

{kind=link}
5 Important Safety Patterns for Sturdy Agentic AI
Picture by Editor
Introduction
Agentic AI, which revolves round autonomous software program entities known as brokers, has reshaped the AI panorama and influenced lots of its most seen developments and tendencies in recent times, together with functions constructed on generative and language fashions.
With any main expertise wave like agentic AI comes the necessity to safe these programs. Doing so requires a shift from static information safety to safeguarding dynamic, multi-step behaviors. This text lists 5 key safety patterns for sturdy AI brokers and highlights why they matter.
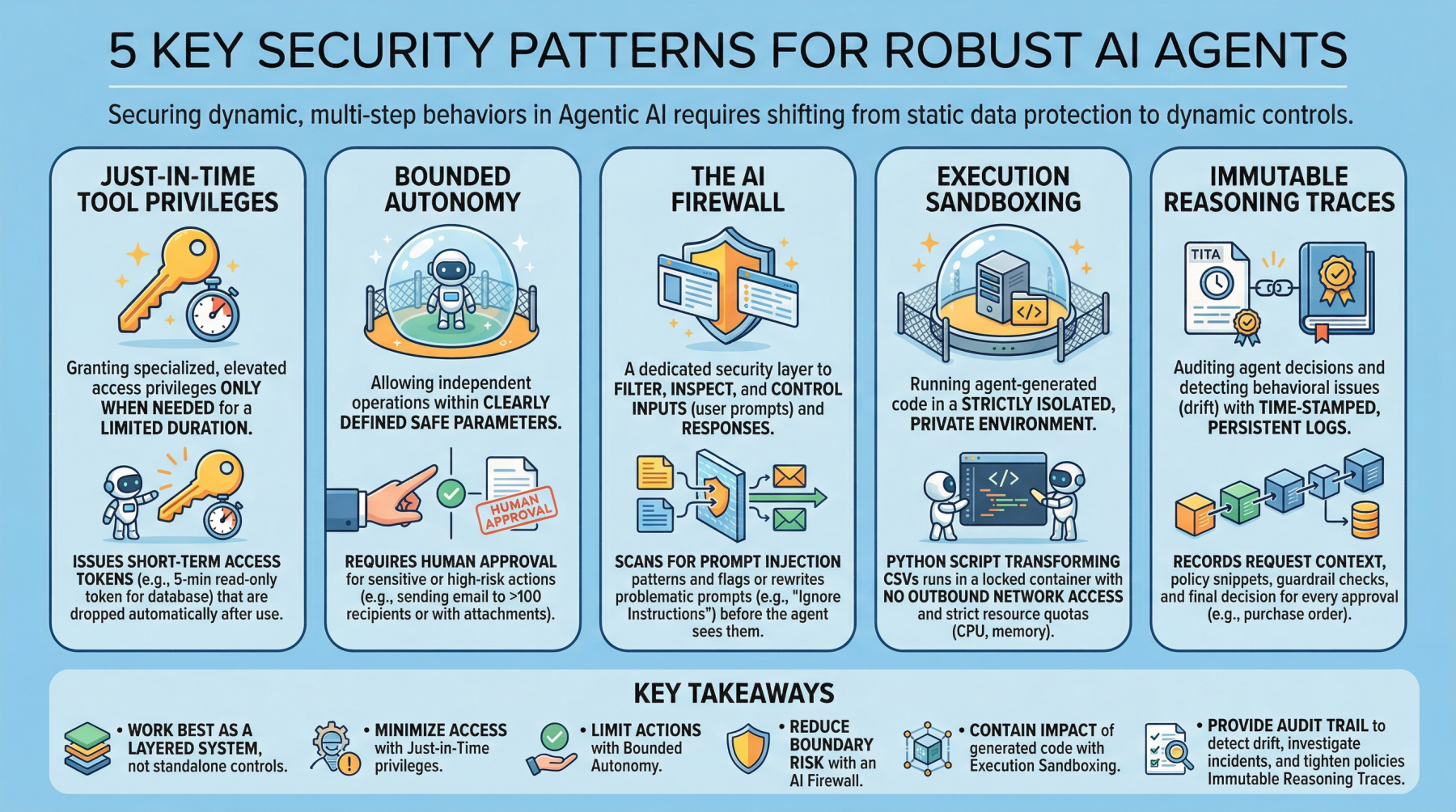
1. Simply-in-Time Software Privileges
Usually abbreviated as JIT, this can be a safety mannequin that grants customers or functions specialised or elevated entry privileges solely when wanted, and just for a restricted time period. It stands in distinction to traditional, everlasting privileges that stay in place until manually modified or revoked. Within the realm of agentic AI, an instance can be issuing quick time period entry tokens to limits the “blast radius” if the agent turns into compromised.
Instance: Earlier than an agent runs a billing reconciliation job, it requests a narrowly scoped, 5-minute read-only token for a single database desk and routinely drops the token as quickly because the question completes.
2. Bounded Autonomy
This safety precept permits AI brokers to function independently inside a bounded setting, that means inside clearly outlined protected parameters, putting a steadiness between management and effectivity. That is particularly vital in high-risk situations the place catastrophic errors from full autonomy will be averted by requiring human approval for delicate actions. In observe, this creates a management aircraft to cut back threat and help compliance necessities.
Instance: An agent could draft and schedule outbound emails by itself, however any message to greater than 100 recipients (or containing attachments) is routed to a human for approval earlier than sending.
3. The AI Firewall
This refers to a devoted safety layer that filters, inspects, and controls inputs (person prompts) and subsequent responses to safeguard AI programs. It helps shield towards threats corresponding to immediate injection, information exfiltration, and poisonous or policy-violating content material.
Instance: Incoming prompts are scanned for prompt-injection patterns (for instance, requests to disregard prior directions or to disclose secrets and techniques), and flagged prompts are both blocked or rewritten right into a safer type earlier than the agent sees them.
4. Execution Sandboxing
Take a strictly remoted, personal setting or community perimeter and run any agent-generated code inside it: this is named execution sandboxing. It helps stop unauthorized entry, useful resource exhaustion, and potential information breaches by containing the impression of untrusted or unpredictable execution.
Instance: An agent that writes a Python script to remodel CSV information runs it inside a locked-down container with no outbound community entry, strict CPU/reminiscence quotas, and a read-only mount of the enter information.
5. Immutable Reasoning Traces
This observe helps auditing autonomous agent selections and detecting behavioral points corresponding to drift. It entails constructing time-stamped, tamper-evident, and chronic logs that seize the agent’s inputs, key intermediate artifacts used for decision-making, and coverage checks. It is a essential step towards transparency and accountability for autonomous programs, significantly in high-stakes utility domains like procurement and finance.
Instance: For each buy order the agent approves, it data the request context, the retrieved coverage snippets, the utilized guardrail checks, and the ultimate choice in a write-once log that may be independently verified throughout audits.
Key Takeaways
These patterns work greatest as a layered system quite than standalone controls. Simply-in-time software privileges decrease what an agent can entry at any second, whereas bounded autonomy limits which actions it may take with out oversight. The AI firewall reduces threat on the interplay boundary by filtering and shaping inputs and outputs, and execution sandboxing accommodates the impression of any code the agent generates or executes. Lastly, immutable reasoning traces present the audit path that allows you to detect drift, examine incidents, and repeatedly tighten insurance policies over time.
| Safety Sample | Description |
|---|---|
| Simply-in-Time Software Privileges | Grant short-lived, narrowly scoped entry solely when wanted to cut back the blast radius of compromise. |
| Bounded Autonomy | Constrain which actions an agent can take independently, routing delicate steps via approvals and guardrails. |
| The AI Firewall | Filter and examine prompts and responses to dam or neutralize threats like immediate injection, information exfiltration, and poisonous content material. |
| Execution Sandboxing | Run agent-generated code in an remoted setting with strict useful resource and entry controls to include hurt. |
| Immutable Reasoning Traces | Create time-stamped, tamper-evident logs of inputs, intermediate artifacts, and coverage checks for auditability and drift detection. |
Collectively, these limitations scale back the prospect of a single failure turning right into a systemic breach, with out eliminating the operational advantages that make agentic AI interesting.