

{kind=link}
As the times go by, there are extra benchmarks than ever. It’s laborious to maintain observe of each HellaSwag or DS-1000 that comes out. Additionally, what are they even for? Bunch of cool wanting names slapped on prime of a benchmark to make them look cooler… Probably not.
Aside from the zany naming that these benchmarks are given, they serve a really sensible and cautious function. Every of them take a look at the mannequin throughout a set of assessments, to see how properly the mannequin performs to the best requirements. These requirements are often how properly they fare as in comparison with a standard human.
This text will help you in determining what these benchmarks are, and which one is used to check which sort of mannequin, and when?
Normal Intelligence: Can It really suppose?
These benchmarks take a look at how properly the AI fashions emulate the considering capability of people.
1. MMLU – Multitask Language Understanding
MMLU is the baseline “normal intelligence examination” for language fashions. It incorporates hundreds of multiple-choice questions throughout 60 topics, with 4 choices per query, masking fields like drugs, legislation, math, and laptop science.
It’s not good, nevertheless it’s common. If a mannequin skips MMLU, folks instantly ask why? That alone tells you ways necessary it’s.
Utilized in: Normal-purpose language fashions (GPT, Claude, Gemini, Llama, Mistral)
Paper: https://arxiv.org/abs/2009.03300
2. HLE – Humanity’s Final Examination
HLE exists to reply a easy query: Can fashions deal with expert-level reasoning with out counting on memorization?
The benchmark pulls collectively extraordinarily troublesome questions throughout arithmetic, pure sciences, and humanities. These questions are intentionally filtered to keep away from web-searchable information and customary coaching leakage.
The query composition of the benchmark is likely to be just like MMLU, however not like MMLU HLE is designed to check the LLMs to the hilt, which is depicted on this efficiency metric:
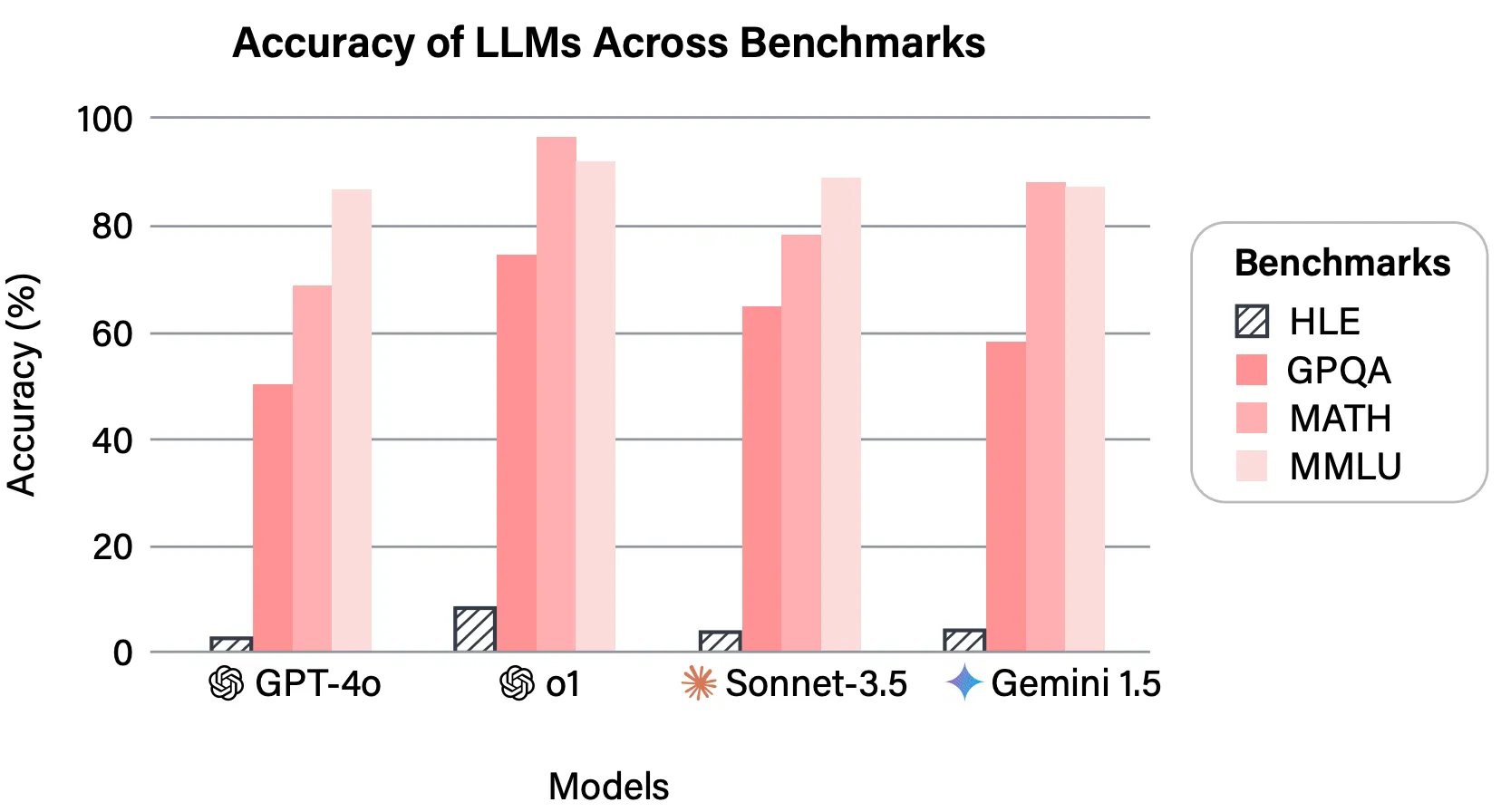
As frontier fashions started saturating older benchmarks, HLE shortly grew to become the brand new reference level for pushing the bounds!
Utilized in: Frontier reasoning fashions and research-grade LLMs (GPT-4, Claude Opus 4.5, Gemini Extremely)
Paper: https://arxiv.org/abs/2501.14249
Mathematical Reasoning: Can It motive procedurally?
Reasoning is what makes people particular i.e. reminiscence and studying are each put into use for inference. These benchmarks take a look at the extent of success when reasoning work is carried out by LLMs.
3. GSM8K — Grade College Math (8,000 Issues)
GSM8K assessments whether or not a mannequin can motive step-by-step by way of phrase issues, not simply output solutions. Consider chain-of-thought, however as an alternative of evaluating primarily based on the ultimate consequence, your complete chain is checked.
It’s easy! However extraordinarily efficient, and laborious to faux. That’s why it exhibits up in virtually each reasoning-focused analysis.
Utilized in: Reasoning-focused language fashions and chain-of-thought fashions (GPT-5, PaLM, LLaMA)
Paper: https://arxiv.org/abs/2110.14168
4. MATH – Arithmetic Dataset for Superior Downside Fixing
This benchmark raises the ceiling. Issues come from competition-style arithmetic and require abstraction, symbolic manipulation, and lengthy reasoning chains.
The inherent problem of mathematical issues helps in testing the mannequin’s capabilities. Fashions that rating properly on GSM8K however collapse on MATH are instantly uncovered.
Utilized in: Superior reasoning and mathematical LLMs (Minerva, GPT-4, DeepSeek-Math)
Paper: https://arxiv.org/abs/2103.03874
Software program Engineering: Can it exchange human coders?
Simply kidding. These benchmarks take a look at how properly a LLM creates error-free code.
5. HumanEval – Human Analysis Benchmark for Code Technology
HumanEval is probably the most cited coding benchmark in existence. It grades fashions primarily based on how properly they write Python features that go hidden unit assessments. No subjective scoring. Both the code works or it doesn’t.
In the event you see a coding rating in a mannequin card, that is virtually all the time one in all them.
Utilized in: Code era fashions (OpenAI Codex, CodeLLaMA, DeepSeek-Coder)
Paper: https://arxiv.org/abs/2107.03374
6. SWE-Bench – Software program Engineering Benchmark
SWE-Bench assessments real-world engineering, not toy issues.
Fashions are given precise GitHub points and should generate patches that repair them inside actual repositories. This benchmark issues as a result of it mirrors how folks really wish to use coding fashions.
Utilized in: Software program engineering and agentic coding fashions (Devin, SWE-Agent, AutoGPT)
Paper: https://arxiv.org/abs/2310.06770
Conversational Means: Can it behave in a humane method?
These benchmarks take a look at whether or not the fashions are capable of work throughout a number of turns, and the way properly it fares in distinction to a human.
7. MT-Bench – Multi-Flip Benchmark
MT-Bench evaluates how fashions behave throughout a number of conversational turns. It assessments coherence, instruction retention, reasoning consistency, and verbosity.
Scores are produced utilizing LLM-as-a-judge, which made MT-Bench scalable sufficient to turn into a default chat benchmark.
Utilized in: Chat-oriented conversational fashions (ChatGPT, Claude, Gemini)
Paper: https://arxiv.org/abs/2306.05685
8. Chatbot Area – Human Choice Benchmark
Chatbot Area sidesteps metrics and lets people resolve.
Fashions are in contrast head-to-head in nameless battles, and customers vote on which response they like. Rankings are maintained utilizing Elo scores.
Regardless of noise, this benchmark carries severe weight as a result of it displays actual consumer desire at scale.
Utilized in: All main chat fashions for human desire analysis (ChatGPT, Claude, Gemini, Grok)
Paper: https://arxiv.org/abs/2403.04132
Data Retrieval: Can it write a weblog?
Or extra particularly: Can It Discover the Proper Data When It Issues?
9. BEIR – Benchmarking Data Retrieval
BEIR is the usual benchmark for evaluating retrieval and embedding fashions.
It aggregates a number of datasets throughout domains like QA, fact-checking, and scientific retrieval, making it the default reference for RAG pipelines.
Utilized in: Retrieval fashions and embedding fashions (OpenAI text-embedding-3, BERT, E5, GTE)
Paper: https://arxiv.org/abs/2104.08663
10. Needle-in-a-Haystack – Lengthy-Context Recall Take a look at
This benchmark assessments whether or not long-context fashions really use their context.
A small however crucial reality is buried deep inside an extended doc. The mannequin should retrieve it appropriately. As context home windows grew, this grew to become the go-to well being verify.
Utilized in: Lengthy-context language fashions (Claude 3, GPT-4.1, Gemini 2.5)
Reference repo: https://github.com/gkamradt/LLMTest_NeedleInAHaystack
Enhanced Benchmarks
These are simply the preferred benchmarks which can be used to judge LLMs. There are way more from the place they got here from, and even these have been outmoded by enhanced dataset variants like MMLU-Professional, GSM16K and so forth. However because you now have a sound understanding of what these benchmarks signify, wrapping round enhancements can be straightforward.
The aforementioned data must be used as a reference for probably the most generally used LLM benchmarks.
Incessantly Requested Questions
A. They measure how properly fashions carry out on duties like reasoning, coding, and retrieval in comparison with people.
A. It’s a normal intelligence benchmark testing language fashions throughout topics like math, legislation, drugs, and historical past.
A. It assessments if fashions can repair actual GitHub points by producing appropriate code patches.
I concentrate on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, information evaluation, and data retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.