

{kind=link}
Amazon S3 Tables with Amazon Redshift provides you a robust mixture for analytical workloads on Apache Iceberg tables. However as question volumes develop, small inefficiencies compound. For instance, repeated queries, similar to dashboards refreshing hourly or analysts operating the identical joins all through the day, scan knowledge immediately from Amazon Easy Storage Service (Amazon S3) each time. The totally certified three-part desk references (database@catalog.schema.desk) add friction for enterprise intelligence (BI) instruments and finish customers who anticipate less complicated SQL syntax. And with out tuning the best way S3 Tables organizes your knowledge information, queries learn extra information than needed. While you deal with these three areas, your S3 Tables queries in Amazon Redshift turn out to be sooner, less complicated, and extra cost-efficient, whether or not you’re powering a recurring dashboard or supporting advert hoc evaluation at scale.
That is the third submit in our S3 Tables and Amazon Redshift collection. The first submit lined getting began with querying Apache Iceberg tables, and the second submit walked by means of enterprise-scale governance and entry controls. On this submit, you deal with these efficiency and value gaps with three approaches:
- Create exterior schemas to simplify queries from three-part notation right down to two-part notation.
- Construct materialized views that retailer pre-computed outcomes domestically so repeated queries skip the S3 scan.
- Configure S3 Tables compaction methods so the information file structure matches your question patterns.
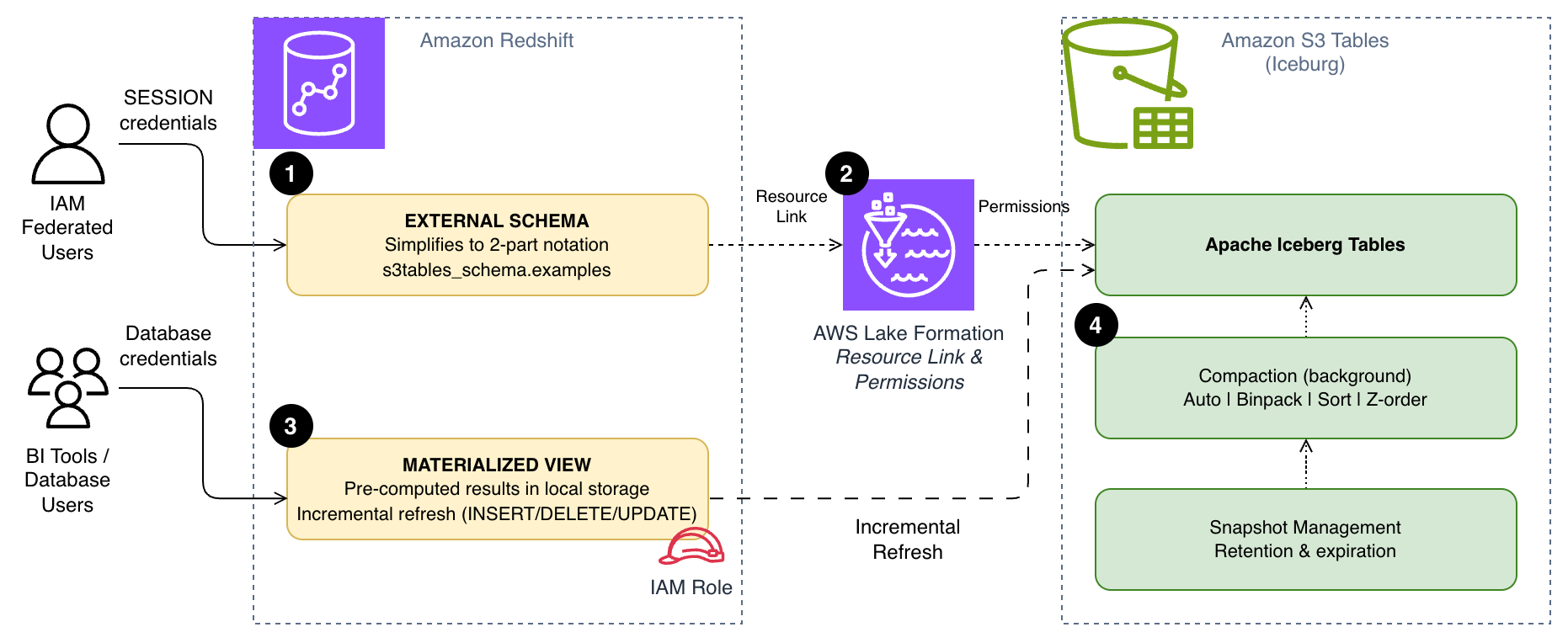
The next diagram exhibits how these three approaches work collectively. Exterior schemas [1] simplify question syntax by means of AWS Lake Formation useful resource hyperlinks [2], materialized views [3] retailer pre-computed outcomes domestically in Amazon Redshift, and S3 Tables compaction [4] optimizes the underlying file structure to your question patterns.
Conditions
Earlier than you start, ensure you have:
For those who haven’t accomplished these steps, comply with the setup directions within the first submit on this collection.
Simplify queries with exterior schemas
The earlier posts on this collection used the auto-mounted catalog to question S3 Tables with three-part notation:
You should use this syntax, however it may be cumbersome in enterprise intelligence (BI) instruments, manually typing queries, and in software code. This syntax additionally requires the consumer to make use of IAM federation. By creating an exterior schema, you may reference the identical tables with a concise two-part notation:
To set this up, you create a Lake Formation useful resource hyperlink that maps to your S3 Tables catalog, then create an exterior schema in Amazon Redshift that factors to that useful resource hyperlink. Your setup differs barely relying on whether or not your customers authenticate by means of IAM federation or database credentials. Whereas this doesn’t change question efficiency, it removes a standard barrier to adoption by simplifying the reference.
Create a Lake Formation useful resource hyperlink
Each authentication strategies require a useful resource hyperlink in Lake Formation that factors to your S3 Tables database.
- Within the Lake Formation console, select Databases underneath Knowledge Catalog.
- On the Create menu, select Useful resource hyperlink.
- Configure the useful resource hyperlink with the next settings:
- Useful resource hyperlink identify:
s3tables_rl - Vacation spot Catalog: Your account ID (for instance,
111122223333) - Shared Database: Your S3 Tables database (for instance,
icebergsons3) - Shared Database’s Catalog ID: Your S3 Desk bucket within the format
111122223333:s3tablescatalog/redshifticeberg
- Useful resource hyperlink identify:
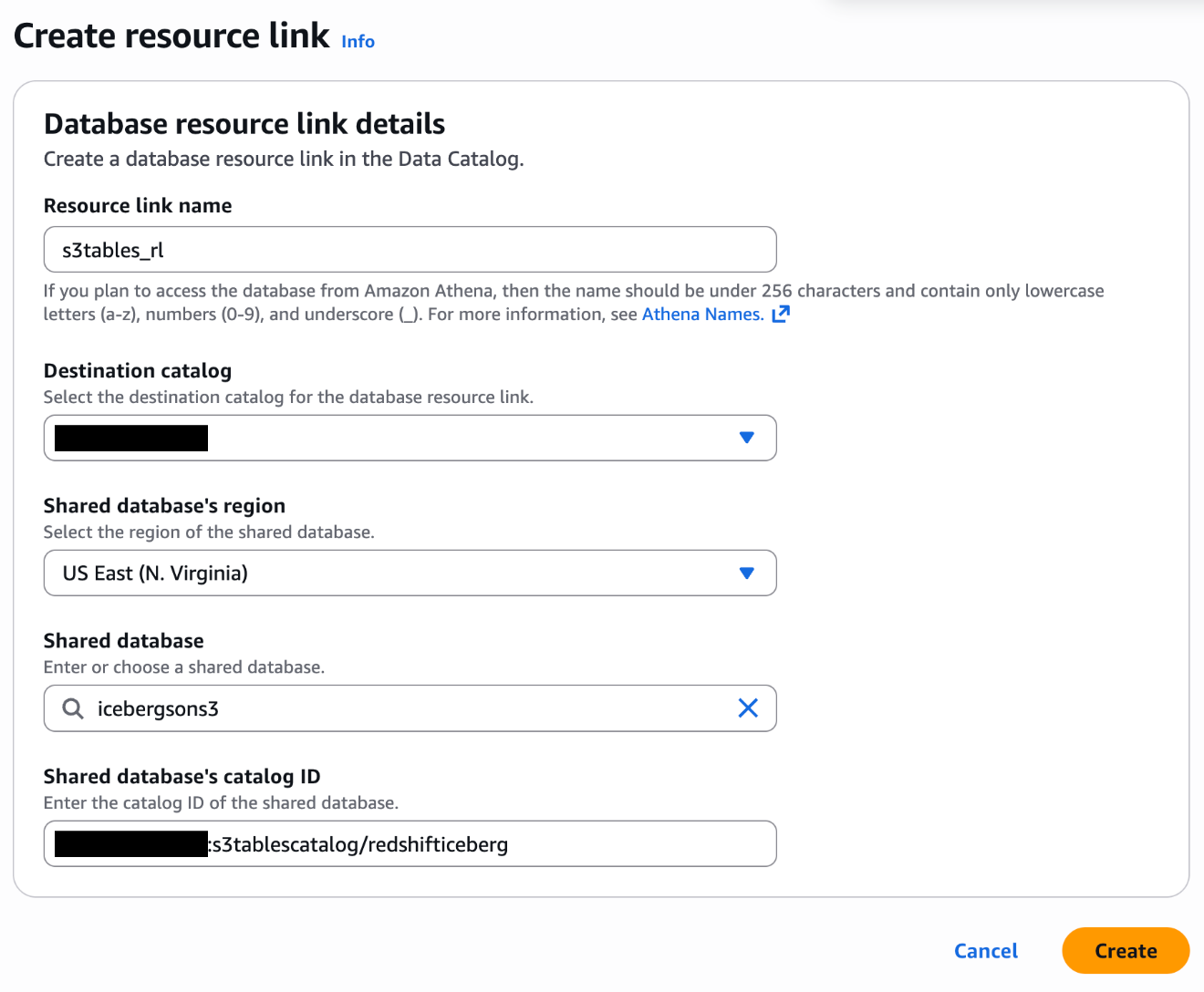
For extra info, see Creating useful resource hyperlinks within the Lake Formation documentation.
Choice A: Exterior schema for IAM federated customers
In case your customers hook up with Amazon Redshift by means of IAM federation, create the exterior schema with the SESSION key phrase. This passes the federated consumer’s credentials by means of to Lake Formation for entry management:
Lake Formation evaluates your permissions primarily based in your federated consumer’s IAM position, and sees solely the tables and columns their position permits. That is the advisable strategy for brand spanking new deployments as a result of it supplies fine-grained entry management with out extra position administration.
Choice B: Exterior schema for database customers
Exterior functions like Tableau, PowerBI, and customized ETL instruments usually authenticate with database credentials as a substitute of IAM federation. These customers want an IAM position to entry S3 Tables on their behalf.
Create an IAM service position to entry S3 Tables:
You create a job (for instance, S3TableAccessRole) with a belief coverage that permits Amazon Redshift to imagine it:
You then connect the next permission insurance policies to the position:
A coverage for Lake Formation knowledge entry (substitute your 12-digit AWS Account ID for YOUR_ACCOUNT_ID):
A coverage for AWS Glue Knowledge Catalog entry (substitute the suitable AWS Area for REGION_ID and your 12-digit AWS Account ID for YOUR_ACCOUNT_ID):
For manufacturing, scope these permissions to your particular sources and AWS Area.
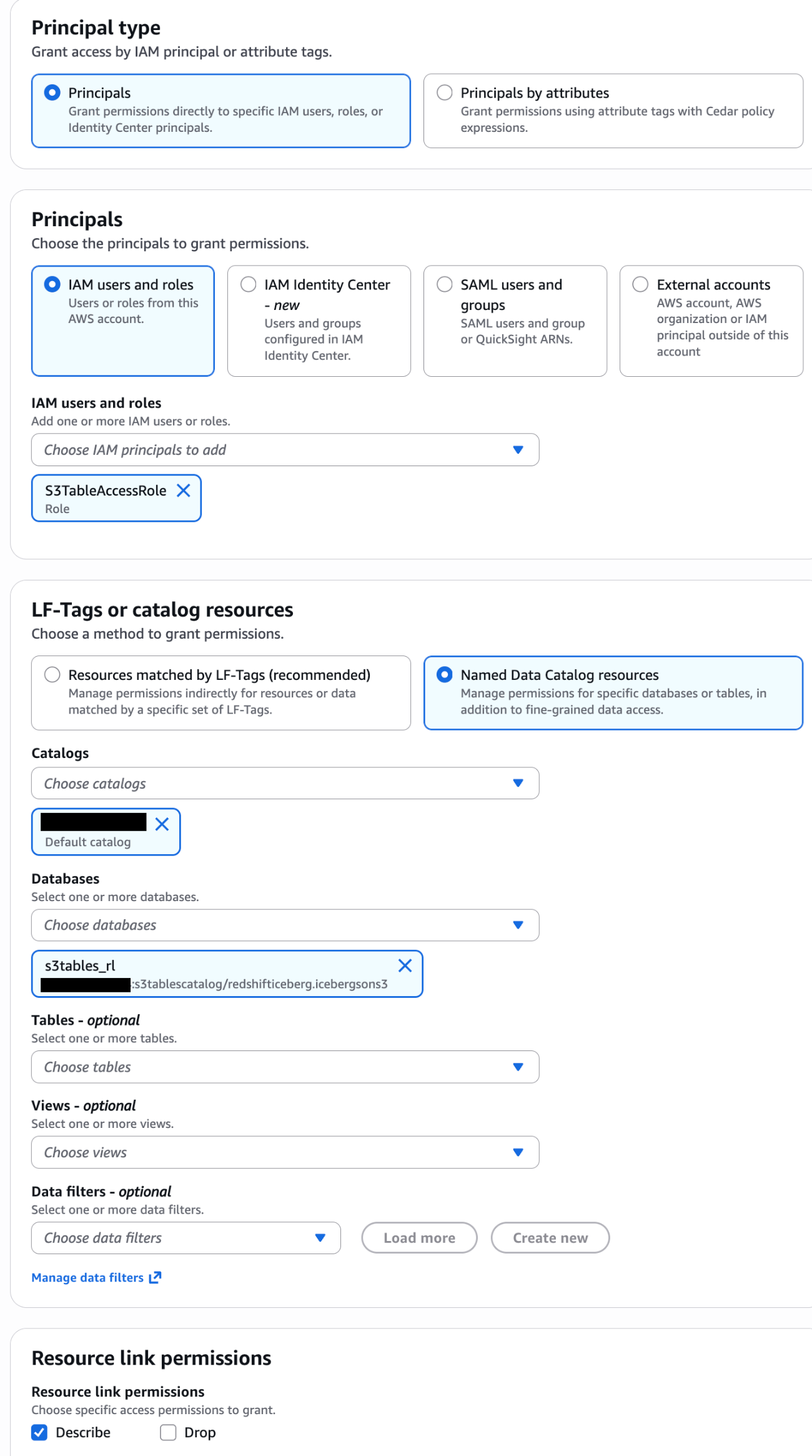
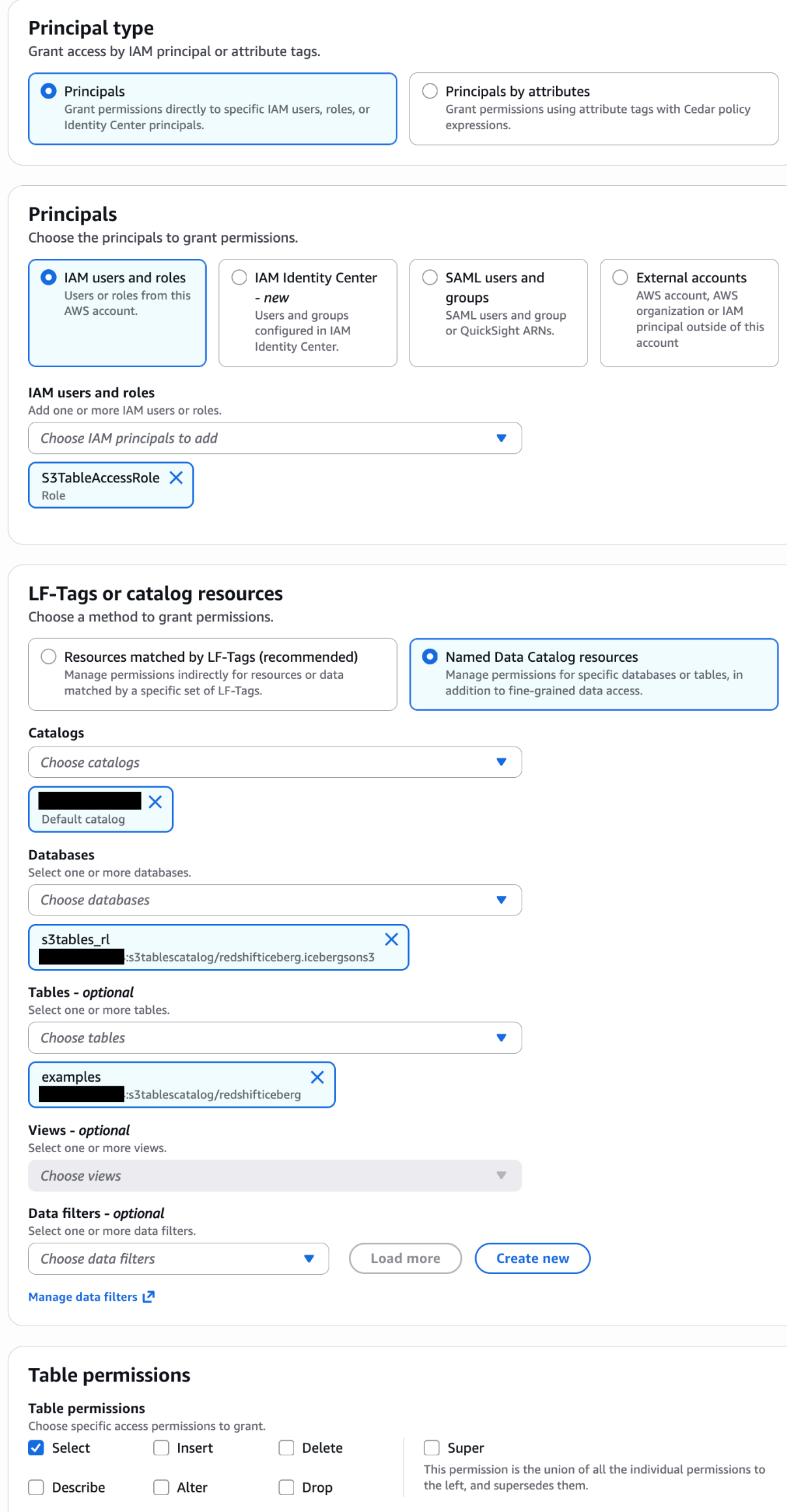
Grant Lake Formation permissions to the position:
Within the Lake Formation console, grant the S3TableAccessRole DESCRIBE entry on the database and SELECT entry on the tables to your useful resource hyperlink. For detailed steps, see Granting Lake Formation permissions.
Affiliate the position and create the schema:
First, affiliate the IAM position along with your Amazon Redshift cluster or workgroup. For directions, see Associating IAM roles with Amazon Redshift.
Create the exterior schema:
Then grant entry to your database customers:
Question with two-part notation
With both choice, now you can question S3 Tables utilizing the less complicated two-part notation:
You should use this notation in BI instruments, JDBC/ODBC connections, and software code and not must know the underlying catalog construction.
Speed up queries with materialized views
While you repeatedly question S3 Tables, every execution scans the exterior knowledge from S3. Materialized views retailer pre-computed ends in Amazon Redshift, so subsequent queries learn from native storage as a substitute of scanning S3 on each run.
Redshift helps incremental refresh for materialized views on Apache Iceberg tables, together with INSERT, DELETE, UPDATE, and desk compaction operations. After the preliminary creation, Amazon Redshift processes solely the rows that modified because the final refresh whenever you run subsequent refreshes, relatively than recomputing the complete consequence set. This helps cut back each the time and compute value of holding your views present, particularly for big tables with frequent modifications.
Materialized views have basic limitations and concerns when used with exterior knowledge lake tables. For particulars, see Materialized views on exterior knowledge lake tables.
Create a materialized view on S3 Tables
The next instance creates a materialized view that joins the examples desk in S3 Tables with a neighborhood classes desk in Amazon Redshift. You should use a materialized view to pre-compute day by day document counts and knowledge samples per class:
Question the materialized view immediately:
Your question can now learn from native Amazon Redshift storage and sometimes returns outcomes with out scanning S3 Tables:
Refresh methods
You’ve two choices for holding materialized views present:
Automated refresh: Set AUTO REFRESH YES within the view definition to have Amazon Redshift mechanically refresh the view within the background when it detects modifications to the bottom tables. This can be a good match for dashboards and experiences that may tolerate a brief delay between knowledge modifications and question outcomes. Observe that automated refresh requires Choice B (database consumer) when creating the exterior schema, and the default is AUTO REFRESH NO.
Guide refresh: Run REFRESH MATERIALIZED VIEW when you could management the timing:
Use handbook refresh when you could coordinate updates with knowledge loading pipelines or whenever you need to refresh throughout off-peak hours.
Tune S3 Tables compaction to your question patterns
S3 Tables mechanically compacts small Parquet information into bigger ones within the background. This compaction reduces the variety of learn requests your question engine should make, which may enhance question efficiency. By default, compaction targets a file dimension of 512 MB, configurable between 64 MB and 512 MB. 4 compaction methods can be found, and choosing the proper one to your question patterns could make a measurable distinction.
Compaction methods
| Technique | When to make use of | The way it works |
| Auto | You need S3 to determine for you | Selects type compaction for sorted tables, binpack for unsorted tables |
| Binpack | Basic-purpose workloads, unsorted tables | Combines small information into bigger information (100 MB+) and applies pending row-level deletes |
| Kind | Queries regularly filter on a single column (e.g., insert_date) |
Organizes knowledge by the desk’s sort-order columns throughout compaction |
| Z-order | Queries filter on two or extra columns collectively (e.g., insert_date and category_id) |
Blends a number of column values right into a single scalar for sorting |
Binpack improves efficiency by lowering the variety of information a question engine reads. Kind compaction goes additional. By ordering knowledge inside information, it permits question engines to skip whole information primarily based on column min/max metadata throughout predicate pushdown. That is efficient for queries that filter on the type column, similar to date-range filters. Z-order extends this profit to queries that filter on a number of columns concurrently, at the price of barely much less environment friendly pruning on any single column in comparison with a pure type.
To make use of type or z-order compaction, you first must confirm that the desk is sorted by one (type) or a number of (z-order) columns:
Configure a compaction technique
To alter the compaction technique for a desk, use the PutTableMaintenanceConfiguration API by means of the AWS Command Line Interface (AWS CLI):
To regulate the goal file dimension (for instance, to 256 MB):
Much like the “type” instance, you may specify {"technique":"z-order"} for z-order compaction.
For extra element on type and z-order, see Enhance Apache Iceberg question efficiency in Amazon S3 with type and z-order compaction.
Snapshot administration
S3 Tables handle snapshots mechanically. By default, it retains a minimal of 1 snapshot and expires snapshots older than 120 hours (5 days). The snapshot retention is personalized by setting minSnapshotsToKeep and maxSnapshotAgeHours. After a snapshot reaches the expiration time you configured in your retention settings, S3 Tables marks objects that solely that snapshot references as noncurrent and removes them primarily based on the unreferenced file removing coverage.
You possibly can modify these settings in case your workload wants extra snapshots for time-travel queries or longer retention:
Remember the fact that retaining extra snapshots will increase storage prices. If a materialized view references an expired snapshot, Amazon Redshift falls again to a full recompute on the following refresh. Due to this fact, snapshot retention can immediately have an effect on your materialized view refresh habits. Steadiness snapshot retention along with your materialized view refresh frequency to keep away from pointless full recomputes.
For extra info, see Upkeep for tables within the Amazon S3 documentation.
Finest practices
Select the suitable entry sample to your customers. Use IAM federation with SESSION credentials for brand spanking new functions and interactive customers. Reserve the IAM position strategy for BI instruments and extract, rework, and cargo (ETL) pipelines that may’t combine with IAM federation immediately. Plan emigrate database customers to federated entry over time.
Match compaction technique to question patterns. Use type compaction when your queries filter on a single column (similar to date ranges). Use z-order when queries filter on two or extra columns collectively. Keep on with the auto default in case your question patterns range otherwise you’re not sure.
Measurement materialized views to your refresh window. Materialized views that be part of massive exterior tables with native tables take longer to refresh. In case your knowledge modifications regularly, hold the materialized view targeted on the particular aggregations your dashboards want relatively than materializing whole tables.
Coordinate snapshot retention with materialized view refresh. If a materialized view references an expired Iceberg snapshot, Amazon Redshift performs a full recompute as a substitute of an incremental refresh. Set your snapshot retention (maxSnapshotAgeHours) longer than your materialized view refresh interval.
Monitor compaction with AWS CloudTrail. S3 Tables logs compaction operations as CloudTrail administration occasions. Observe these to confirm that compaction runs on schedule and to establish tables that may profit from a unique technique.
Steadiness efficiency good points in opposition to storage prices. Materialized views retailer pre-computed ends in Amazon Redshift, including to your managed storage. Compaction reduces file counts, however z-order and type compaction can improve total storage due to knowledge duplication throughout type boundaries. Assessment your Amazon Redshift managed storage utilization and S3 Tables storage metrics periodically to ensure the efficiency advantages justify the extra storage utilization.
Troubleshooting
| Difficulty | Decision |
| “Permission denied” when creating the exterior schema | Confirm the IAM position has lakeformation:GetDataAccess permission. Verify you related the position along with your Amazon Redshift cluster or workgroup. Additionally verify that you simply granted the position entry to the useful resource hyperlink database and its tables in Lake Formation. |
| “Schema not discovered” or “Database not discovered” errors | Verify the useful resource hyperlink identify in Lake Formation matches the DATABASE worth in your CREATE EXTERNAL SCHEMA assertion. Confirm the catalog ID format makes use of the sample account_id:s3tablescatalog/bucket_name. |
| “Desk not discovered” when querying by means of the exterior schema | Test that Lake Formation permissions embrace table-level entry, not simply database-level. Confirm the desk exists within the S3 Tables catalog by querying it by means of the auto-mounted catalog first. |
| Materialized view refresh falls again to full recompute | Test if the referenced Iceberg snapshot has expired. Enhance maxSnapshotAgeHours within the snapshot administration configuration. Confirm that the bottom desk hasn’t exceeded 4 million place deletes in a single knowledge file. Compaction resolves this. |
| Queries on S3 Tables are gradual after knowledge loading | Compaction runs on an automatic schedule and will not have processed latest writes but. Test CloudTrail for the most recent compaction occasion. Confirm the compaction technique matches your question patterns. Change from binpack to type for those who filter on particular columns. |
Cleansing up
To keep away from ongoing prices, take away the sources you created on this walkthrough:
Additionally take away:
- The IAM position (
S3TableAccessRole) and its connected insurance policies, for those who created one for database customers. - The Lake Formation useful resource hyperlink and related permissions.
- The S3 desk bucket, for those who not want the information.
Conclusion
On this submit, we confirmed find out how to optimize S3 Tables queries from Amazon Redshift utilizing three approaches: exterior schemas that simplify question syntax from three-part to two-part notation, making it simpler for BI instruments and finish customers to work with S3 Tables. We additionally lined materialized views for pre-computed analytical outcomes that cut back repeated S3 scans, and S3 Tables compaction methods tuned to your question patterns for extra environment friendly file entry.
For brand new functions, design your entry layer with IAM federation and exterior schemas from the beginning. Use materialized views to speed up repeated analytical queries that be part of S3 Tables with native Amazon Redshift knowledge. Match your compaction technique to how your crew queries the information. Use type compaction for date-range filters and z-order when queries filter on a number of columns directly. Moreover, the identical S3 tables you optimize listed here are additionally accessible from Amazon Athena, Amazon EMR, and third-party engines.
To be taught extra, see the Amazon S3 Tables documentation, Materialized views in Amazon Redshift, and S3 Tables upkeep. We welcome your suggestions within the feedback.
Concerning the authors