

{kind=link}
This weblog was written in collaboration with Fan Bu, Jason Mackay, Borya Sobolev, Dev Khanolkar, Ali Dabir, Puneet Kamal, Li Zhang, and Lei Jin.
“The whole lot is a file”; some are databases
Introduction
Machine information underpins observability and prognosis in trendy computing programs, together with logs, metrics, telemetry traces, configuration snapshots, and API response payloads. In follow, this information is embedded into prompts to kind an interleaved composition of natural-language directions and enormous machine-generated payloads, sometimes represented as JSON blobs or Python/AST literals. Whereas giant language fashions excel at reasoning textual content and code, they regularly wrestle with machine-generated sequences – significantly when these are lengthy, deeply nested, and dominated by repetitive construction.
We repeatedly observe three failure modes:
- Token explosion from verbosity: Nested keys and repeated schema dominate the context window, fragmenting the info.
- Context rot: The mannequin misses the “needle” hidden inside giant payloads and drifts from the instruction.
- Weak spot on numeric/categorical sequence reasoning: Lengthy sequences obscure patterns resembling anomalies, traits, and entity relationships.The bottleneck isn’t merely in regards to the size of the inputs. Machine information as an alternative requires structural transformation and sign enhancement in order that the identical info is offered in representations aligned with a mannequin’s strengths.
“The whole lot is a file”; some are databases
Anthropic efficiently popularized the notion that “bash is all you want” for agentic workflows, particularly for vibe coding, by absolutely leveraging the file system and composable bash instruments. In machine-data-heavy settings of context engineering, we argue that rules from database administration apply: moderately than forcing the mannequin to course of uncooked blobs instantly, full-fidelity payloads might be saved in a datastore, permitting the agent to question them and generate optimized hybrid information views that align with the LLM’s reasoning strengths utilizing a subset of straightforward SQL statements.
Hybrid information views for machine information – “easy SQL is what you want”
These hybrid views are impressed by the database idea of hybrid transactional/analytical processing (HTAP), the place completely different information layouts serve completely different workloads. Equally, we preserve hybrid representations of the identical payload in order that completely different parts of the info could be extra successfully understood by the LLM.
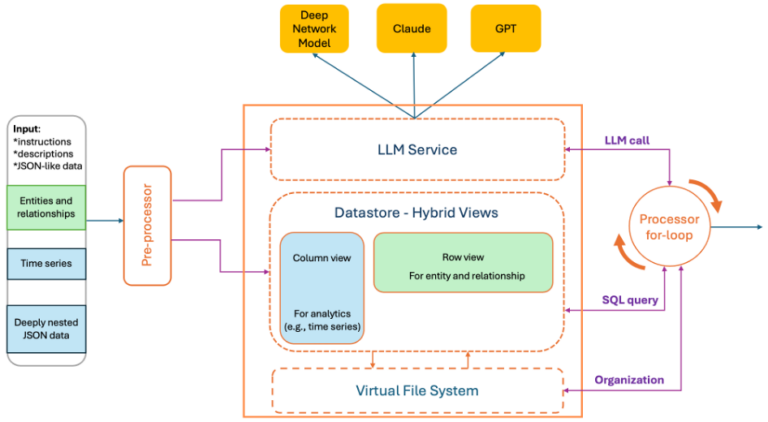
To this finish, we introduce ACE (Analytics Context Engineering) for machine information—a framework for setting up and managing analytics context for LLMs. ACE combines a digital file system (mapping observability APIs to recordsdata and transparently intercepting Bash instruments to keep away from unscalable MCP calls) with the simplicity of Bash for intuitive, high-level group, whereas incorporating database-style administration strategies to allow exact, fine-grained management over low-level information entries.
Deep Community Mannequin – ACE
ACE is utilized in Cisco AI Canvas runbook reasoning. It converts uncooked prompts and machine payloads into hybrid views in instruction-preserving contexts that LLMs can reliably devour. ACE was initially designed to boost the Deep Community Mannequin (DNM), a Cisco purpose-built LLM for networking domains. To assist a broader vary of LLM fashions, ACE was subsequently applied as a standalone service.
At a excessive degree:
- A preprocessor parses the person immediate—comprising pure language and embedded JSON/AST blobs as a single string—and produces hybrid information views together with non-compulsory language summaries (e.g., statistics or anomaly traces), all inside a specified token finances.
- A datastore retains a full-fidelity copy of the unique machine information. This permits the LLM context to stay small whereas nonetheless enabling full solutions.
- A processor for-loop inspects the LLM output and conditionally queries the datastore to counterpoint the response, producing a whole, structured last response.
Row-oriented + Columnar views
We generate complementary representations of the identical payload:
- Columnar view (field-centric). For analytics duties (e.g., line/bar chart, pattern, sample, anomaly detection), we remodel nested JSON into flattened dotted paths and per-field sequences. This eliminates repeated prefixes, makes associated information contiguous, and eases the computation per subject.
- Row-oriented view (entry-centric). To assist relationship reasoning — resembling has-a and is-a relationships, together with entity membership and affiliation mining — we offer a row-oriented illustration that preserves report boundaries and native context throughout fields. As a result of this view doesn’t impose an inherent ordering throughout rows, it naturally allows the applying of statistical strategies to rank entries by relevance. Particularly, we design a modified TF-IDF algorithm, based mostly on question relevance, phrase reputation, and variety, to rank rows.
Rendering format: We offer a number of codecs for rendering content material. The default format stays JSON; though it’s not at all times essentially the most token-efficient illustration, our expertise reveals that it tends to work finest with most current LLMs. As well as, we provide a custom-made rendering format impressed by the open-source TOON mission and Markdown, with a number of key variations. Relying on the schema’s nesting construction, information are rendered both as compact flat lists with dotted key paths or utilizing an indented illustration. Each approaches assist the mannequin infer structural relationships extra successfully.
The idea of a hybrid view is nicely established in database programs, significantly within the distinction between row-oriented and column-oriented storage, the place completely different information layouts are optimized for various workloads. Algorithmically, we assemble a parsing tree for every JSON/AST literal blob and traverse the tree to selectively remodel nodes utilizing an opinionated algorithm that determines whether or not every part is best represented in a row-oriented or columnar view, whereas preserving instruction constancy below strict token constraints.
Design precept
- ACE follows a precept of simplicity, favoring a small set of generic instruments. It embeds analytics instantly into the LLM’s iterative reasoning-and-execution loop, utilizing a restricted subset of SQL along with Bash instruments over a digital file system because the native mechanisms for information administration and analytics.
- ACE prioritizes context-window optimization, maximizing the LLM’s reasoning capability inside bounded prompts whereas sustaining a whole copy of the info in an exterior datastore for query-based entry. Rigorously designed operators are utilized to columnar views, whereas rating strategies are utilized to row-oriented views.
In manufacturing, this strategy drastically reduces immediate dimension, price, and inference latency whereas enhancing reply high quality.
Illustrative examples
We consider token utilization and reply high quality (measured by an LLM-as-a-judge reasoning rating) throughout consultant real-world workloads. Every workload contains unbiased duties equivalent to particular person steps in a troubleshooting workflow. As a result of our analysis focuses on single-step efficiency, we don’t embody full agentic prognosis trajectories with device calls. Past considerably lowering token utilization, ACE additionally achieves increased reply accuracy.
1. Slot filling:
Community runbook prompts mix directions with JSON-encoded board and chat state, prior variables, device schemas, and person intent. The duty is to floor a handful of fields buried in dense, repetitive machine payloads.
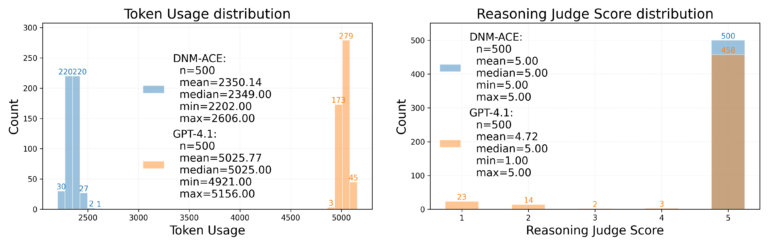
Our strategy reduces the common token rely from 5,025 to 2,350 and corrects 42 errors (out of 500 assessments) in comparison with instantly calling GPT-4.1.
2. Anomalous behaviors:
The duty is to deal with a broad spectrum of machine information evaluation duties in observability workflows.
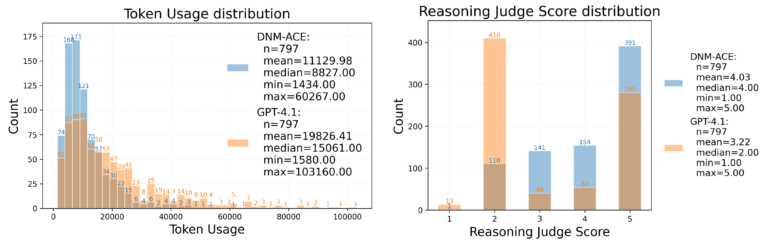
By making use of anomaly detection operators to columnar views to offer further contextual info, our strategy will increase the common reply high quality rating from 3.22 to 4.03 (out of 5.00), a 25% improve of accuracy, whereas reaching a 44% discount in token utilization throughout 797 samples.
3. Line chart:
The enter sometimes consists of time-series metrics information which might be arrays of measurement information collected at common intervals. The duty is to render this information utilizing frontend charting libraries.
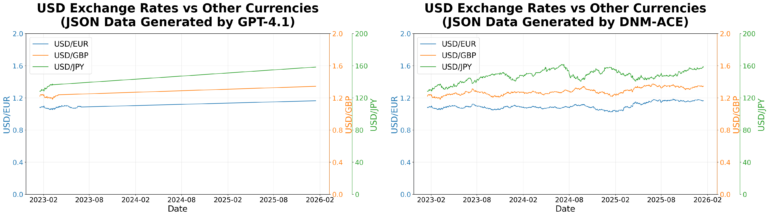
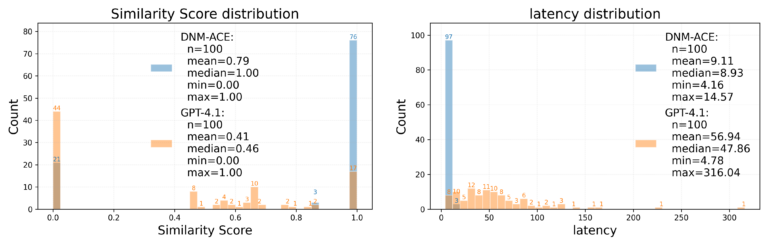
Immediately calling the LLM typically leads to incomplete information rendering on account of lengthy output sequences, even when the enter suits throughout the context window. Within the determine above, LLM produces a line chart with solely 40-120 factors per collection as an alternative of the anticipated 778, resulting in lacking information factors. Throughout 100 take a look at samples, as proven within the following two figures, our strategy achieves roughly 87% token financial savings, reduces common end-to-end latency from 47.8 s to eight.9 s, and improves the reply high quality rating (similarity_overall) from 0.410 to 0.786 (out of 1.00).
4. Benchmark abstract:
Along with the three examples mentioned above, we evaluate key efficiency metrics throughout a variety of networking-related duties within the following desk.
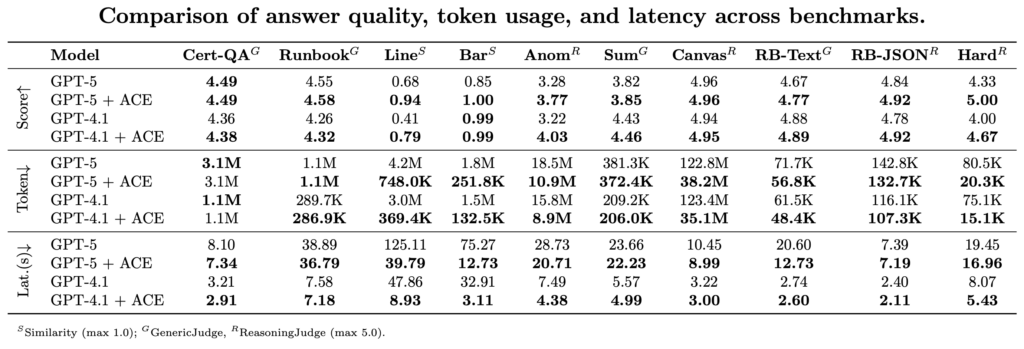
Observations: Intensive testing throughout a variety of benchmarks demonstrates that ACE reduces token utilization by 20–90% relying on the duty, whereas sustaining and in lots of instances enhancing reply accuracy. In follow, this successfully delivers an “limitless” context window for prompts involving machine information.
The above analysis covers solely particular person steps inside an agentic workflow. Design rules grounded in a digital file system and database administration allow ACE to work together with the LLM’s reasoning course of by extracting salient indicators from the huge quantity of observability information by means of multi-turn interactions.