

{kind=link}
Final up to date: December 17, 2025
Initially revealed: December 18, 2017
Amazon Knowledge Firehose helps Splunk Enterprise and Splunk Cloud as a supply vacation spot. This native integration between Splunk Enterprise, Splunk Cloud, and Amazon Knowledge Firehose is designed to make AWS information ingestion setup seamless, whereas providing a safe and fault-tolerant supply mechanism. We wish to allow clients to watch and analyze machine information from any supply and use it to ship operational intelligence and optimize IT, safety, and enterprise efficiency.
With Amazon Knowledge Firehose, clients can use a totally managed, dependable, and scalable information streaming resolution to Splunk. On this publish, we let you know a bit extra in regards to the Amazon Knowledge Firehose and Splunk integration. We additionally present you how one can ingest massive quantities of information into Splunk utilizing Amazon Knowledge Firehose.
Push vs. Pull information ingestion
Presently, clients use a mixture of two ingestion patterns, based on information supply and quantity, along with present firm infrastructure and experience:
- Pull-based method: Utilizing devoted pollers operating the favored Splunk Add-on for AWS to drag information from varied AWS companies akin to Amazon CloudWatch or Amazon S3.
- Push-based method: Streaming information instantly from AWS to Splunk HTTP Occasion Collector (HEC) by utilizing Amazon Knowledge Firehose. Examples of relevant information sources embrace CloudWatch Logs and Amazon Kinesis Knowledge Streams.
The pull-based method gives information supply ensures akin to retries and checkpointing out of the field. Nevertheless, it requires extra ops to handle and orchestrate the devoted pollers, that are generally operating on Amazon EC2 cases. With this setup, you pay for the infrastructure even when it’s idle.
Then again, the push-based method gives a low-latency scalable information pipeline made up of serverless sources like Amazon Knowledge Firehose sending on to Splunk indexers (by utilizing Splunk HEC). This method interprets into decrease operational complexity and value. Nevertheless, if you happen to want assured information supply then it’s important to design your resolution to deal with points akin to a Splunk connection failure or Lambda execution failure. To take action, you may use, for instance, AWS Lambda Lifeless Letter Queues.
How about getting one of the best of each worlds?
Let’s go over the brand new integration’s end-to-end resolution and study how Amazon Knowledge Firehose and Splunk collectively develop the push-based method right into a native AWS resolution for relevant information sources.
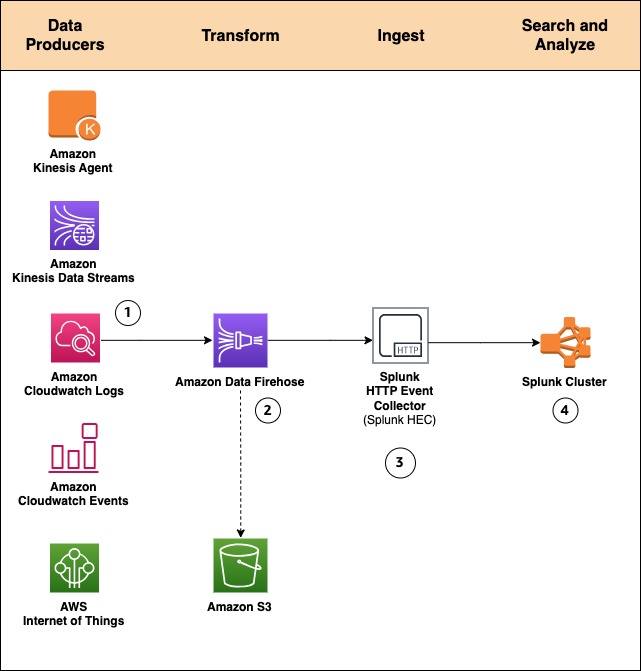
Through the use of a managed service like Amazon Knowledge Firehose for information ingestion into Splunk, we offer out-of-the-box reliability and scalability. One of many ache factors of the previous method was the overhead of managing the information assortment nodes (Splunk heavy forwarders). With the brand new Amazon Knowledge Firehose to Splunk integration, there are not any forwarders to handle or arrange. Knowledge producers (1) are configured by the AWS Administration Console to drop information into Amazon Knowledge Firehose.
You can too create your personal information producers. For instance, you’ll be able to drop information right into a Firehose supply stream by utilizing Amazon Kinesis Agent, or by utilizing the Firehose API (PutRecord(), PutRecordBatch()), or by writing to a Kinesis Knowledge Stream configured to be the information supply of a Firehose supply stream. For extra particulars, consult with Sending Knowledge to an Amazon Knowledge Firehose Supply Stream.
You may want to rework the information earlier than it goes into Splunk for evaluation. For instance, you may wish to enrich it or filter or anonymize delicate information. You are able to do so utilizing AWS Lambda and enabling information transformation in Amazon Knowledge Firehose. On this state of affairs, Amazon Knowledge Firehose is used to decompress the Amazon CloudWatch logs by enabling the function.
Programs fail on a regular basis. Let’s see how this integration handles exterior failures to ensure information sturdiness. In instances when Amazon Knowledge Firehose can’t ship information to the Splunk Cluster, information is routinely backed as much as an S3 bucket. You possibly can configure this function whereas creating the Firehose supply stream (2). You possibly can select to again up all information or solely the information that’s failed throughout supply to Splunk.
Along with utilizing S3 for information backup, this Firehose integration with Splunk helps Splunk Indexer Acknowledgments to ensure occasion supply. This function is configured on Splunk’s HTTP Occasion Collector (HEC) (3). It ensures that HEC returns an acknowledgment to Amazon Knowledge Firehose solely after information has been listed and is on the market within the Splunk cluster (4).
Now let’s have a look at a hands-on train that exhibits how one can ahead VPC circulation logs to Splunk.
How-to information
To course of VPC circulation logs, we implement the next structure.
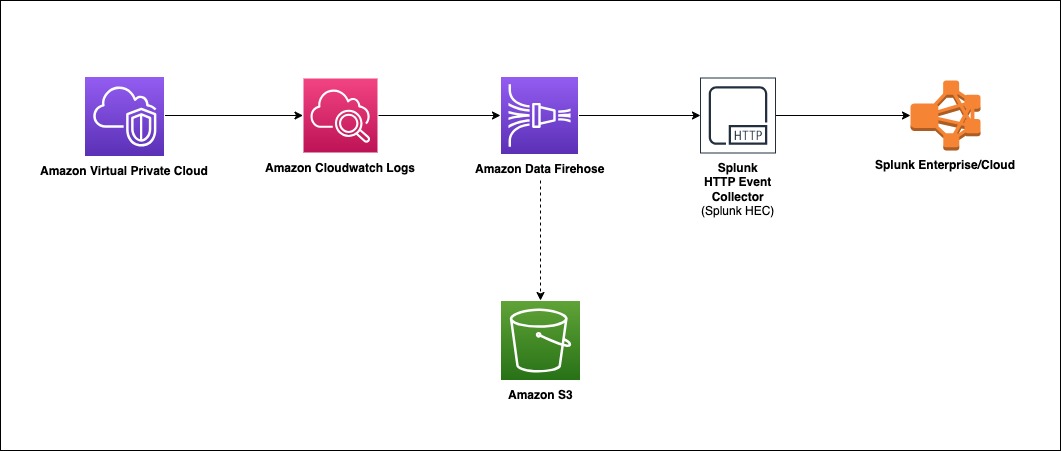
Amazon Digital Non-public Cloud (Amazon VPC) delivers circulation log information into an Amazon CloudWatch Logs group. Utilizing a CloudWatch Logs subscription filter, we arrange real-time supply of CloudWatch Logs to an Amazon Knowledge Firehose stream.
Knowledge coming from CloudWatch Logs is compressed with gzip compression. To work with this compression, we’ll allow decompression for the Firehose stream. Firehose then delivers the uncooked logs to the Splunk Http Occasion Collector (HEC).
If supply to the Splunk HEC fails, Firehose deposits the logs into an Amazon S3 bucket. You possibly can then ingest the occasions from S3 utilizing an alternate mechanism akin to a Lambda operate.
When information reaches Splunk (Enterprise or Cloud), Splunk parsing configurations (packaged within the Splunk Add-on for Amazon Knowledge Firehose) extract and parse all fields. They make information prepared for querying and visualization utilizing Splunk Enterprise and Splunk Cloud.
Walkthrough
Set up the Splunk Add-on for Amazon Knowledge Firehose
The Splunk Add-on for Amazon Knowledge Firehose permits Splunk (be it Splunk Enterprise, Splunk App for AWS, or Splunk Enterprise Safety) to make use of information ingested from Amazon Knowledge Firehose. Set up the Add-on on all of the indexers with an HTTP Occasion Collector (HEC). The Add-on is on the market for obtain from Splunkbase. For troubleshooting help, please consult with: AWS Knowledge Firehose troubleshooting documentation & Splunk’s official troubleshooting information
HTTP Occasion Collector (HEC)
Earlier than you should utilize Amazon Knowledge Firehose to ship information to Splunk, arrange the Splunk HEC to obtain the information. From Splunk internet, go to the Setting menu, select Knowledge Inputs, and select HTTP Occasion Collector. Select World Settings, guarantee All tokens is enabled, after which select Save. Then select New Token to create a brand new HEC endpoint and token. If you create a brand new token, make it possible for Allow indexer acknowledgment is checked.
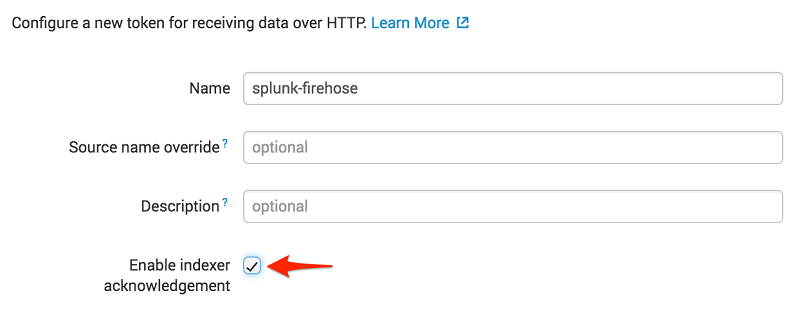
When prompted to pick a supply sort, choose aws:cloudwatchlogs:vpcflow

Create an S3 backsplash bucket
To supply for conditions during which Amazon Knowledge Firehose can’t ship information to the Splunk Cluster, we use an S3 bucket to again up the information. You possibly can configure this function to again up all information or solely the information that’s failed throughout supply to Splunk.
Observe: Bucket names are distinctive.
Create an Amazon Knowledge Firehose supply stream
On the AWS console, open the Amazon Knowledge Firehose console, and select Create Firehose Stream.
Choose DirectPUT because the supply and Splunk because the vacation spot.

If you’re utilizing Firehose to ship CloudWatch Logs and wish to ship decompressed information to your Firehose stream vacation spot, use Firehose Knowledge Format Conversion (Parquet, ORC) or Dynamic partitioning. It’s essential to allow decompression to your Firehose stream, try Ship decompressed Amazon CloudWatch Logs to Amazon S3 and Splunk utilizing Amazon Knowledge Firehose

Enter your Splunk HTTP Occasion Collector (HEC) data in vacation spot settings

Observe: Amazon Knowledge Firehose requires the Splunk HTTP Occasion Collector (HEC) endpoint to be terminated with a sound CA-signed certificates matching the DNS hostname used to connect with your HEC endpoint. You obtain supply errors if you’re utilizing a self-signed certificates.
On this instance, we solely again up logs that fail throughout supply.

To observe your Firehose supply stream, allow error logging. Doing this implies that you may monitor file supply errors. Create an IAM position for the Firehose stream by selecting Create new, or Select present IAM position.

You now get an opportunity to evaluate and alter the Firehose stream settings. If you end up happy, select Create Firehose Stream.
Create a VPC Circulate Log
To ship occasions from Amazon VPC, you want to arrange a VPC circulation log. If you have already got a VPC circulation log you wish to use, you’ll be able to skip to the “Publish CloudWatch to Amazon Knowledge Firehose” part.
On the AWS console, open the Amazon VPC service. Then select VPC, and select the VPC you wish to ship circulation logs from. Select Circulate Logs, after which select Create Circulate Log. If you happen to don’t have an IAM position that permits your VPC to publish logs to CloudWatch, select Create and use a brand new service position.

As soon as energetic, your VPC circulation log ought to appear like the next.

Publish CloudWatch to Amazon Knowledge Firehose
If you generate site visitors to or out of your VPC, the log group is created in Amazon CloudWatch. We create an IAM position to permit Cloudwatch to publish logs to the Amazon Knowledge Firehose Stream.
To permit CloudWatch to publish to your Firehose stream, you want to give it permissions.
Right here is the content material for TrustPolicyForCWLToFireHose.json.
Connect the coverage to the newly created position.
Right here is the content material for PermissionPolicyForCWLToFireHose.json.
The brand new log group has no subscription filter, so arrange a subscription filter. Setting this up establishes a real-time information feed from the log group to your Firehose supply stream. Choose the VPC circulation log and select Actions. Then select Subscription filters adopted by Create Amazon Knowledge Firehose subscription filter.


If you run the AWS CLI command previous, you don’t get any acknowledgment. To validate that your CloudWatch Log Group is subscribed to your Firehose stream, verify the CloudWatch console.
As quickly because the subscription filter is created, the real-time log information from the log group goes into your Firehose supply stream. Your stream then delivers it to your Splunk Enterprise or Splunk Cloud surroundings for querying and visualization. The screenshot following is from Splunk Enterprise.
As well as, you’ll be able to monitor and look at metrics related along with your supply stream utilizing the AWS console.

Conclusion
Though our walkthrough makes use of VPC Circulate Logs, the sample can be utilized in lots of different situations. These embrace ingesting information from AWS IoT, different CloudWatch logs and occasions, Kinesis Streams or different information sources utilizing the Kinesis Agent or Kinesis Producer Library. It’s possible you’ll use a Lambda blueprint or disable file transformation fully relying in your use case. For an extra use case utilizing Amazon Knowledge Firehose, try That is My Structure Video, which discusses how one can securely centralize cross-account information analytics utilizing Kinesis and Splunk.
If you happen to discovered this publish helpful, make sure to try Integrating Splunk with Amazon Kinesis Streams.
Concerning the Authors