

{kind=link}
Optimizing the Airflow employee pool configuration in Amazon Managed Workflows for Apache Airflow (Amazon MWAA), the AWS totally managed Apache Airflow service, is a crucial but typically neglected technique for scaling workflow operations. Duties queued for longer intervals can create the phantasm that extra employees are the answer, when in actuality the basis trigger would possibly lie elsewhere. The choice to scale isn’t all the time easy. DevOps engineers and system directors steadily face the problem of figuring out whether or not including extra employees will resolve their efficiency points or solely enhance operational value with out addressing the basis trigger.
This put up explores totally different patterns for employee scaling selections in Amazon MWAA, specializing in the duty pool mechanism and its relationship to employee allocation. By inspecting particular situations and offering a sensible choice framework, this put up helps you identify whether or not including employees is the correct answer on your efficiency challenges, and in that case, methods to implement this scaling successfully.
This part discusses essentially the most steadily seen issues that elevate the query if including extra employees would enhance the well being of your setting.
Excessive CPU
Airflow serves as a workflow administration platform that coordinates and schedules duties to be run on exterior processing companies. It acts as a central orchestrator that may set off and monitor duties throughout numerous information processing techniques like AWS Glue, AWS Batch, Amazon EMR, and different specialised information processing instruments. Fairly than processing information itself, Airflow’s energy lies in managing complicated workflows and coordinating jobs between totally different techniques and companies.
In Analytics and Huge Information environments, there’s a prevalent false impression that saturated sources robotically warrant including extra capability. Nonetheless, for Amazon MWAA, understanding your workflow traits and optimization alternatives ought to precede scaling selections.
As you scale up your workflows, useful resource utilization of the Airflow clusters naturally will increase. When employees constantly function at full capability, it might appear intuitive so as to add extra compute sources. Nonetheless, this method typically masks underlying inefficiencies relatively than resolving them.
For instance, in Amazon MWAA if you’re operating a single activity that’s consuming 100% of the out there CPU in your Amazon MWAA employee, including extra employees won’t resolve the issue as the duty just isn’t optimized nor break up into smaller components. As such, growing the variety of minimal employees won’t carry the anticipated impact however will solely enhance the working prices.
When your Amazon MWAA employees are constantly operating above 90% CPU or Reminiscence utilization, you’ve reached a essential choice level. Earlier than taking actions, it’s important to know the basis trigger. You’ve three main choices:
- Scale horizontally by including extra employees to distribute the load.
- Scale vertically by upgrading to a bigger setting class for extra sources per employee.
- Optimize your DAGs and scheduling patterns to be extra environment friendly and devour fewer sources.
Every method addresses totally different underlying points, and selecting the best path is determined by figuring out whether or not you might be dealing with a capability constraint, resource-intensive activity design, or workflow inefficiency. For steering on optimization methods, please confer with Efficiency tuning for Apache Airflow on Amazon MWAA.
To watch the CPUUtilization and MemoryUtilization on the employees, confer with the Accessing metrics within the Amazon CloudWatch console and select the corresponding metrics.
- Choose a time window lengthy sufficient to indicate utilization patterns.
- Set interval to 1 Minute.
- Set statistics to Most.
Lengthy queue time
Generally Airflow duties are caught in a queued state for a very long time, which prevents DAGs from finishing on time.
In Amazon MWAA, every setting class comes with configured minimal and most employee nodes. Every employee offers a pre-configured concurrency, which is the variety of duties that may run concurrently on every employee at any given time. The conduct is managed via celery.worker_autoscale=(max,min).
For instance, when you have minimal 4 mw1.small employees, with default Airflow configuration, it is possible for you to to run 20 concurrent duties (4 employees x 5 max_tasks_per_worker). In case your system abruptly requires greater than 20 duties to execute concurrently, it will lead to an autoscaling occasion. Amazon MWAA will resolve methods to scale your employees effectively, and set off the method. The autoscaling course of, nonetheless, requires extra time to provision new employees leading to extra duties in queued standing. To mitigate this queuing problem, take into account the next:
- If the CPU utilization on the employees is low, growing the
maxworth incelery.worker_autoscale=(max,min)can scale back the time duties keep in queued state as every employee will be capable to course of extra duties concurrently. Airflow employee can take duties as much as the outlined activity concurrency whatever the availability of its personal system sources. Because of this, the bottom employee might attain 100% CPU/Reminiscence utilization earlier than Autoscaling takes impact. - If you do not need to extend the duty concurrency on the employees, growing the minimal employee rely may also be helpful as a result of having extra out there employees permits a better variety of duties to run concurrently.
Scheduling delays
Including new DAGs cannot solely have an effect on your system sources, however it may additionally create uneven scheduling patterns. Some DAGs might expertise delayed execution due to useful resource competitors, even when the general setting metrics seem wholesome. This scheduling skew typically manifests as inconsistent activity pickup occasions, the place sure workflows constantly wait longer within the queue whereas others execute promptly.
When Amazon CloudWatch metrics present growing variance in activity scheduling occasions, notably during times of excessive DAG exercise, it alerts the necessity for setting optimization. This state of affairs requires cautious evaluation of execution patterns and useful resource utilization to find out if:
- Whereas including employees can assist distribute the workload, this answer is best when the excessive utilization is primarily due to activity execution load relatively than DAG parsing or scheduling overhead. Including extra minimal employees will mean you can execute extra duties in parallel. For instance, in the event you observe the worth of
AWS/MWAA/ApproximateAgeOfOldestTaskto be steadily growing, it implies that the employees will not be in a position to devour the messages from the queue quick sufficient. Moreover, you too can monitor theAWS/MWAA/QueuedTasksto determine comparable patterns. - Upgrading the setting class would supply higher scheduling capability. If the Scheduler is exhibiting indicators of pressure or in the event you’re seeing excessive useful resource utilization throughout all elements, upgrading to a bigger setting class is perhaps essentially the most acceptable answer. This offers extra sources to each the Scheduler and Employees, permitting for higher dealing with of elevated DAG complexity and quantity. To validate the identical, use
AWS/MWAA/CPUUtilizationandAWS/MWAA/MemoryUtilizationwithin the Cluster metrics and selectScheduler,BaseWorkerandAdditionalWorkermetrics. - Restructuring DAG schedules would cut back useful resource competition.
The secret is to know your workflow patterns and determine whether or not the scheduling delays are due to inadequate employee capability or different environmental constraints.
This part showcases the commonest anti patterns which make MWAA customers suppose that including extra employees will enhance efficiency.
Underutilized employees
When evaluating Amazon MWAA efficiency bottlenecks, it’s essential to tell apart useful resource constraints and DAG design inefficiencies earlier than scaling the setting.
Generally the Amazon MWAA setting has the capability to run 100 duties concurrently however your queue metrics (AWS/MWAA/RunningTasks) present solely 20 duties lively more often than not with no duties remaining in queued state. In such situations, you might be suggested to examine Amazon CloudWatch for constantly low CPU and reminiscence utilization on current employees throughout peak workload occasions. If that is confirmed, it’s often a sign of inefficiencies in DAG design, scheduling patterns, or Airflow configuration.
You’ve two main choices to handle this:
1. Downsize: If you don’t anticipate your workload to extend, it’s secure to imagine you’ve got over-provisioned your cluster. Begin by eradicating any further employees first and at last resolve to downsizing your setting class.
2. Optimize: High-quality tune your DAG scheduling and airflow configuration via Swimming pools and Airflow configuration for concurrency to extend the throughput of your system.
Misconfigured Airflow configurations that create synthetic bottlenecks
In Apache Airflow, efficiency bottlenecks typically happen due to configuration settings, not precise useful resource constraints. At such occasions, DAG executions get delayed not due to inadequate compute, however due to incorrect concurrency configuration.
Environment friendly use of Amazon MWAA requires reviewing not solely useful resource utilization for Employees and Schedulers but additionally concurrency configurations for artificially created bottlenecks. Generally one restrictive configuration prevents the scaling advantages of bigger setting or extra employees. All the time audit Airflow configurations if efficiency appears restricted even when system metrics counsel spare capability.
Necessary consideration: Amazon Managed Workflows for Apache Airflow (Amazon MWAA) doesn’t robotically replace the employee concurrency configuration whenever you change the setting class. This conduct is essential to know when scaling your setting. Should you initially create an mw1.small setting, the place every employee can deal with as much as 5 concurrent duties by default. Whenever you improve to a medium setting class (which helps 10 concurrent duties per employee by default), the concurrency setting stays at 5 for in-place up to date environments. You need to manually replace the concurrency configuration to take full benefit of the elevated capability out there within the medium setting class.
Due to this it’s essential additionally replace the Airflow configurations that management concurrency everytime you replace the setting class. To replace the concurrency setting after upgrading your setting class, modify the celery.worker_autoscale configuration in your Apache Airflow configuration choices. This makes positive your employees can course of the utmost variety of concurrent duties supported by your new setting class.
Different occasions, an Amazon MWAA setting may be constrained by max_active_runs or DAG concurrency controls as an alternative of precise useful resource limits. These configuration-based throttles stop duties from operating, even when the employee situations have out there compute to deal with the workload.
There is a crucial distinction between the 2. Configuration limits act as synthetic caps on parallelism, whereas true useful resource limits point out that employees are totally using their CPU or reminiscence capability. Understanding which kind of constraint impacts your setting helps you identify whether or not to regulate configuration settings or scale your infrastructure.
Adjusting Airflow configurations corresponding to Swimming pools, concurrency, max_active_runs solves efficiency issues with out scaling employees. A number of the configurations you need to use to manage this conduct:
- max_active_runs_per_dag (DAG degree): Controls what number of DAG runs for a given DAG are allowed on the similar time. If set to 2, solely 2 DAG runs can run concurrently, even when there’s loads of employee capability left. Further runs queue, making the DAG executions gradual regardless that employees are idle.
- max_active_tasks:Controls the concurrency discipline in a DAG definition (or setting at setting degree) limits the variety of duties from the DAG operating at any second, no matter total system capability or variety of employees.
- Swimming pools:Swimming pools prohibit what number of duties of a sure sort (typically useful resource heavy) can run without delay. A pool with solely 3 slots will throttle any duties above 3 assigned to that pool, leaving employees idle.
- Execution timeouts and retries: If not tuned, failed duties would possibly replenish slots unnecessarily, caught duties can block employee slots and gradual queue processing.
- Scheduling intervals and dependencies: Overlapping or inefficient scheduling might trigger idle intervals or extra competition for sources, affecting actual throughput.
How Airflow configurations can override one another
Airflow has a number of layers of concurrency and scheduling controls. Some on the setting degree, some on the DAG/activity degree, and others for swimming pools. Generally extra restrictive settings override extra permissive ones, leading to surprising queue buildup.
DAG degree vs Atmosphere degree: If “max_active_runs_per_dag” (DAG degree) is decrease than the environment-level “max_active_runs_per_dag” or system large concurrency, the DAG setting is used, throttling duties even when the setting may do extra.
Process degree overrides: Particular person activity definitions can have their very own parameters like “max_active_tis_per_dag” which may cap runs per activity and create a bottleneck if set decrease than international settings.
Order of priority: Essentially the most restrictive related configuration at any degree (Atmosphere, DAG, Process) successfully units the higher sure for parallel activity execution.
| Setting Location | Setting | Impact on activity throughput |
| Atmosphere Degree | parallelism | Max complete duties operating on Scheduler |
| DAG Degree | max_active_runs | Max simultaneous DAG runs |
| Process Degree | concurrency | Max concurrent activity for that DAG |
Efficiency points typically resemble useful resource exhaustion, however really derive from overly restrictive configurations. Audit all of the previous parameters rigorously. You may loosen restrictive values step-by-step and monitor their impact earlier than deciding to scale your cluster additional. This method ensures optimum and cost-efficient utilization of your cloud sources with out paying for idle capability.
Gradual useful resource depletion from reminiscence leaks
A typical state of affairs for reminiscence leak or gradual useful resource depletion in Amazon MWAA is when DAGs and duties start to fail or decelerate over time. Scaling employees or growing setting measurement doesn’t resolve the underlying problem. This occurs as a result of the basis trigger just isn’t a scarcity of capability however relatively an application-level leak that causes persistent exhaustion.
For instance, as Airflow constantly runs duties and parses DAGs over time, reminiscence consumption can steadily enhance throughout the setting. This would possibly manifest as an Amazon MWAA metadata database experiencing declining FreeableMemory metrics regardless of constant and even diminished workloads. When this happens, database question efficiency regularly declines as reminiscence sources change into constrained for scheduler/employee & metadata database, in the end affecting total setting responsiveness since Airflow relies upon closely on its metadata database for essential operations. This state of affairs is much like how an software would possibly create database connections with out correctly closing them, resulting in useful resource exhaustion over time.
Graph: Declining FreeableMemory and MemoryUtilization
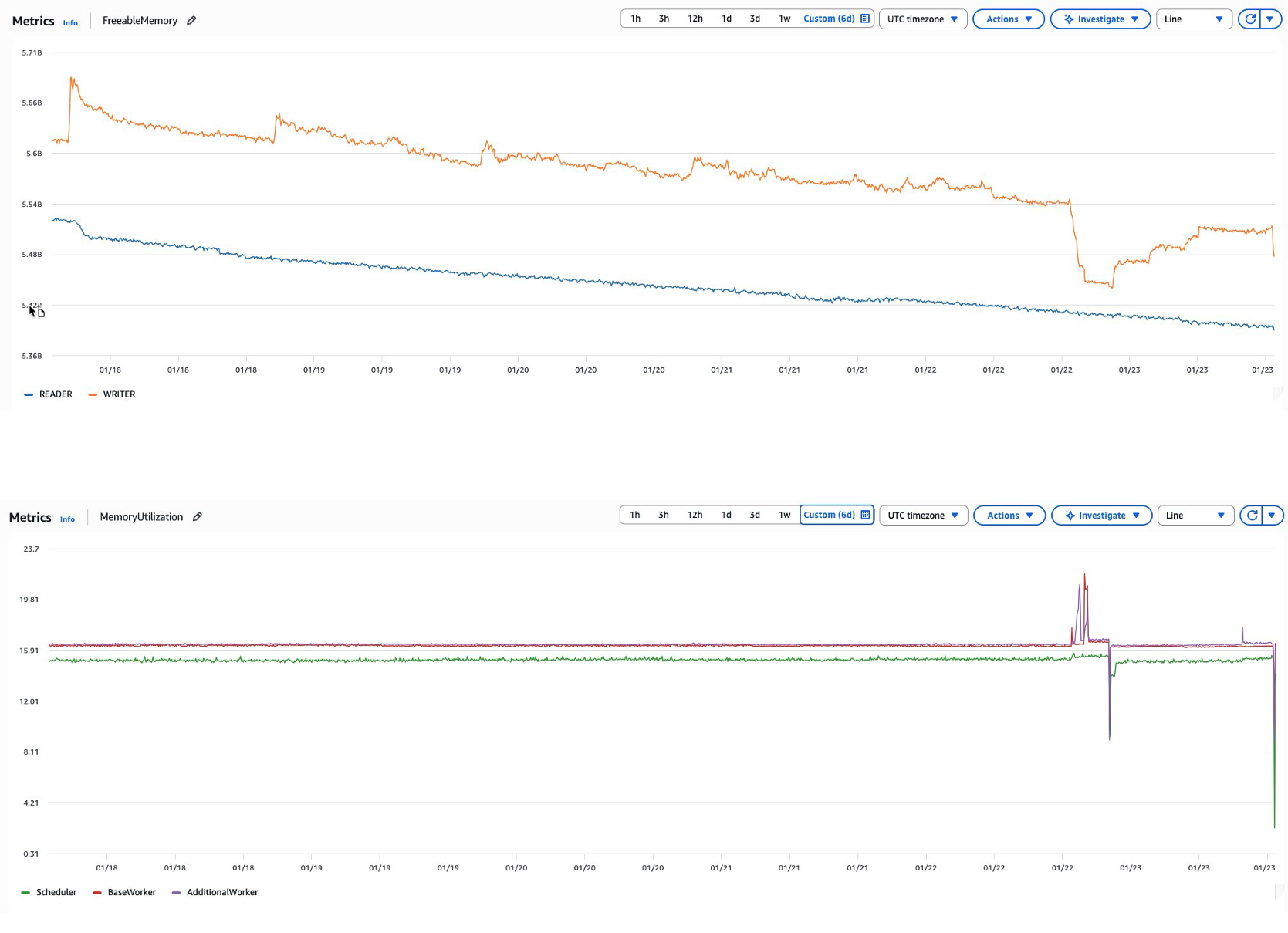
Frequent causes:
- Connection pool exhaustion: DAGs that fail to correctly shut database connections can result in connection pool exhaustion and reminiscence leaks within the database.
- Useful resource-intensive operations: Complicated, long-running queries or XCOM operations towards the metadata database can devour extreme reminiscence.
- Inefficient DAG design: DAGs with quite a few top-level Python calls can set off database queries throughout DAG parsing. As an example, utilizing variable.get() calls on the DAG degree relatively than on the activity degree creates pointless database load.
Advisable options:
- Implement Amazon CloudWatch monitoring: Set up Amazon CloudWatch alarms for FreeableMemory with acceptable thresholds to detect points early.
- Common database upkeep: Carry out scheduled database clean-up operations to purge historic information that’s now not wanted.
- Optimize DAG code: Refactor DAGs to maneuver database operations like variable.get() from the DAG degree to the duty degree to scale back parsing overhead.
- Connection administration: Make certain all database connections are correctly closed after use to forestall connection pool exhaustion.
By following the previous suggestions you may preserve wholesome reminiscence utilization for the metadata database and preserve optimum efficiency of your Amazon MWAA setting with no need to scale employees.
The choice so as to add employees in Amazon MWAA environments requires cautious consideration of a number of components past easy activity queue metrics. On this put up, we confirmed that whereas including employees can tackle sure efficiency challenges, it’s typically not the optimum first response to system bottlenecks.
Key concerns earlier than scaling employees embrace:
- Root trigger evaluation
- Confirm whether or not excessive CPU/reminiscence utilization stems from activity optimization points.
- Study if queuing issues consequence from configuration constraints relatively than useful resource limitations.
- Examine potential reminiscence leaks or useful resource depletion patterns.
- Configuration optimization
- Evaluate and alter Airflow parameters (concurrency settings, swimming pools, timeouts).
- Perceive the interplay between totally different configuration layers.
- Optimize DAG design and scheduling patterns.
Essentially the most profitable Amazon MWAA implementations comply with a scientific method: first optimizing current sources and configurations, then scaling employees solely when justified by data-driven capability planning. This method ensures cost-effective operations whereas sustaining dependable workflow efficiency.
Keep in mind that employee scaling is just one instrument within the Amazon MWAA optimization toolkit. Lengthy-term success is determined by constructing a complete efficiency administration technique that mixes correct monitoring, proactive capability planning, and steady optimization of your Airflow workflows.
Within the subsequent put up, we talk about capability planning and the steps it’s essential carry out earlier than including extra DAGs in your setting in an effort to plan for the extra load and be sure to have sufficient headroom.
To get began, go to the Amazon MWAA product web page and the Efficiency tuning for Apache Airflow on Amazon MWAA web page.
You probably have questions or wish to share your MWAA scaling experiences, depart a remark beneath.
Concerning the authors