

{kind=link}
Simply 3 months after the discharge of their state-of-the-art mannequin Gemini 3 Professional, Google DeepMind is right here with its newest iteration: Gemini 3.1 Professional.
A radical improve by way of capabilities and security, Gemini 3.1 Professional mannequin strives to be accessible and operable by all. No matter your choice, platform, buying energy, the mannequin has rather a lot to supply for all of the customers.
I’d be testing the capabilities of Gemini 3.1 Professional and would elaborate on its key options. From methods to entry Gemini 3.1 Professional to benchmarks, all issues about this new mannequin has been touched upon on this article.
Gemini 3.1 Professional: What’s new?
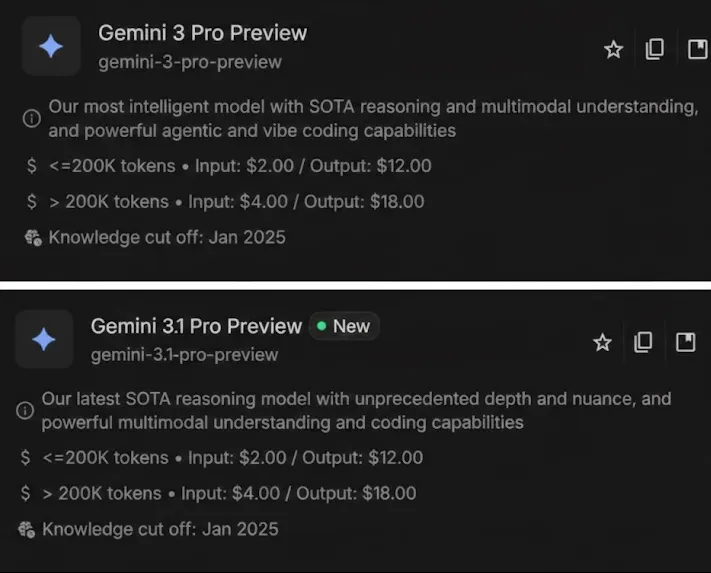
Gemini 3.1 Professional is the most recent member of the Gemini mannequin household. As common the mannequin comes with an astounding variety of options and enhancements from the previous. A few of the most noticeable one are:
- 1 Million Context Window: Maintains the industry-leading 1 million token enter capability, permitting it to course of over 1,500 pages of textual content or whole code repositories in a single immediate.
- Superior Reasoning Efficiency: It delivers greater than double the reasoning efficiency of Gemini 3 Professional, scoring 77.1% on the ARC-AGI-2 benchmark.
- Enhanced Agentic Reliability: Particularly optimized for autonomous workflows, together with a devoted API endpoint (gemini-3.1-pro-preview-customtools) for high-precision software orchestration and bash execution.
- Pricing: The associated fee/token of the most recent mannequin is identical as that of its predecessor. For these accustomed to the Professional variant, they’re getting a free improve.
- Superior Vibe Coding: The mannequin handles visible coding exceptionally properly. It may generate website-ready, animated SVGs purely by code, which means crisp scaling and tiny file sizes.
- Hallucinations: Gemini 3.1 Professional has tacked the hallucinations downside head on by lowering its fee of hallucinations from 88% to 50% throughout AA-Omniscience: Information and Hallucination Benchmark
- Granular Considering: The mannequin provides extra granularity to the considering possibility supplied by its predecessor. Now the customers can select between excessive, medium and low considering parameters.
| Considering Stage | Gemini 3.1 Professional | Gemini 3 Professional | Gemini 3 Flash | Description |
| Minimal | Not supported | Not supported | Supported |
Matches the no considering setting for many queries. The mannequin might imagine minimally for complicated coding duties. Minimizes latency for chat or excessive throughput purposes. |
| Low | Supported | Supported | Supported | Minimizes latency and value. Greatest for easy instruction following or high-throughput purposes. |
| Medium | Supported | Not supported | Supported | Balanced reasoning for many duties. |
| Excessive | Supported (Default, Dynamic) | Supported (Default, Dynamic) | Supported (Default, Dynamic) | Maximizes reasoning depth. Could improve latency, however outputs are extra fastidiously reasoned. |
Arms-On: Let’s have some enjoyable
All of the discuss on the planet wouldn’t quantity to something if the efficiency falls flat in apply. To guage Gemini 3.1 Professional correctly, I examined it throughout three classes:
- Advanced reasoning
- Code technology & debugging
- Lengthy-context synthesis
Process 1: Multi-Step Logical Reasoning
What this checks: Chain-of-thought reasoning, constraint dealing with, and hallucination resistance.
Immediate:
“You’re given the next state of affairs:
5 analysts — A, B, C, D, and E — are assigned to 3 initiatives: Alpha, Beta, and Gamma.
Guidelines:
1. Every challenge should have at the very least one analyst.
2. A can not work with C.
3. B should be assigned to the identical challenge as D.
4. E can’t be on Alpha.
5. No challenge can have greater than three analysts.
Query: Record all legitimate task mixtures. Present your reasoning clearly and guarantee no rule is violated.
“
Response:
Gemini 3.1 Professional dealt with constraint-heavy logic with out collapsing into contradictions, which is the place most fashions stumble. The consistency and readability in enumerating legitimate mixtures confirmed critical reasoning depth.
Process 2: Code Technology & Refactoring
What this checks: Structured considering, edge-case consciousness, code correctness, and manufacturing realism.
Immediate:
“You’re given the next Python operate:
def process_orders(orders):
complete = 0
for order in orders:
if order["status"] == "accomplished":
complete += order["amount"]
return completeRefactor this operate to:
1. Deal with lacking keys safely.
2. Ignore detrimental quantities.
3. Log skipped invalid entries.
4. Be production-ready with kind hints and docstrings.
5. Embody unit checks for edge instances.
Return clear, well-structured Python code solely.
“
Response:
import logging
import unittest
from typing import Record, Dict, Any
logger = logging.getLogger(__name__)
def process_orders(orders: Record[Dict[str, Any]]) -> float:
"""
Course of an inventory of order dictionaries and calculate
the overall quantity of accomplished orders.
"""
complete: float = 0.0
if not isinstance(orders, listing):
logger.error("'orders' should be an inventory.")
return complete
for index, order in enumerate(orders):
if not isinstance(order, dict):
logger.warning("Skipping index %d: Not a dictionary.", index)
proceed
if order.get("standing") != "accomplished":
proceed
if "quantity" not so as:
logger.warning("Skipping index %d: Lacking 'quantity'.", index)
proceed
quantity = order["amount"]
if not isinstance(quantity, (int, float)) or isinstance(quantity, bool):
logger.warning("Skipping index %d: 'quantity' should be numeric.", index)
proceed
if quantity < 0:
logger.warning("Skipping index %d: Damaging quantity (%.2f).", index, quantity)
proceed
complete += float(quantity)
return complete
class TestProcessOrders(unittest.TestCase):
def setUp(self):
logging.disable(logging.WARNING)
def tearDown(self):
logging.disable(logging.NOTSET)
def test_valid_completed_orders(self):
orders = [
{"status": "completed", "amount": 100},
{"status": "completed", "amount": 50.5}
]
self.assertEqual(process_orders(orders), 150.5)
def test_ignore_pending_orders(self):
orders = [
{"status": "pending", "amount": 100},
{"status": "completed", "amount": 50}
]
self.assertEqual(process_orders(orders), 50.0)
def test_missing_keys_skipped(self):
orders = [
{"amount": 100},
{"status": "completed"},
{"status": "completed", "amount": 20}
]
self.assertEqual(process_orders(orders), 20.0)
def test_negative_amounts_ignored(self):
orders = [
{"status": "completed", "amount": -10},
{"status": "completed", "amount": 3The refactored code felt production-aware, not toy-level. It anticipated edge cases, enforced type safety, and included meaningful tests. This is the kind of output that actually respects real-world development standards.
Task 3: Long-Context Analytical Synthesis
What this tests: Information compression, structured summarization, and reasoning across context.
Prompt:
“Below is a synthetic business report:
Company: NovaGrid AI
2022 Revenue: $12M
2023 Revenue : $28M
2024 Revenue: $46M
Customer churn increased from 4% to 11% in 2024.
R&D spending increased by 70% in 2024.
Operating margin dropped from 18% to 9%.
Enterprise customers grew by 40%.
SMB customers declined by 22%.
Cloud infrastructure costs doubled.
Task:
1. Diagnose the most likely root causes of margin decline.
2. Identify strategic risks.
3. Recommend 3 data-backed actions.
4. Present your answer in a structured executive memo format.
“
Response:
It connected financial signals, operational shifts, and strategic risks into a coherent executive narrative. The ability to diagnose margin pressure while balancing growth signals shows strong business reasoning. It read like something a sharp strategy consultant would draft, not a generic summary.
Note: I didn’t use the standard “Create a dashboard” tasks as most latest models like Sonnet 4.6, Kimi K 2.5, are easily able to create one. So it wouldn’t offer much of a challenge to a model this capable.
How to access Gemini 3.1 Pro?
Unlike the previous Pro models, Gemini 3.1 Pro is freely accessible by all the users on the platform of their choice.
Now that you’ve made up your mind about using Gemini 3.1 Pro, let’s see how you can access the model.
- Gemini Web UI: Free and Gemini Advanced users now have 3.1 Pro available under the model section option.
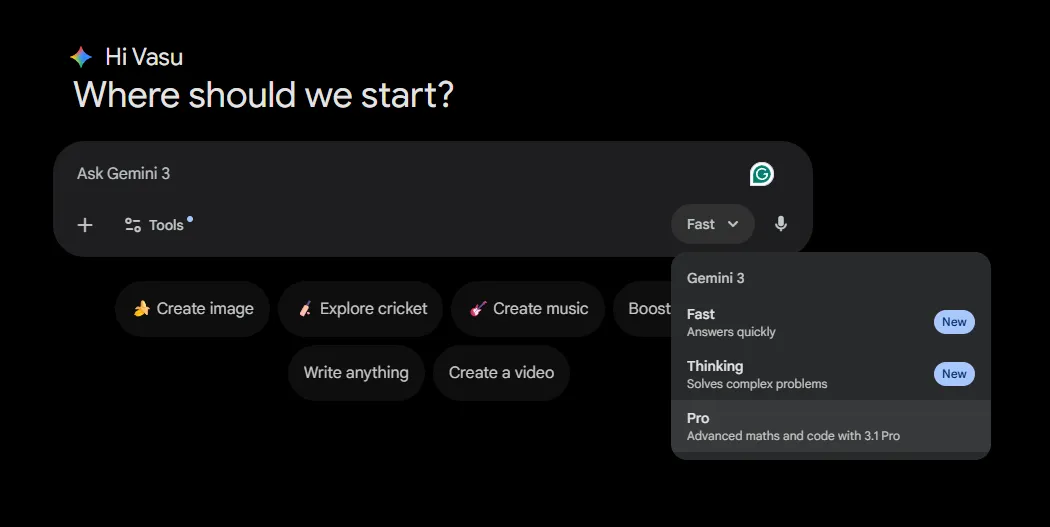
- API: Available via Google AI Studio for developers (models/Gemini-3.1-pro).
| Model | Base Input Tokens | 5m Cache Writes | 1h Cache Writes | Cache Hits & Refreshes | Output Tokens |
| Gemini 3.1 Pro (≤200 K tokens) | $2 / 1M tokens | ~$0.20–$0.40 / 1M tokens | ~$4.50 / 1M tokens per hour storage | Not formally documented | $12 / 1M tokens |
| Gemini 3.1 Pro (>200 K tokens) | $4 / 1M tokens | ~$0.20–$0.40 / 1M tokens | ~$4.50 / 1M tokens per hour storage | Not formally documented | $18 / 1M tokens |
- Cloud Platforms: Being rolled out to NotebookLM, Google Cloud’s Vertex AI, and Microsoft Foundry.
Benchmarks
To quantify how good this model is, the benchmarks would assist.
There is a lot to decipher here. But the most astounding improvement of all is certainly in Abstract reasoning puzzles.
Let me put things into perspective: Gemini 3 Pro released with a ARC-AGI-2 score of 31.1%. This was the highest for the time and considered a breakthrough for LLM standards. Fast forward just 3 months, and that score has been eclipsed by its own successor by double the margin!
This is the rapid pace at which AI models are improving.
If you’re unfamiliar with what these benchmarks test, read this article: AI Benchmarks.
Conclusion: Powerful and Accessible
Gemini 3.1 Pro proves it’s more than a flashy multimodal model. Across reasoning, code, and analytical synthesis, it demonstrates real capability with production relevance. It’s not flawless and still demands structured prompting and human oversight. But as a frontier model embedded in Google’s ecosystem, it’s powerful, competitive, and absolutely worth serious evaluation.
Frequently Asked Questions
A. It is built for advanced reasoning, long-context processing, multimodal understanding, and production-grade AI applications.
A. Developers can access it via Google AI Studio for prototyping or Vertex AI for scalable, enterprise deployments.
A. It performs strongly but still requires structured prompting and human oversight to ensure accuracy and reduce hallucinations.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.
Login to continue reading and enjoy expert-curated content.