

{kind=link}
What in the event you may construct a useful ChatGPT-like AI for $100? Andrej Karpathy’s new nanochat tells you precisely that! Launched on October 13, 2025, Karpathy’s nanochat venture is an open-source LLM coded in roughly 8,000 traces of PyTorch. It provides you an easy roadmap on find out how to practice a language mannequin from scratch and make your individual personal AI in a few hours. On this article, we’ll discuss in regards to the newly launched nanochat and find out how to correctly set it up for the coaching step-by-step.
What’s nanochat?
The nanochat repository gives a full-stack pipeline to coach a minimal ChatGPT clone. It takes care of all the things from tokenization to the tip net person interface. This technique is a successor to the earlier nanoGPT. It introduces key options equivalent to supervised fine-tuning (SFT), reinforcement studying (RL), and enhanced inference.
Key Options
The venture has a variety of vital elements. It incorporates a brand new Rust-built tokenizer for top efficiency. The coaching pipeline employs high quality information equivalent to FineWeb-EDU for pretraining. It additionally employs specialised information equivalent to SmolTalk and GSM8K for post-training fine-tuning. For safety, the mannequin can run code inside a Python sandbox.
The venture works effectively inside your finances. The elemental “speedrun” mannequin is round $100 and trains for 4 hours. You too can develop a extra sturdy mannequin for about $1,000 with roughly 42 hours of coaching.
Efficiency
The efficiency will increase with the coaching time.
- 4 hours: The fast run provides you a easy conversational mannequin. It will possibly compose easy poems or describe ideas equivalent to Rayleigh scattering.
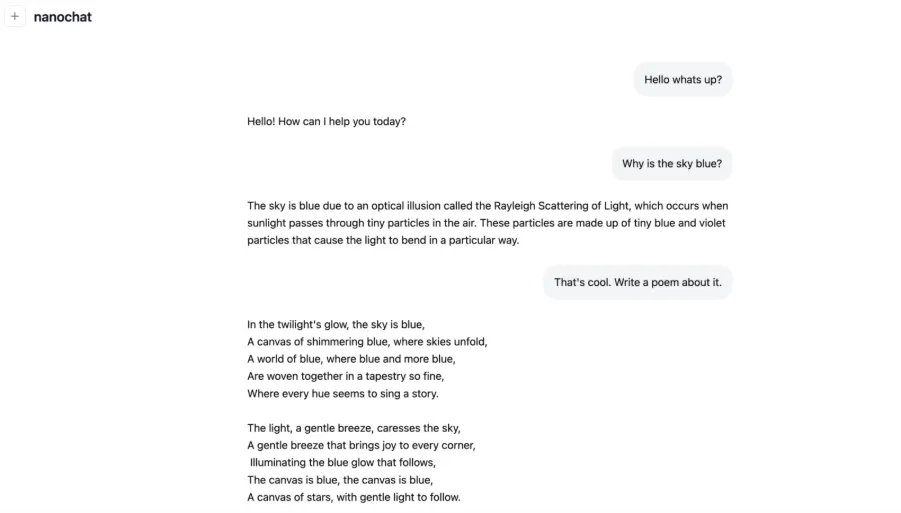
Among the abstract metrics have been produced by the $100 speedrun for 4 hours.
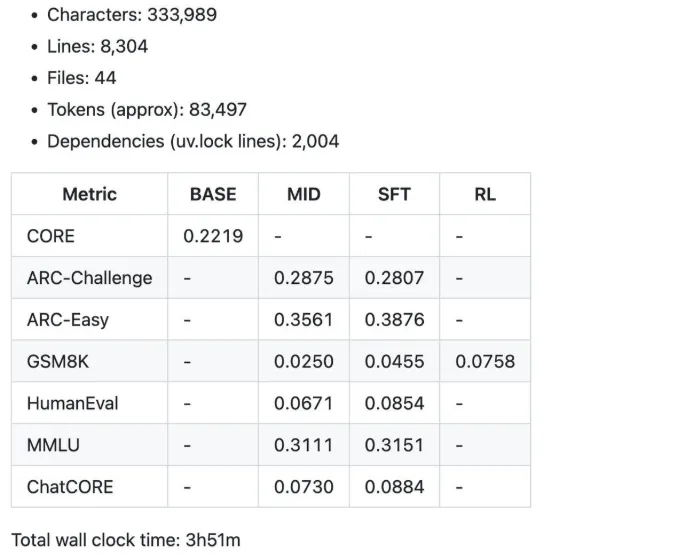
- 12 hours: The mannequin begins to surpass GPT-2 on the CORE benchmark.
- 24 hours: It will get first rate scores, equivalent to 40% on MMLU and 70% on ARC-Simple.
The first academic goal of the nanochat venture is to supply a simple, hackable baseline. This makes it an ideal useful resource for college kids, researchers, and AI hobbyists.
Conditions and Setup
Earlier than you begin, you need to prepared your {hardware} and software program. It’s straightforward to do with the right instruments.
{Hardware} Necessities
The venture is finest dealt with by an 8xH100 GPU node. These can be found on suppliers equivalent to Lambda GPU Cloud for about $24 an hour. You too can use a single GPU with gradient accumulation. This can be a slower technique, however eight occasions slower.
Software program
You’ll require a normal Python surroundings together with PyTorch. The venture depends upon the uv package deal supervisor to handle dependencies. Additionally, you will require Git put in to be able to clone the repository. As an optionally available alternative, chances are you’ll embody Weights & Biases for logging your coaching runs.
Preliminary Steps
Cloning the official repository comes first:
git clone [email protected]:karpathy/nanochat.git Second, turn into the venture listing, i.e, nanochat, and set up the dependencies.
cd nanochat Lastly, create and connect to your cloud GPU occasion to begin coaching.
Information for Coaching Your Personal ChatGPT Clone
What follows is a step-by-step information to coaching your very first mannequin. Paying shut consideration to those steps will yield a working LLM. The official walkthrough within the repository comprises extra info.
Step 1: Atmosphere Preparation
First, boot your 8xH100 node. As soon as up, set up uv package deal supervisor utilizing the provided script. It’s good to have long-running issues inside a display screen session. This makes the coaching proceed even while you disconnect.
# set up uv (if not already put in)
command -v uv &> /dev/null || curl -LsSf https://astral.sh/uv/set up.sh | sh
# create a .venv native digital surroundings (if it would not exist)
[ -d ".venv" ] || uv venv
# set up the repo dependencies
uv sync
# activate venv in order that `python` makes use of the venture's venv as a substitute of system python
supply .venv/bin/activate Step 2: Information and Tokenizer Setup
First, we have to set up Rust/Cargo in order that we will compile our customized Rust tokenizer.
# Set up Rust / Cargo
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
supply "$HOME/.cargo/env"
# Construct the rustbpe Tokenizer
uv run maturin develop --release --manifest-path rustbpe/Cargo.toml The pretraining information is simply the textual content of loads of webpages, and for this half, we’ll use the FineWeb-EDU dataset. However Karpathy recommends utilizing the next model.
https://huggingface.co/datasets/karpathy/fineweb-edu-100b-shuffle
python -m nanochat.dataset -n 240 As soon as downloaded, you practice the Rust tokenizer on a big corpus of textual content. This step is made to be quick by the script. It ought to compress to roughly a 4.8 to 1 compression ratio.
python -m scripts.tok_train --max_chars=2000000000
python -m scripts.tok_eval Step 3: Pretraining
Now, you need to obtain the analysis information bundle. That is the place the take a look at datasets for the mannequin’s efficiency reside.
curl -L -o eval_bundle.zip https://karpathy-public.s3.us-west-2.amazonaws.com/eval_bundle.zip
unzip -q eval_bundle.zip
rm eval_bundle.zip
mv eval_bundle "$HOME/.cache/nanochat" Additionally, setup wandb for seeing good plots throughout coaching. uv already put in wandb for us up above, however you continue to should arrange an account and log in with:
wandb login Now chances are you’ll provoke the principle pretraining script. Execute it with the torchrun command to leverage all eight GPUs. The method trains the mannequin on easy language patterns from the FineWeb-EDU corpus. This stage requires round two to 3 hours for speedrun. This can be a very important a part of the method for coaching a language mannequin.
torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=20 We’re initiating coaching on 8 GPUs utilizing the scripts/base_train.py script. The mannequin is a 20-layer Transformer. Every GPU handles 32 sequences of 2048 tokens per ahead and backward move, giving a complete of 32 × 2048 = 524,288 (≈0.5M) tokens processed per optimization step.
If Weights & Biases (wandb) is configured, you may add the –run=speedrun flag to assign a run title and allow logging.
When coaching begins, you’ll see an output much like the next (simplified right here for readability):
Step 4: Midtraining and SFT
As soon as pretraining, you proceed to midtraining. Midtraining applies the SmolTalk dataset to supply the mannequin with extra conversational energy. After that, you’ll conduct supervised fine-tuning (SFT) on information equivalent to GSM8K. That is what aids the mannequin in studying to execute directions in addition to fixing issues.
We will begin the mid-training as follows: this run solely takes about 8 minutes, quite a bit shorter than pre-training at ~3 hours.
torchrun --standalone --nproc_per_node=8 -m scripts.mid_train After mid-training comes the Finetuning stage. This part includes one other spherical of finetuning on conversational information, however with a concentrate on choosing solely the highest-quality, most well-curated examples. It’s additionally the stage the place safety-oriented changes are made, equivalent to coaching the mannequin on acceptable refusal behaviors for delicate or restricted queries. This once more solely runs for about 7 minutes.
torchrun --standalone --nproc_per_node=8 -m scripts.chat_sft Step 5: Non-compulsory RL
The nanochat open-source LLM additionally has preliminary reinforcement studying assist. You may run a method often known as GRPO on the GSM8K dataset. That is an optionally available course of and will take one other hour. Examine that Karpathy stated RL assist continues to be in its infancy.
torchrun --standalone --nproc_per_node=8 -m scripts.chat_rl Step 6: Inference and UI
With coaching completed, now you can run the inference script. This lets you discuss to your mannequin utilizing an online UI or command-line interface. Attempt working it with some examples like “Why is the sky blue?” to expertise your creation.
python -m scripts.chat_cli (for Command line window) OR
python -m scripts.chat_web. (for Net UI) The chat_web script will serve the Engine utilizing FastAPI. Be certain to entry it appropriately, e.g., on Lambda, use the general public IP of the node you’re on, adopted by the port, so for instance http://209.20.xxx.xxx:8000/, and many others.
Step 7: Evaluate Outcomes
Now, testing it with the online interface on the hyperlink on which the nanochat is hosted.
Lastly, take a look at the report.md within the repository. It has some vital metrics in your mannequin, equivalent to its CORE rating and GSM8K accuracy. The bottom speedrun runs for about $92.40 to place in a bit lower than 4 hours of labor.
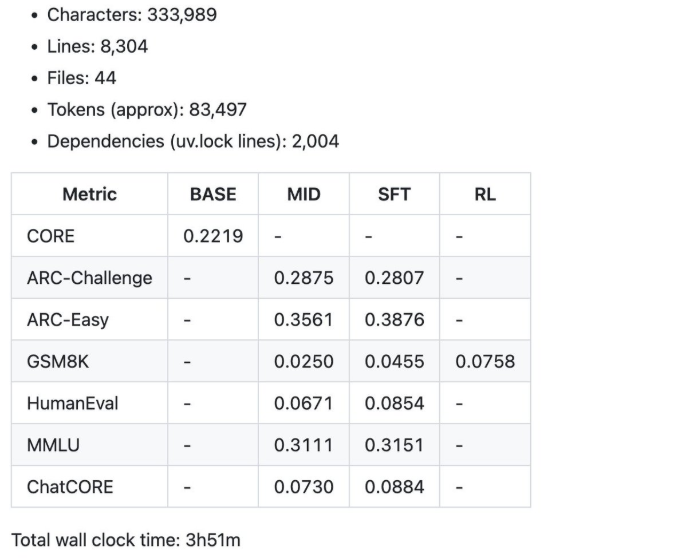
Notice: I’ve taken the code and steps from Andrej Karapathy’s nano chat GitHub. You’ll find full documentation right here. What I showcased above is a less complicated and shorter model.
Customizing and Scaling
The speedrun is a wonderful place to begin. From that time, you may additional customise the mannequin. This is likely one of the most important benefits of Karpathy’s nanochat launch.
Tuning Choices
You may tweak the depth of the mannequin to enhance efficiency. With the --depth=26 flag, say, you step right into a extra highly effective $300 vary. You may also strive utilizing different datasets or altering coaching hyperparameters.
Scaling Up
The repository particulars a $1,000 stage. This entails an prolonged coaching run of roughly 41.6 hours. It yields a mannequin with improved coherence and better benchmark scores. In case you are going through VRAM constraints, try and decrease the --device_batch_size setting.
Personalization Challenges
Others can fine-tune the mannequin on private information. Karpathy advises towards this, as this may find yourself producing “slop.” A greater method to make use of private information is retrieval-augmented technology (RAG) by way of instruments equivalent to NotebookLM.
Conclusion
The nanochat venture allows each researchers and inexperienced persons. It provides an affordable and easy solution to practice a robust open-source LLM. With a restricted finances and an open weekend, you may go from setup to deployment. Use this tutorial to coach your individual ChatGPT, take a look at the nanochat repository, and take part locally discussion board to assist out. Your journey to coach a language mannequin begins right here.
Ceaselessly Requested Questions
A. Nanochat is an open-source PyTorch initiative by Andrej Karpathy. It gives an end-to-end pipeline to coach a ChatGPT-style LLM from scratch cheaply.
A. It prices about $100 to coach a primary mannequin and takes 4 hours. Extra highly effective fashions may be skilled with budgets of $300 to $1,000 with prolonged coaching durations.
A. The recommended configuration is an 8xH100 GPU node, and you may lease this from cloud suppliers. It’s attainable to make use of a single GPU, however will probably be a lot slower.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (in order that they don’t change him simply but). When not optimizing fashions, he’s in all probability optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.