

{kind=link}
Whereas working with Lambda Consumer-Outlined Features (UDFs) in Amazon Redshift, figuring out greatest practices might assist you streamline the respective function improvement and cut back frequent efficiency bottlenecks and pointless prices.
You surprise what programming language may enhance your UDF efficiency, how else can you employ batch processing advantages, what concurrency administration issues could be relevant in your case? On this publish, we reply these and different questions by offering a consolidated view of practices to enhance your Lambda UDF effectivity. We clarify how to decide on a programming language, use present libraries successfully, reduce payload sizes, handle return knowledge, and batch processing. We talk about scalability and concurrency issues at each the account and per-function ranges. Lastly, we study the advantages and nuances of utilizing exterior providers together with your Lambda UDFs.
Background
Amazon Redshift is a quick, petabyte-scale cloud knowledge warehouse service that makes it easy and cost-effective to investigate knowledge utilizing commonplace SQL and present enterprise intelligence instruments.
AWS Lambda is a compute service that permits you to run code with out provisioning or managing servers, supporting all kinds of programming languages, mechanically scaling your purposes.
Amazon Redshift Lambda UDFs lets you run Lambda capabilities immediately from SQL, which unlock such capabilities like exterior API integration, unified code deployment, higher compute scalability, value separation.
Stipulations
- AWS account setup necessities
- Fundamental Lambda perform creation data
- Amazon Redshift cluster entry and UDF permissions.
Efficiency optimization greatest practices
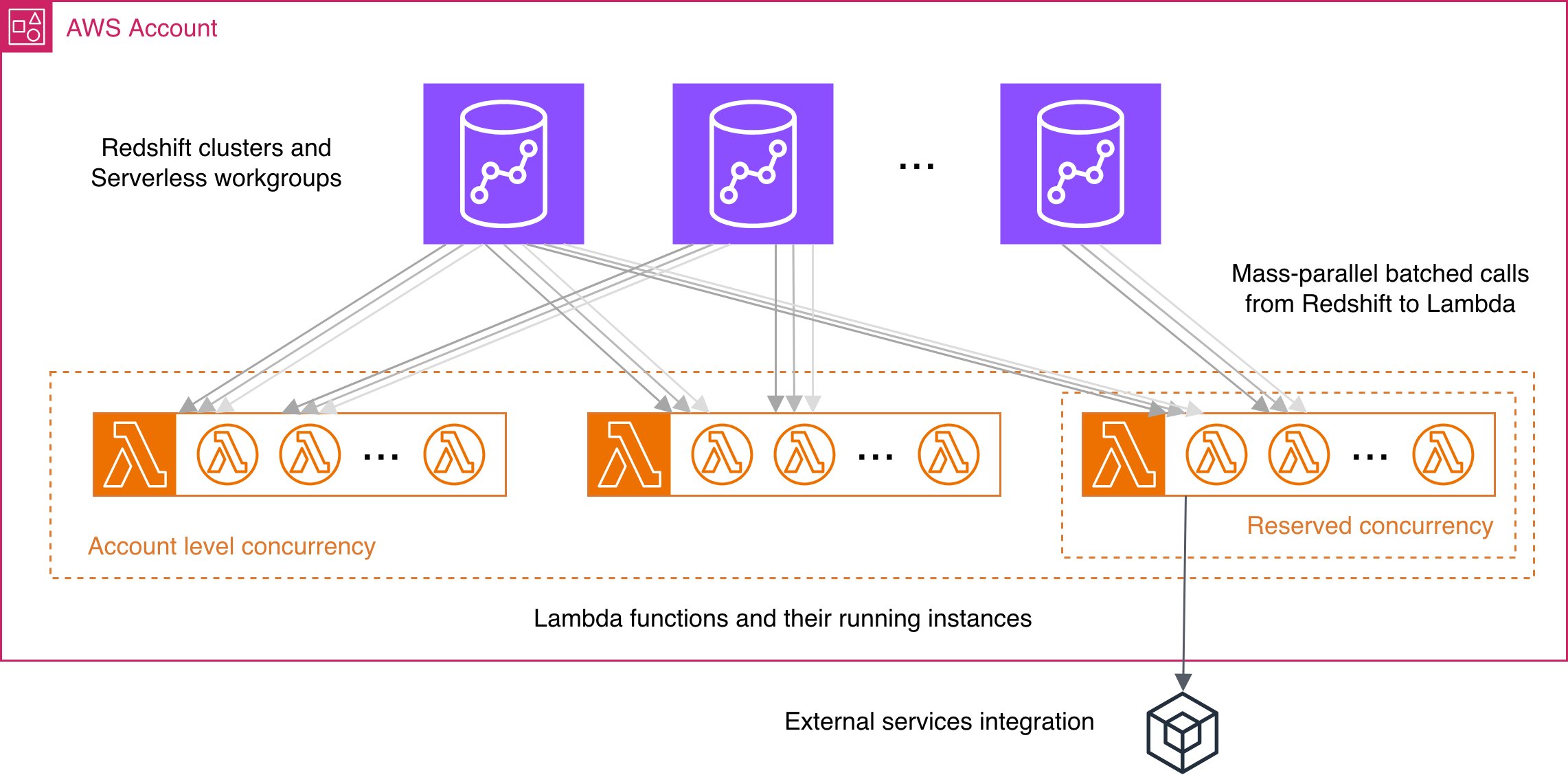
The next diagram incorporates essential visible references from the very best practices description.
Use environment friendly programming languages
You’ll be able to select from Lambda’s vast number of runtime environments and programming languages. This alternative impacts each the efficiency and billing. Extra performant code might assist cut back the price of Lambda compute and enhance SQL question pace. Quicker SQL queries may additionally assist cut back prices for Redshift Serverless and probably enhance throughput for Provisioned clusters relying in your particular workload and configuration.
When selecting a programming language in your Lambda UDFs, benchmarks might assist predict efficiency and price implications. The well-known Debian’s Benchmarks Sport Crew offers publicly out there insights for various languages of their micro-benchmark outcomes. For instance, their Python vs Golang comparability exhibits as much as 2 orders of magnitude run time enchancment and twice reminiscence consumption discount in case you may use Golang as an alternative of Python. Which will positively mirror on each Lambda UDF efficiency and Lambda prices for the respective eventualities.
Use present libraries effectively
For each language offered by Lambda, you may discover the entire assortment of libraries that will help you implement duties higher from the pace and useful resource consumption standpoint. When transitioning to Lambda UDFs, assessment this facet rigorously.
As an example, in case your Python perform manipulates datasets, it could be value contemplating utilizing the Pandas library.
Keep away from pointless knowledge in payloads
Lambda limits request and response payload measurement to 6 MB for synchronous invocations. Contemplating that, Redshift is doing greatest effort to batch the values in order that the variety of batches (and therefore the Lambda calls) could be minimal which reduces the communication overhead. So, the pointless knowledge, like one added for future use however not instantly actionable, might cut back effectivity of this effort.
Take into account returning knowledge measurement
As a result of, from the standpoint of Redshift, every Lambda perform is a closed system, it’s unattainable to know what measurement the returned knowledge can presumably be earlier than executing the perform. On this case, if the returned payload is larger than the Lambda payload restrict, Redshift must retry with the outbound batch of a decrease measurement. That may proceed till a match return payload will likely be achieved. Whereas it’s the greatest effort, the method may convey a notable overhead.
So as to keep away from this overhead, you may use the data of your Lambda code, to immediately set the utmost batch measurement on the Redshift aspect utilizing the MAX_BATCH_SIZE clause in your Lambda UDF definition.
Use advantages of processing values in batches
Batched calls present new optimization alternatives to your UDFs. Having a batch of many values handed to the perform without delay, permits to make use of numerous optimization methods.
For instance, memoization (end result caching), when your perform can keep away from operating the identical logic on the identical values, therefore decreasing the entire execution time. The usual Python library functools offers handy caching and Least Just lately Used (LRU) caching decorators implementing precisely that.
Scalability and concurrency administration
Improve the account-level concurrency
Redshift makes use of superior congestion management to supply the very best efficiency in a extremely aggressive surroundings. Lambda offers a default concurrency restrict of 1,000 concurrent execution per AWS Area for an account. Nonetheless, if the latter shouldn’t be sufficient, you may all the time request the account stage quota improve for Lambda concurrency, which could be as excessive as tens of hundreds.
Notice that even with a restricted concurrency house, our Lambda UDF implementation will do the very best effort to reduce the congestion and equalize the probabilities for perform calls throughout Redshift clusters in your account.
Prohibit perform concurrency with reserved concurrency
If you wish to isolate a number of the Lambda capabilities in a restricted concurrency scope, for instance you might have an information science group experimenting with embedding era utilizing Lambda UDFs and also you don’t need them to have an effect on your account’s Lambda concurrency a lot, you may need to set a reserved concurrency for his or her particular capabilities to function with.
Be taught extra about reserved concurrency in Lambda.
Integration and exterior providers
Name present exterior providers for optimum execution
In some instances, it could be value contemplating utilizing present exterior providers or elements of your software as an alternative of re-implementing the identical duties your self within the Lambda code. For instance, you should utilize Open Coverage Agent (OPA) for coverage checking, a managed service Protegrity to guard your delicate knowledge, there are additionally a wide range of providers offering {hardware} acceleration for computationally heavy duties.
Notice that some providers have their very own batching management with a restricted batch measurement. For that we applied a per-function batch row depend setting MAX_BATCH_ROWS as a clause within the Lambda UDF definition.
To study extra on the exterior service interplay utilizing Lambda UDFs refer the next hyperlinks:
Conclusion
Lambda UDFs present a strategy to lengthen your knowledge warehouse capabilities. By implementing the very best practices from this publish, it’s possible you’ll assist optimize your Lambda UDFs for efficiency and price effectivity.The important thing takeaways from this publish are:
- efficiency optimization, displaying how to decide on environment friendly programming languages and instruments, reduce payload sizes, and leverage batch processing to cut back execution time and prices
- scalability administration, displaying learn how to configure applicable concurrency settings at each account and performance ranges to deal with various workloads successfully
- integration effectivity, explaining learn how to profit from exterior providers to keep away from reinventing performance whereas sustaining optimum efficiency.
For extra info, go to the Redshift documentation and discover the combination examples referenced on this publish.
In regards to the writer