

{kind=link}

10 Python One-Liners for Calculating Mannequin Function Significance
Picture by Editor
Understanding machine studying fashions is an important side of constructing reliable AI methods. The understandability of such fashions rests on two fundamental properties: explainability and interpretability. The previous refers to how properly we will describe a mannequin’s “innards” (i.e. the way it operates and appears internally), whereas the latter issues how simply people can perceive the captured relationships between enter options and predicted outputs. As we will see, the distinction between them is delicate, however there’s a highly effective bridge connecting each: function significance.
This text unveils 10 easy however efficient Python one-liners to calculate mannequin function significance from completely different views — serving to you perceive not solely how your machine studying mannequin behaves, but in addition why it made the prediction(s) it did.
1. Constructed-in Function Significance in Resolution Tree-based Fashions
Tree-based fashions like random forests and XGBoost ensembles mean you can simply get hold of an inventory of feature-importance weights utilizing an attribute like:
|
importances = mannequin.feature_importances_ |
Notice that mannequin ought to comprise a skilled mannequin a priori. The result’s an array containing the significance of options, however if you need a extra self-explanatory model, this code enhances the earlier one-liner by incorporating the function names for a dataset like iris, multi function line.
|
print(“Function importances:”, listing(zip(iris.feature_names, mannequin.feature_importances_))) |
2. Coefficients in Linear Fashions
Less complicated linear fashions like linear regression and logistic regression additionally expose function weights through discovered coefficients. It is a solution to get hold of the primary of them immediately and neatly (take away the positional index to acquire all weights):
|
importances = abs(mannequin.coef_[0]) |
3. Sorting Options by Significance
Just like the improved model of #1 above, this convenient one-liner can be utilized to rank options by their significance values in descending order: a superb glimpse of which options are the strongest or most influential contributors to mannequin predictions.
|
sorted_features = sorted(zip(options, importances), key=lambda x: x[1], reverse=True) |
4. Mannequin-Agnostic Permutation Significance
Permutation significance is a further strategy to measure a function’s significance — particularly, by shuffling its values and analyzing how a metric used to measure the mannequin’s efficiency (e.g. accuracy or error) decreases. Accordingly, this model-agnostic one-liner from scikit-learn is used to measure efficiency drops on account of randomly shuffling a function’s values.
|
from sklearn.inspection import permutation_importance end result = permutation_importance(mannequin, X, y).importances_mean |
5. Imply Lack of Accuracy in Cross-Validation Permutations
That is an environment friendly one-liner to check permutations within the context of cross-validation processes — analyzing how shuffling every function impacts mannequin efficiency throughout Okay folds.
|
import numpy as np from sklearn.model_selection import cross_val_score importances = [(cross_val_score(model, X.assign(**{f: np.random.permutation(X[f])}), y).imply()) for f in X.columns] |
6. Permutation Significance Visualizations with Eli5
Eli5 — an abbreviated type of “Clarify like I’m 5 (years outdated)” — is, within the context of Python machine studying, a library for crystal-clear explainability. It gives a mildly visually interactive HTML view of function importances, making it significantly helpful for notebooks and appropriate for skilled linear or tree fashions alike.
|
import eli5 eli5.show_weights(mannequin, feature_names=options) |
7. International SHAP Function Significance
SHAP is a well-liked and highly effective library to get deeper into explaining mannequin function significance. It may be used to calculate imply absolute SHAP values (feature-importance indicators in SHAP) for every function — all below a model-agnostic, theoretically grounded measurement strategy.
|
import numpy as np import shap shap_values = shap.TreeExplainer(mannequin).shap_values(X) importances = np.abs(shap_values).imply(0) |
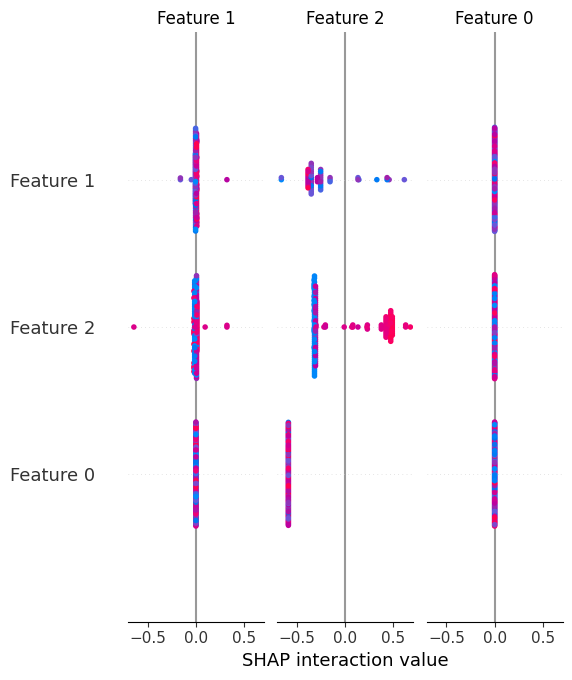
8. Abstract Plot of SHAP Values
In contrast to international SHAP function importances, the abstract plot gives not solely the worldwide significance of options in a mannequin, but in addition their instructions, visually serving to perceive how function values push predictions upward or downward.
|
shap.summary_plot(shap_values, X) |
Let’s take a look at a visible instance of end result obtained:
9. Single-Prediction Explanations with SHAP
One significantly engaging side of SHAP is that it helps clarify not solely the general mannequin conduct and have importances, but in addition how options particularly affect a single prediction. In different phrases, we will reveal or decompose a person prediction, explaining how and why the mannequin yielded that particular output.
|
shap.force_plot(shap.TreeExplainer(mannequin).expected_value, shap_values[0], X.iloc[0]) |
10. Mannequin-Agnostic Function Significance with LIME
LIME is another library to SHAP that generates native surrogate explanations. Moderately than utilizing one or the opposite, these two libraries complement one another properly, serving to higher approximate function significance round particular person predictions. This instance does so for a beforehand skilled logistic regression mannequin.
|
from lime.lime_tabular import LimeTabularExplainer exp = LimeTabularExplainer(X.values, feature_names=options).explain_instance(X.iloc[0], mannequin.predict_proba) |
Wrapping Up
This text unveiled 10 efficient Python one-liners to assist higher perceive, clarify, and interpret machine studying fashions with a concentrate on function significance. Comprehending how your mannequin works from the within is now not a mysterious black field with the help of these instruments.