

{kind=link}
The fast deployment of huge language fashions (LLMs) has launched important safety vulnerabilities on account of misconfigurations and insufficient entry controls. This paper presents a scientific strategy to figuring out publicly uncovered LLM servers, specializing in cases working the Ollama framework. Using Shodan, a search engine for internet-connected gadgets, we developed a Python-based software to detect unsecured LLM endpoints. Our research uncovered over 1,100 uncovered Ollama servers, with roughly 20% actively internet hosting fashions prone to unauthorized entry. These findings spotlight the pressing want for safety baselines in LLM deployments and supply a sensible basis for future analysis into LLM risk floor monitoring.
Introduction
The mixing of huge language fashions (LLMs) into various purposes has surged lately, pushed by their superior capabilities in pure language understanding and technology. Broadly adopted platforms resembling ChatGPT, Grok, and DeepSeek have contributed to the mainstream visibility of LLMs, whereas open-source frameworks like Ollama and Hugging Face have considerably lowered the barrier to entry for deploying these fashions in customized environments. This has led to widespread adoption by each organizations and people of a broad vary of duties, together with content material technology, buyer assist, knowledge evaluation, and software program improvement.
Regardless of their rising utility, the tempo of LLM adoption has typically outstripped the event and implementation of acceptable safety practices. Many self-hosted or domestically deployed LLM options are introduced on-line with out sufficient hardening, often exposing endpoints on account of default configurations, weak or absent authentication, and inadequate community isolation. These vulnerabilities aren’t solely a byproduct of poor deployment hygiene however are additionally symptomatic of an ecosystem that has largely prioritized accessibility and efficiency over safety. In consequence, improperly secured LLM cases current an increasing assault floor, opening the door to dangers resembling:
- Unauthorized API Entry — Many ML servers function with out authentication, permitting anybody to submit queries.
- Mannequin Extraction Assaults — Attackers can reconstruct mannequin parameters by querying an uncovered ML server repeatedly.
- Jailbreaking and Content material Abuse — LLMs like GPT-4, LLaMA, and Mistral can by manipulated to generate restricted content material, together with misinformation, malware code, or dangerous outputs.
- Useful resource Hijacking (ML DoS Assaults) — Open AI fashions may be exploited without spending a dime computation, resulting in extreme prices for the host.
- Backdoor Injection and Mannequin Poisoning — Adversaries may exploit unsecured mannequin endpoints to introduce malicious payloads or load untrusted fashions remotely.
This work investigates the prevalence and safety posture of publicly accessible LLM servers, with a give attention to cases using the Ollama framework, which has gained recognition for its ease of use and native deployment capabilities. Whereas Ollama permits versatile experimentation and native mannequin execution, its deployment defaults and documentation don’t explicitly emphasize safety finest practices, making it a compelling goal for evaluation.
To evaluate the real-world implications of those issues, we leverage the Shodan search engine to determine uncovered Ollama servers and consider their safety configurations. Our investigation is guided by three major contributions:
- Growth of a proof-of-concept software, written in Python, to detect uncovered Ollama servers by Shodan queries
- Evaluation of recognized cases consider authentication enforcement, endpoint publicity, and mannequin accessibility
- Suggestions for mitigating widespread vulnerabilities in LLM deployments, with a give attention to sensible safety enhancements
Our findings reveal {that a} important variety of organizations and people expose their LLM infrastructure to the web, typically with out realizing the implications. This creates avenues for misuse, starting from useful resource exploitation to malicious immediate injection and knowledge inference.
Methodology
The proposed system makes use of Shodan, a search engine that indexes internet-connected gadgets, to determine doubtlessly weak AI inference servers. This strategy was chosen with privateness and moral concerns in thoughts, particularly to keep away from the dangers related to immediately scanning distant techniques which will already be uncovered or improperly secured. By counting on Shodan’s present database of listed endpoints, the system circumvents the necessity for lively probing, thereby decreasing the chance of triggering intrusion detection techniques or violating acceptable use insurance policies.
Along with being extra moral, leveraging Shodan additionally supplies a scalable and environment friendly mechanism for figuring out LLM deployments accessible over the general public web. Guide enumeration or brute-force scanning of IP handle ranges could be considerably extra resource-intensive and doubtlessly problematic from each authorized and operational views.
The system operates in two sequential levels. Within the first stage, Shodan is queried to determine publicly accessible Ollama servers primarily based on distinctive community signatures or banners. Within the second stage, every recognized endpoint is programmatically queried to evaluate its safety posture, with a selected give attention to authentication and authorization mechanisms. This consists of evaluating whether or not endpoints require credentials, implement entry management, or expose mannequin metadata and performance with out restriction.
An outline of the system structure is illustrated in Determine 1, which outlines the workflow from endpoint discovery to vulnerability evaluation.
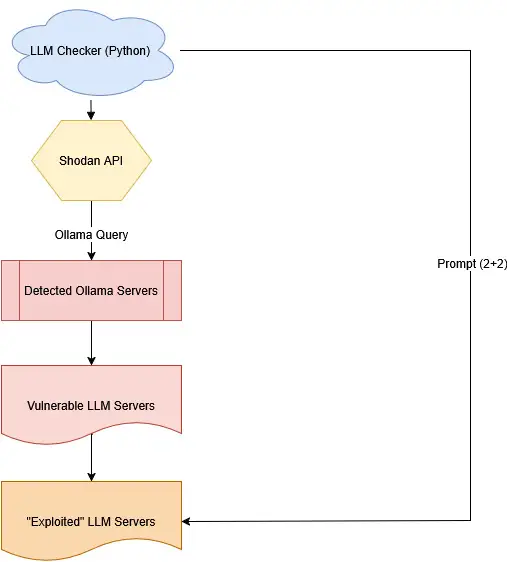
Detecting Uncovered Ollama Servers
Our strategy focuses on figuring out deployments of well-liked LLM internet hosting instruments by scanning for default ports and repair banners related to every implementation. Beneath we offer an inventory of LLM platforms examined and their related default ports, that are used as heuristics for identification:
- Ollama / Mistral / LLaMA fashions — Port 11434
- vLLM — Port 8000
- llama.cpp — Ports 8000, 8080
- LM Studio — Port 1234
- GPT4All — Port 4891
- LangChain — Port 8000
Utilizing the Shodan API, the system retrieves metadata for hosts working on these ports, together with IP addresses, open ports, HTTP headers, and repair banners. To reduce false positives, resembling unrelated purposes utilizing the identical ports, the developed system performs a further filtering step primarily based on banner content material. For instance, Ollama cases are verified utilizing key phrase matching towards the service banner (e.g., port:11434 “Ollama”), which will increase confidence that the endpoint is related to the focused LLM tooling fairly than an unrelated software utilizing the identical port.
Throughout evaluation, we recognized a further signature that enhanced the accuracy of fingerprinting Ollama deployments. Particularly, a major proportion of the found Ollama cases have been discovered to be working the Uvicorn ASGI server, a light-weight, Python-based internet server generally employed for serving asynchronous APIs. In such instances, the HTTP response headers included the sector Server: “uvicorn”, which functioned as a priceless secondary indicator, significantly when the service banner lacked an specific reference to the Ollama platform. Conversely, our analysis additionally signifies that servers working Uvicorn usually tend to host LLM purposes as this Python-based internet server seems to be well-liked amongst software program used for self-hosting LLMs.
This commentary strengthens the resilience of our detection methodology by enabling the inference of Ollama deployments even within the absence of direct product identifiers. Given Uvicorn’s widespread use in Python-based microservice architectures and AI inference backends, its presence, particularly when correlated with recognized Ollama-specific ports (e.g., 11434) considerably will increase the boldness degree {that a} host is serving an LLM-related software. A layered fingerprinting strategy improves the precision of our system and reduces reliance on single-point identifiers which may be obfuscated or omitted.
The banner-based fingerprinting technique attracts from established ideas in community reconnaissance and is a broadly accepted strategy in each educational analysis and penetration testing contexts. In keeping with prior work in internet-wide scanning, service banners and default ports present a dependable mechanism for characterizing software program deployments at scale, albeit with limitations in environments using obfuscation or non-standard configurations.
By combining port-based filtering with banner evaluation and key phrase validation, our system goals to strike a steadiness between recall and precision in figuring out genuinely uncovered LLM servers, thus enabling correct and accountable vulnerability evaluation.

Authorization and Authentication Evaluation
As soon as a doubtlessly weak Ollama server is recognized, we provoke a collection of automated API queries to find out whether or not entry controls are in place and whether or not the server responds deterministically to standardized take a look at inputs. This analysis particularly assesses the presence or absence of authentication enforcement and the mannequin’s responsiveness to benign immediate injections, thereby offering perception into the system’s publicity to unauthorized use. To reduce operational danger and guarantee moral testing requirements, we make use of a minimal, non-invasive immediate construction as follows:
A profitable HTTP 200 response accompanied by the right end result (e.g., “4”) signifies that the server is accepting and executing prompts with out requiring authentication. This represents a high-severity safety concern, because it means that arbitrary, unauthenticated immediate execution is feasible. In such instances, the system is uncovered to a broad vary of assault vectors, together with the deployment and execution of unauthorized fashions, immediate injection assaults, and the deletion or modification of present belongings.
Furthermore, unprotected endpoints could also be subjected to automated fuzzing or adversarial testing utilizing instruments resembling Promptfoo or Garak, that are designed to probe LLMs for surprising conduct or latent vulnerabilities. These instruments, when directed at unsecured cases, can systematically uncover unsafe mannequin responses, immediate leakage, or unintended completions which will compromise the integrity or confidentiality of the system.
Conversely, HTTP standing codes 401 (Unauthorized) or 403 (Forbidden) denote that entry controls are not less than partially enforced, typically by default authentication mechanisms. Whereas such configurations don’t assure full safety, significantly towards brute-force or misconfiguration exploits, they considerably scale back the instant danger of informal or opportunistic exploitation. Nonetheless, even authenticated cases require scrutiny to make sure correct isolation, charge limiting, and audit logging, as a part of a complete safety posture.
Findings
The outcomes from our scans confirmed the preliminary speculation: a major variety of Ollama servers are publicly uncovered and weak to unauthorized immediate injection. Using an automatic scanning software at the side of Shodan, we recognized 1,139 weak Ollama cases. Notably, the invention charge was highest within the preliminary part of scanning, with over 1,000 cases detected throughout the first 10 minutes, highlighting the widespread and largely unmitigated nature of this publicity.
Geospatial evaluation of the recognized servers revealed a focus of vulnerabilities in a number of main areas. As depicted in Determine 3, the vast majority of uncovered servers have been hosted in the USA (36.6%), adopted by China (22.5%) and Germany (8.9%). To guard the integrity and privateness of affected entities, IP addresses have been redacted in all visible documentation of the findings.
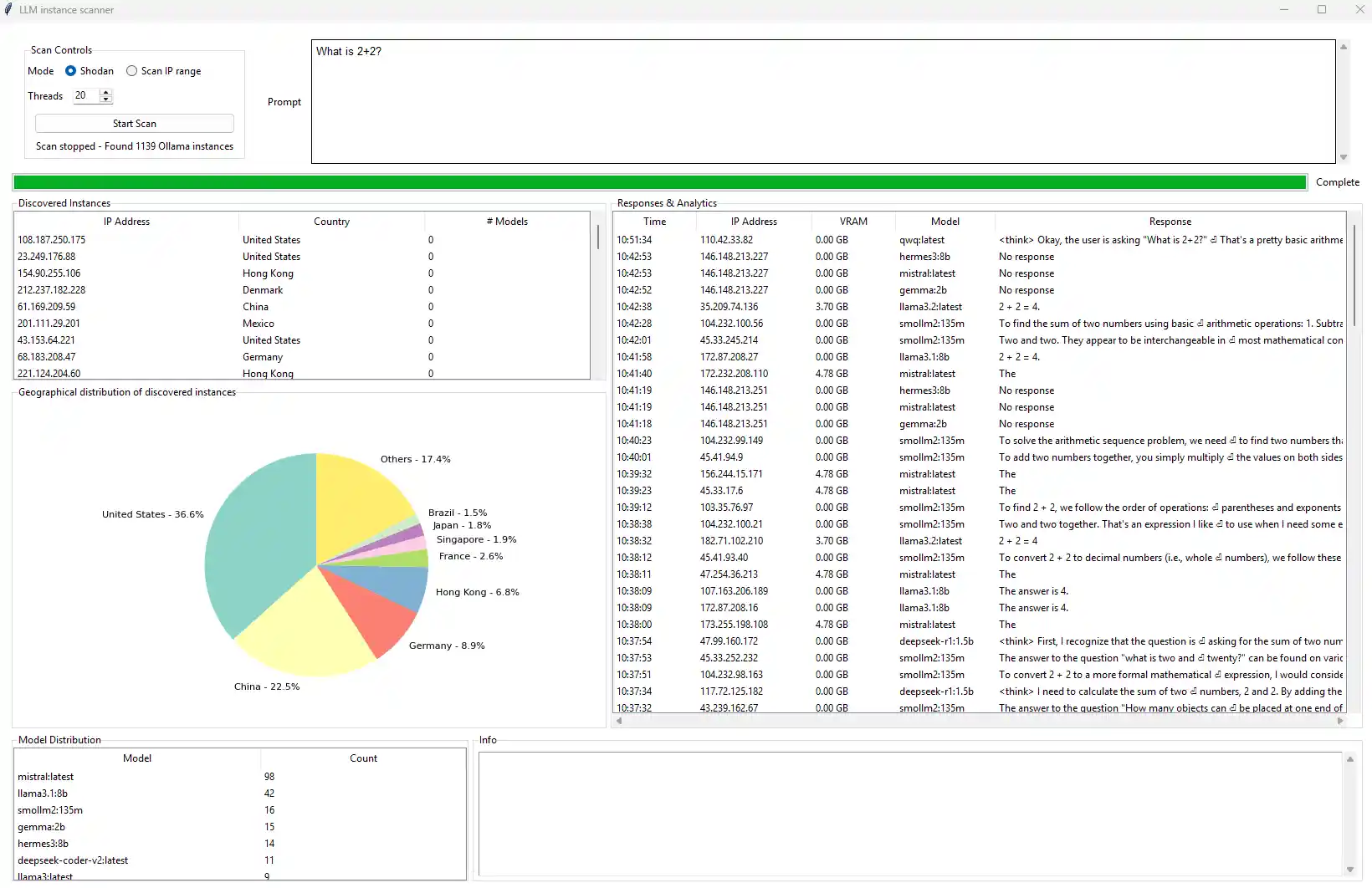
Out of the 1,139 uncovered servers, 214 have been discovered to be actively internet hosting and responding to requests with dwell fashions—accounting for about 18.8% of the entire scanned inhabitants with Mistral and LLaMA representing probably the most often encountered deployments. A overview of the least widespread mannequin names was additionally carried out, revealing what gave the impression to be primarily self-trained or in any other case personalized LLMs. In some cases, the names alone supplied sufficient info to determine the internet hosting celebration. To safeguard their privateness, tha names of those fashions have been excluded from the findings. These interactions affirm the feasibility of prompt-based interplay with out authentication, and thus the danger of exploitation.
Conversely, the remaining 80% of detected servers, whereas reachable through unauthenticated interfaces, didn’t have any fashions instantiated. These “dormant” servers, although not actively serving mannequin responses, stay prone to exploitation through unauthorized mannequin uploads or configuration manipulation. Importantly, their uncovered interfaces may nonetheless be leveraged in assaults involving useful resource exhaustion, denial of service, or lateral motion.
A further commentary was the widespread adoption of OpenAI-compatible API schemas throughout disparate mannequin internet hosting platforms. Among the many found endpoints, 88.89% adhered to the standardized route construction utilized by OpenAI (e.g., v1/chat/completions), enabling simplified interoperability but additionally creating uniformity that could possibly be exploited by automated assault frameworks. This API-level homogeneity facilitates the fast improvement and deployment of malicious tooling able to interacting with a number of LLM suppliers with minimal modification.
These findings showcase a important and systemic vulnerability within the deployment of LLM infrastructure. The convenience with which these servers may be situated, fingerprinted, and interacted with raises pressing issues relating to operational safety, entry management defaults, and the potential for widespread misuse within the absence of strong authentication and mannequin entry restrictions.
Limitations
Whereas the proposed system successfully recognized a considerable variety of uncovered Ollama servers, a number of limitations ought to be acknowledged which will influence the completeness and accuracy of the outcomes.
First, the detection course of is inherently restricted by Shodan’s scanning protection and indexing frequency. Solely servers already found and cataloged by Shodan may be analyzed, that means any hosts outdoors its visibility, on account of firewalls, opt-out insurance policies, or geographical constraints stay undetected.
Secondly, the system depends on Shodan’s fingerprinting accuracy. If Ollama cases are configured with customized headers, reverse proxies, or stripped HTTP metadata, they might not be appropriately categorised by Shodan, resulting in potential false negatives.
Third, the strategy targets default and generally used ports (e.g., 11434), which introduces a bias towards customary configurations. Servers working on non-standard or deliberately obfuscated ports are prone to evade detection totally.
Lastly, the evaluation focuses solely on Ollama deployments and doesn’t prolong to different LLM internet hosting frameworks. Whereas this specialization enhances precision inside a slender scope, it limits generalizability throughout the broader LLM infrastructure panorama.
Mitigation Methods
The widespread publicity of unauthenticated Ollama servers highlights the pressing want for standardized, sensible, and layered mitigation methods geared toward securing LLM infrastructure. Beneath, we suggest a set of technical and procedural defenses, grounded in finest practices and supported by present instruments and frameworks.
Implement Authentication and Entry Management
Probably the most important step in mitigating unauthorized entry is the implementation of strong authentication mechanisms. Ollama cases, and LLM servers usually, ought to by no means be publicly uncovered with out requiring safe API key-based or token-based authentication. Ideally, authentication ought to be tied to role-based entry management (RBAC) techniques to restrict the scope of what customers can do as soon as authenticated.
Community Segmentation and Firewalling
Publicly exposing inference endpoints over the web, significantly on default ports, dramatically will increase the chance of being listed by providers like Shodan. LLM endpoints ought to be deployed behind network-level entry controls, resembling firewalls, VPCs, or reverse proxies, and restricted to trusted IP ranges or VPNs.
Charge Limiting and Abuse Detection
To forestall automated abuse and mannequin probing, inference endpoints ought to implement charge limiting, throttling, and logging mechanisms. This may hinder brute-force assaults, immediate injection makes an attempt, or useful resource hijacking.
Disable Default Ports and Obfuscate Service Banners
Default ports (e.g., 11434 for Ollama) make fingerprinting trivial. To complicate scanning efforts, operators ought to take into account altering default ports and disabling verbose service banners in HTTP responses or headers (e.g., eradicating “uvicorn” or “Ollama” identifiers).
Safe Mannequin Add and Execution Pipelines
Ollama and related instruments assist dynamic mannequin uploads, which, if unsecured, current a vector for mannequin poisoning or backdoor injection. Mannequin add performance ought to be restricted, authenticated, and ideally audited. All fashions ought to be validated towards a hash or verified origin earlier than execution.
Steady Monitoring and Automated Publicity Audits
Operators ought to implement steady monitoring instruments that alert when LLM endpoints turn into publicly accessible, misconfigured, or lack authentication. Scheduled Shodan queries or customized scanners may help detect regressions in deployment safety.
Conclusion
This research reveals a regarding panorama of insecure massive language mannequin deployments, with a selected give attention to Ollama-based servers uncovered to the general public web. Via using Shodan and a purpose-built detection software, we recognized over 1,100 unauthenticated LLM servers, a considerable proportion of which have been actively internet hosting weak fashions. These findings spotlight a widespread neglect of basic safety practices resembling entry management, authentication, and community isolation within the deployment of AI techniques.
The uniform adoption of OpenAI-compatible APIs additional exacerbates the problem, enabling attackers to scale exploit makes an attempt throughout platforms with minimal adaptation. Whereas solely a subset of the uncovered servers have been discovered to be actively serving fashions, the broader danger posed by dormant but accessible endpoints can’t be understated. Such infrastructure stays weak to abuse by unauthorized mannequin execution, immediate injection, and useful resource hijacking. Our work underscores the pressing want for standardized safety baselines, automated auditing instruments, and improved deployment steerage for LLM infrastructure.
Trying forward, future work ought to discover the combination of a number of knowledge sources, together with Censys, ZoomEye, and customized Nmap-based scanners to enhance discovery accuracy and scale back dependency on a single platform. Moreover, incorporating adaptive fingerprinting and lively probing strategies may improve detection capabilities in instances the place servers use obfuscation or non-standard configurations. Increasing the system to determine deployments throughout a wider vary of LLM internet hosting frameworks, resembling Hugging Face, Triton, and vLLM, would additional enhance protection and relevance. Lastly, non-standard port detection and adversarial immediate evaluation supply promising avenues for refining the system’s capability to detect and characterize hidden or evasive LLM deployments in real-world environments.
We’d love to listen to what you assume! Ask a query and keep linked with Cisco Safety on social media.
Cisco Safety Social Media
Share: