“ The person is a senior information engineer. Use exact technical terminology. Embrace related SQL or code snippets the place they add readability. Give attention to implementation particulars over high-level summaries. ““”
system_prompt = base_system_prompt + “nn” + role_context |
One agent structure, two very totally different outputs — with out sustaining separate brokers or immediate recordsdata for every person kind.
Prompting Multi-Agent Programs
Single brokers have limits. Complicated duties that require parallel workstreams, specialised area information in a number of areas, or checks and balances between technology and assessment are higher served by multi-agent programs. The dominant sample is orchestrator-worker: one agent receives the aim, breaks it into subtasks, delegates every subtask to a specialised employee agent, and synthesizes the outcomes.
Prompting a multi-agent system means prompting every agent individually whereas designing the handoffs between them. Every agent must know precisely what it’s chargeable for, what it ought to obtain as enter, and what it ought to ship as output. It doesn’t want to know the total structure — solely its personal position inside it.
Orchestrator system immediate:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
You are a analysis orchestration agent. Your job is to coordinate a staff of specialised brokers to full analysis duties.
You have entry to three employee brokers: – search_agent: Retrieves data from the internet. Ship it: a particular search goal and the output format you want. – analysis_agent: Analyzes information and identifies patterns. Ship it: structured information and a particular analytical query. – writer_agent: Produces polished written outputs. Ship it: structured findings and the goal doc format.
Your duties: – Break the person‘s activity into clear subtasks for every agent – Specify precisely what every agent ought to ship earlier than you delegate – Validate that every agent’s output meets the spec earlier than passing it to the subsequent agent – Synthesize the closing output from all agent outcomes
Do not try to do any of the specialised work your self. |
Employee agent system immediate (search_agent):
|
You are a specialist search agent. You obtain a particular search goal from an orchestrator and return structured analysis findings.
Enter you will obtain: – A clear search goal – The output format required (e.g., bullet factors, JSON, desk)
Your duties: – Execute focused internet searches to fulfill the goal – Return solely data that straight addresses the goal – Flag any data that is older than 6 months – Do not interpret or editorialize — return findings solely
You do not want to perceive the bigger activity. Focus fully on the search goal you had been given. |
The crucial design precept right here is minimal shared context. Every employee agent is aware of solely what it must do its job. It doesn’t want the total activity context, the person’s historical past, or what the opposite brokers are doing. This retains every agent’s context lean, reduces the possibility of cross-contamination between duties, and makes the system simpler to debug when one thing goes flawed.
Frequent Errors and Repair Them
Even well-intentioned agent prompts fail for predictable causes. These are the 5 that come up most frequently.
- Giving the agent too many instruments: Extra instruments really feel like extra functionality, however they create ambiguity at each determination level. If two instruments might plausibly apply to the identical scenario, the agent will hesitate, select inconsistently, or use the flawed one. The repair: audit your software set earlier than each deployment. If you happen to can’t immediately and unambiguously determine which software applies to a given situation, prune till you may.
- Imprecise success standards: An agent that doesn’t know what “performed” seems like will maintain going, second-guess its outputs, or cease on the flawed level. Imprecise endings like “full the evaluation” invite interpretation. Particular ones like “ship a Phrase doc with these 4 sections, all populated with information from the offered CSV” don’t. Each activity specification ought to outline the output format, the anticipated content material, and any situations that have to be met earlier than the agent considers itself completed.
- Overloaded context: Entrance-loading the whole lot into the context window — all background paperwork, all prior session historical past, all reference information — degrades efficiency on lengthy duties as the eye funds will get stretched. Use just-in-time retrieval. Load particular information in the mean time it’s wanted, not abruptly at the beginning.
- No examples: Directions inform the agent what to do. Examples present what success seems like. For any activity sample you’ll run repeatedly, two or three well-chosen examples are price greater than an additional web page of directions. The mannequin can infer format, tone, determination model, and output construction from examples in ways in which pure language descriptions can’t totally seize.
- Treating a multi-step agent like a one-shot chat: A chatbot immediate will be obscure as a result of the human corrects in actual time. An agent operating autonomously throughout 15 steps has no such correction mechanism till it delivers a closing output. Each ambiguity you permit within the immediate turns into a call the agent makes by itself, and that call compounds throughout each step that follows. Make investments extra time in immediate design upfront. It pays again in fewer failed runs and extra dependable outputs.
Conclusion
Immediate engineering for agentic AI will not be a extra superior model of the identical talent. It’s a totally different self-discipline constructed on a special premise. Chat prompting is about getting a great response. Context engineering is about designing a dependable system — one which makes constant selections throughout many steps, makes use of instruments appropriately, manages its personal consideration funds, and delivers completed work with out requiring you to intervene at each flip.
The groups getting probably the most out of agentic AI proper now are those who stopped asking “how do I phrase this higher?” and began asking “what does this mannequin have to know at each step to behave the way in which I need?” That shift from phrasing to structure is the place the actual leverage lives. Begin with the system immediate on the proper altitude. Give the agent instruments that it will probably really distinguish between. Present it examples of the reasoning model you need. Then design the context to remain lean as the duty runs. These 4 habits will take you additional than any single intelligent immediate ever will.
For additional studying, Anthropic’s context engineering put up is probably the most sensible deep dive on the underlying rules. The Immediate Engineering Information’s brokers part covers ReAct, Reflexion, and associated architectures with further technical depth. Each are price maintaining open whilst you construct.